
Maison >base de données >tutoriel mysql >N'oubliez pas de partager un événement de requête lent causé par une erreur de jugement de l'optimiseur MySQL en ligne
N'oubliez pas de partager un événement de requête lent causé par une erreur de jugement de l'optimiseur MySQL en ligne

- 黄舟original
- 2017-03-06 13:42:571070parcourir
Cet article présente principalement les informations pertinentes et la solution finale d'un événement de requête lent causé par une erreur de jugement de l'optimiseur mysql en ligne. J'aimerais le partager avec vous, en espérant vous donner un peu d'inspiration.
Avant-propos :
J'ai reçu des requêtes lentes et des alarmes d'expiration de demande, et j'ai analysé les exceptions des requêtes MySQL via des métriques. J'ai vu beaucoup de requêtes lentes en utilisant cli -> show proceslist. Ce SQL n'existait pas auparavant, mais ce problème est apparu plus tard en raison de l'augmentation du volume de données. Bien que la table des flux puisse atteindre 100 millions, étant donné que les informations sur le flux de flux ont les caractéristiques d'une chaleur récente, les E/S fréquentes ne sont pas causées par l'inefficacité de innodb_buffer_pool_size. Plus tard, après avoir expliqué plus en détail l'analyse du plan d'exécution, la raison a été trouvée. L'optimiseur de requêtes MySQL a choisi un index qu'il jugeait efficace.
L'optimiseur de requêtes MySQL est fiable dans la plupart des cas ! Mais lorsque votre langage SQL contient plusieurs index, il faut faire attention, le résultat final est souvent un peu hésitant. Étant donné que MySQL ne peut utiliser qu'un seul index pour le même SQL, lequel dois-je choisir ? Lorsque la quantité de données est faible, l'optimiseur MySQL publiera l'index de clé primaire et donnera la priorité à l'index et à l'unique. Lorsque vous atteignez un niveau de données, et parce que votre opération de requête est terminée, l'optimiseur de requêtes MySQL est susceptible d'utiliser la clé primaire !
N'oubliez pas une phrase, l'optimisation des requêtes MySQL est basée sur des considérations de coût de récupération, et non sur des considérations de coût en temps. L'optimiseur calcule le coût en fonction de l'état des données existantes, plutôt que d'exécuter réellement SQL
Par conséquent, l'optimiseur MySQL ne peut pas obtenir de résultats d'optimisation à chaque fois. Il ne peut pas estimer avec précision le coût. Si vous souhaitez obtenir avec précision le coût de fonctionnement de chaque index, vous devez l'exécuter une fois pour le savoir. Par conséquent, l'analyse des coûts n'est qu'une estimation. Puisqu'il s'agit d'une estimation, il y a une erreur de jugement. .
Le tableau dont nous parlons ici est le tableau des flux d'informations sur les flux. Nous savons que le tableau des flux d'informations sur les flux est non seulement consulté fréquemment, mais contient également une grande quantité de données. Mais la structure des données de cette table est très simple, et l'index est également simple. Il n'y a que deux index au total, l'un est l'index de clé primaire et l'autre est l'index de clé unique.
Comme suit, la taille de cette table a atteint 100 millions de niveaux. Parce qu'il y a suffisamment de caches, et pour diverses raisons, nous n'avons pas le temps de partitionner la base de données et les tables.
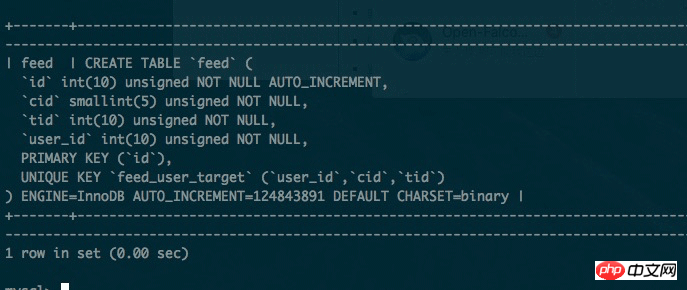
Le problème est le suivant: lorsque la magnitude des données est inférieure à 100 millions, l'optimiseur MySQL choisit d'utiliser l'index. Lorsque la magnitude des données dépasse 100 millions, MySQL. requête L'optimiseur choisit d'utiliser l'index de clé primaire. Le problème que cela entraîne est que la vitesse des requêtes est trop lente.
C'est la situation normale :
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
partitions: NULL
type: range
possible_keys: PRIMARY,feed_user_target
key: feed_user_target
key_len: 6
ref: NULL
rows: 18
filtered: 50.00
Extra: Using where; Using index; Using filesort
1 row in set, 1 warning (0.00 sec)
La même instruction SQL, après que le volume de données a changé de manière significative, optimisation des requêtes MySQL. le choix des index du serveur a également changé.
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
type: range
possible_keys: PRIMARY,feed_user_target
key: PRIMARY
key_len: 4
ref: NULL
rows: 11873197
Extra: Using where
1 row in set (0.00 sec)
Ensuite, la solution consiste à utiliser l'index forcé pour forcer l'optimiseur de requêtes à utiliser l'index que nous avons donné. Il s'agit d'un environnement de développement Python. Les ORM Python courants ont des paramètres d'index de force, d'index d'ignorance et d'index d'utilisateur.
explain SELECT * FROM `feed` force index (feed_user_target) WHERE user_id IN (116537309,116709093,116709377) ...
Alors comment éviter ce problème ? En raison de l'augmentation des données, l'optimiseur mysql choisit un index inefficace ?
J'ai demandé conseil aux DBA de plusieurs usines sur ce problème, et les réponses que j'ai obtenues étaient les mêmes que notre méthode. Le problème ne peut être découvert que via des requêtes lentes ultérieures, puis en spécifiant un index forcé dans l'instruction SQL pour résoudre le problème d'index. De plus, ce type de problèmes sera évité dès les premiers stades de la mise en ligne du système, mais souvent les développeurs commerciaux coopéreront avec le travail de révision du DBA au début, mais plus tard, afin d'éviter des ennuis, ou ils Je pense qu'il n'y a pas de problème, ils provoquent des accidents de requêtes MySQL.
Je connais moi-même peu les règles de sélection d'index de l'optimiseur MySQL, et je prévois de passer du temps à étudier les règles plus tard
Ce qui précède est le partage d'un événement de requête lent causé par une erreur d'appréciation de l'optimiseur MySQL en ligne Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !