
Maison >développement back-end >tutoriel php >La voie vers la croissance de l'architecture système back-end de News APP - Explication graphique et textuelle détaillée de la conception de l'architecture à haute disponibilité
La voie vers la croissance de l'architecture système back-end de News APP - Explication graphique et textuelle détaillée de la conception de l'architecture à haute disponibilité

- 黄舟original
- 2017-03-06 09:37:475615parcourir
Veuillez indiquer la source lors de la réimpression : Actualités Chemin de croissance de l'architecture du système back-end de l'APP - Conception de l'architecture à haute disponibilité
1. Entrer en Terre Sainte pour la première fois
2. Bâtiment des fondations : reconstruction complète
3. Élixir d'or : montez sur le piège. . Et c'est un gros piège
4. Yuanying : Face aux défis, le trafic arrive
5. Hors du corps : ajustement et optimisation de l'architecture du serveur
6. Surmonter la tribulation : plateforme de gouvernance des services
7. Mahayana : haute disponibilité du serveur
8. Ascension : Haute disponibilité du client-[2017 HTTPS HTTP-DNS]
1. Entrer en Terre Sainte pour la première fois
En raison des modalités de travail, certains seniors du backend d'origine de l'APP ont été transférés vers d'autres départements commerciaux. Ils ont commencé à prendre en charge le travail du backend client à la fin de 2015. Entrer en Terre Sainte pour la première fois, c'était comme entrer au purgatoire.
À cette époque, comme il y avait encore beaucoup de travail de développement commercial à accomplir qui nécessitait le soutien continu de mes amis, je n'avais pas d'autre choix que de me lancer seul dans le développement back-end d'APP.
Du développement commercial de contenu, avec lequel j'étais à l'aise, au développement d'interfaces back-end APP, je ne connais toujours pas beaucoup de connaissances professionnelles sur APP, je ne peux que consulter et apprendre de mes camarades de classe. En même temps, je tiens à remercier mes camarades de classe pour leur aide. Malgré diverses difficultés, l'entreprise continuera à progresser et les itérations de versions sont toujours en cours.
De cette façon, je codais et corrigeais des bugs chaque jour tout en répondant aux différents besoins de plus d'une douzaine de belles product girls.
L'ancienne API a été développée début 2012. Fin 2015, elle avait été manipulée par quatre groupes de personnes en près de quatre ans. Vous pouvez imaginer combien d'embûches il y avait à se lever au milieu de la nuit. pour corriger les bugs en ligne.
Dans le même temps, les problèmes de performances de l'ancienne API n'étaient pas optimistes. Le temps de réponse de l'interface était mesuré en secondes. L'échelle commerciale était encore petite et les développeurs d'origine n'accordaient pas une attention particulière à l'architecture et à l'optimisation des services. Comme le nombre d'utilisateurs augmente rapidement, une fois PUSH lancé, le service sera indisponible et nous n'aurons d'autre choix que de le réaliser. De cette façon, tout en supportant des itérations intenses de versions, nous avons marché et rempli les fosses. Bien sûr, nous avons également creusé les fosses en silence, ce qui a duré plus d'un mois.
Après avoir pleinement compris l'intégralité du code de l'ancienne API, j'ai découvert qu'en quatre ans, des dizaines de versions de l'APP avaient été publiées. L'excellent code original écrit par les maîtres et les seniors avait été modifié au point de devenir méconnaissable par plusieurs vagues de personnes en quatre ans. Cela viole sérieusement l'intention initiale de la conception. Le code API est compatible avec tous les codes de version, et il n'y a pas de séparation entre les versions. Il y a plus de dix IF ELSE dans un seul fichier, et il ne peut plus être étendu. a déclaré qu'un seul cheveu peut affecter tout le corps et qu'il suffit d'ajuster quelques lignes de code. Cela peut entraîner l'indisponibilité du service global de toutes les versions. S'il continue à être maintenu, cela ne peut durer qu'un an et demi ou plus. Encore moins. Cependant, plus le délai est long, plus le code des affaires sera chaotique et il sera alors confronté à un état plus passif.
2. Construction des fondations : reconstruction de l'interface
Si vous ne changez pas, cela ne durera pas longtemps ! Nous ne pouvons que nous décider et reconstruire complètement !
Cependant, le développement commercial et l'itération des versions ne peuvent pas s'arrêter.Je ne peux transférer que deux camarades de classe du développement commercial du contenu d'origine pour continuer à soutenir le développement de l'ancienne API.En même temps, j'ai commencé à étudier la conception de la nouvelle architecture d'interface.
En raison du manque d'expérience et de compétences limitées dans le développement d'applications, j'ai commencé à trouver un vide dans la reconstruction d'interface. Je suis resté éveillé tard et j'ai écrit plusieurs ensembles de frameworks pendant deux semaines consécutives, j'ai discuté avec mes camarades de classe pendant la journée et j'ai trouvé divers problèmes et problèmes. les renversa un à un.
Je n'avais d'autre choix que de rechercher diverses informations, d'apprendre de l'expérience des principales applications Internet et de rendre visite à des professeurs célèbres en même temps [Merci à : @青哥, @雪大夫, @京京, @强哥 @太哥et amis du côté APP et WAP], grâce à beaucoup d'apprentissage, j'ai lentement développé un plan global pour l'ensemble de l'idée de construction de la nouvelle architecture d'interface, et j'ai l'impression d'avoir vu le jour.
Après une semaine de travail jour et nuit, j'ai dans un premier temps terminé la structure globale du cadre, je travaille sans arrêt et n'ose pas m'arrêter, alors commençons à amener mes amis au travail !
Bien que nous ayons une idée générale de la conception globale, la reconstruction de l'interface est également confrontée à de gros problèmes et nécessite le soutien total des étudiants en APP, produits et statistiques pour procéder.
La nouvelle interface est complètement différente de l'ancienne interface en termes de méthode d'appel et de structure de sortie de données, ce qui nécessite de nombreuses modifications du code de l'APP [Merci à @Huihui @明明 pour votre soutien et votre coopération]
Bien sûr, les statistiques sont également confrontées au même problème. Toutes les interfaces ont changé, c'est-à-dire que toutes les règles statistiques d'origine doivent être modifiées. En même temps, je tiens également à remercier [@婵女@statistics Department @product classmates]. pour leur forte coopération. Sans le soutien des deux extrémités, des produits et des statistiques, la progression des travaux de reconstruction de l'interface serait impossible. Dans le même temps, je voudrais remercier tous les dirigeants pour leur ferme soutien afin de garantir que les travaux de reconstruction se déroulent comme prévu.
La nouvelle interface est principalement conçue sous les aspects suivants :
1.
1>, Ajoutez une vérification de signature aux requêtes d'interface, établissez un mécanisme de requête de cryptage d'interface, générez un identifiant unique pour chaque adresse de requête et utilisez le cryptage bidirectionnel sur le serveur et le client pour éviter efficacement le brossage d'interface malveillant. 2>, système d'enregistrement de tous les paramètres commerciaux, gestion unifiée de la sécurité2, évolutivité
Cohésion élevée et faible couplage, séparation forcée des versions, développement à plat des versions d'APP, tout en améliorant la réutilisabilité du code, les petites versions suivent le système d'héritage.3. Gestion des ressources
Système d'enregistrement des services, entrée et sortie unifiées, toutes les interfaces doivent être enregistrées auprès du système pour garantir un développement durable. Fournir une garantie pour la surveillance ultérieure et la planification du déclassement. 4. Système unifié de planification et d'allocation de cacheLa nouvelle interface a été lancée comme prévu avec la sortie de la version 5.0. Je pensais que tout irait bien, mais qui aurait cru qu'un gros gouffre m'attendait silencieusement devant.
L'APP dispose d'une fonction PUSH. Chaque fois qu'un PUSH est émis, un grand nombre d'utilisateurs seront instantanément rappelés pour visiter l'APP. Chaque fois que la nouvelle interface envoie du PUSH, le serveur raccroche, ce qui est tragique.
Manifestation du défaut :
1. php-fpm est bloqué et l'état général du serveur est normal . 2. nginx n'est pas en panne et le service est normal. 3. Redémarrez php-fpm Le service sera normal pendant un moment, mais mourra à nouveau après quelques secondes. 4. L'interface répond lentement, ou expire, et l'application s'actualise sans contenuConjectures de dépannage
Au début, je doutais des questions suivantes, 1. MC a un problème 2. MYSQL est lent 3. Grand volume de demandes 4. Certaines requêtes sont d'anciennes interfaces du proxy, ce qui entraînera un doublement des requêtes 5. Problèmes de réseau 6. Certaines interfaces dépendantes sont lentes, ce qui ralentit les services Cependant, en raison du manque de registres, aucune base n’a été trouvée.Traçage des problèmes :
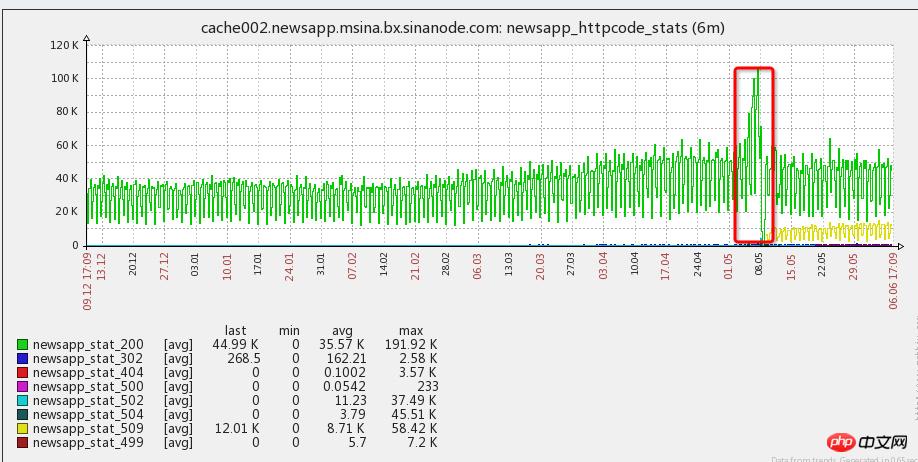
1. Lors de la poussée, un grand nombre d'utilisateurs de l'APP seront rappelés. Lorsque le client est ouvert en même temps, le nombre est 3 à 5 fois supérieur aux heures habituelles (comme le montre la figure (pointes du matin et du soir). sera superposé))
2. Lorsque le client ouvre PUSH, c'est un démarrage à froid. Pour attirer les utilisateurs, de nombreuses ressources d'interface seront appelées, et au début du lancement de la nouvelle API, il n'y avait pas suffisamment de communication avec les étudiants du côté de l'APP, ce qui entraînait des demandes instantanées pour un grand nombre d'interfaces, y compris de nombreux centres d'intérêt en temps réel, publicités, etc. qui ne pouvaient pas être mises en cache et un grand nombre d'interfaces back-end, et MYSQL et d'autres ressources, ce qui entraîne beaucoup d'attente.
3. Le délai d'expiration des ressources backend des requêtes d'interface est trop long et les requêtes d'interface lentes ne sont pas libérées à temps, ce qui entraîne un grand nombre de requêtes d'interface en attente dans la file d'attente
4. l'échelle augmente et l'échelle des utilisateurs de l'APP est la même qu'au début de l'année. Par rapport au doublement du nombre, le travail s'est concentré sur la reconstruction du code, mais les ressources du serveur ont été ignorées et il n'y a pas eu de nouvelles machines , ce qui est aussi une raison de cet échec. [Remarque : l'investissement matériel est en fait l'investissement le moins coûteux]
Puis, et puis il est mort. . .
Problème résolu :
1. Optimisez le cache de la couche NGINX. Le contenu qui peut être mis en cache [tel que le texte] est mis en cache dans la couche NGINX pour réduire la pression back-end
2. telles que les statistiques] ], NGINX renvoie directement sans utiliser PHP, réduisant ainsi la pression sur PHP-FPM
3 Réorganisez les ressources d'interface back-end demandées, hiérarchisez-les en fonction de leur importance commerciale et contrôlez strictement le délai d'attente.
4. Ajoutez de nouveaux équipements et recalculez et configurez les ressources du serveur en fonction de l'échelle des utilisateurs
5. Enregistrez les journaux d'appels de ressources, surveillez les ressources dépendantes et trouvez le fournisseur pour résoudre les problèmes à temps en cas de problème de ressources
6. Ajustez la structure du cache MC pour améliorer l'utilisation du cache
7. Communiquer pleinement avec le client pour trier soigneusement l'ordre et la fréquence des demandes d'interface par l'APP afin d'améliorer l'utilisation efficace de l'interface.
Grâce à cette série de mesures d'amélioration, l'effet est encore assez évident Les avantages en termes de performances de la nouvelle API par rapport à l'ancienne API sont les suivants. :
Ancienne : les requêtes de moins de 100 ms représentent 55 %
 Ancien temps de réponse de l'API
Ancien temps de réponse de l'API
Nouveau : Plus de 93 % du temps de réponse est inférieur à 100 ms
 Nouveau temps de réponse de l'API
Nouveau temps de réponse de l'API
Résumé du problème :
Les causes profondes sont principalement les suivantes, 1. Réponse insuffisante, 2. Manque de communication répétée, 3. Robustesse insuffisante, 4. Caractéristiques PUSH
1>, réponse inadéquate
Le nombre d'utilisateurs a plus que doublé depuis le début de l'année, mais cela n'a pas réussi à attirer suffisamment d'attention. Les progrès de la reconstruction de l'interface étaient encore un peu lents, ne laissant pas suffisamment de temps pour l'optimisation et la réflexion. champ de bataille et n'a pas ajouté de ressources d'équipement de serveur en temps opportun, ce qui a conduit à un gros piège.
2>, manque de communication
Je n'entretenais pas une communication suffisante avec mes camarades de classe du côté APP et du service d'exploitation et de maintenance, et je ne me souciais que de ce qui se passait à mes pieds. Assurez-vous de maintenir une communication et une intégration suffisantes avec le terminal et les étudiants en exploitation et maintenance. Selon les conditions de ressources existantes [matériel, logiciels, ressources dépendantes, etc.], le calendrier et la fréquence des diverses demandes de ressources sont convenus en détail, et les demandes d'interface d'application non principale sont retardées de manière appropriée pour garantir que l'activité principale est disponible et utiliser pleinement les ressources du service.
Remarque : Il est particulièrement important de maintenir une bonne communication avec les camarades de classe Duanshang. Pendant le développement, les camarades de classe demandent des interfaces en fonction des besoins de logique métier de l'APP. Si vous demandez trop d'interfaces, cela équivaudra à lancer un grand nombre d'interfaces par votre propre application. Attaques Ddos sur votre propre serveur, ce qui est très grave. .
3>, robustesse insuffisante
Une dépendance excessive à l'égard d'interfaces tierces fiables, des paramètres de délai d'attente déraisonnables pour les interfaces dépendantes, une utilisation insuffisante du cache, l'absence de sauvegarde après sinistre et des problèmes avec les ressources dépendantes ne peuvent que conduire à la mort.
Remarque : Principe de méfiance, ne faites confiance à aucune ressource dépendante, préparez-vous à ce que les interfaces dépendantes raccrochent à tout moment, assurez-vous d'avoir mis en place des mesures de reprise après sinistre, définissez un délai d'attente strict et abandonnez si vous le devez. . Élaborez une bonne stratégie de dégradation des services. [Référence : 1. Rétrograder l'entreprise, ajouter du cache pour réduire la fréquence de mise à jour, 2. Assurer l'activité principale, éliminer les activités inutiles, 3. Rétrograder l'utilisateur, abandonner certains utilisateurs et protéger les utilisateurs de haute qualité]. Enregistrer les journaux Les journaux sont les yeux du système. Même si l'enregistrement des journaux consomme une partie des performances du système, les journaux doivent être enregistrés une fois qu'il y a un problème avec le système, le problème peut être rapidement localisé et résolu. les journaux.
4>, trafic important soudain
PUSH et des tiers génèrent instantanément d'énormes quantités de trafic, ce qui est insupportable pour le système et manque de mesures efficaces de disjoncteur, de limitation de courant et d'autoprotection.
Résumé : J'ai également beaucoup appris grâce à cette question et acquis une compréhension plus approfondie de l'architecture globale du système. En même temps, j'ai aussi appris certaines vérités. Certaines choses ne sont pas considérées comme acquises et viennent naturellement. Vous devez faire des préparatifs complets et détaillés avant de faire quoi que ce soit. La refactorisation ne consiste pas seulement à réécrire le code. Elle nécessite une compréhension et une connaissance complètes de l'ensemble des ressources du système en amont et en aval, ainsi qu'une préparation complète.
4. Nascent Soul : Relever les défis
J'ai hâte, j'attends avec impatience, le trafic arrive, les JO approchent !
BOSS frère Tao a dit : Si les Jeux olympiques ne se passent pas mal, j'offrirai aux étudiants un grand repas ! Si quelque chose ne va pas aux Jeux olympiques, offrez un festin à frère Tao ! Il ne doit donc y avoir aucun problème avec la fête !
Nous étions en état de préparation avant les Jeux olympiques et avons effectué de nombreux travaux d'optimisation pour nous assurer que nous puissions parfaitement survivre au pic de trafic olympique.
1. Toutes les ressources dépendantes ont été soigneusement triées et les interfaces commerciales clés ont été soigneusement surveillées
2. Déployez le module de reporting des journaux côté APP pour signaler les journaux anormaux en temps réel pour la surveillance
3. Mettez à niveau et développez le cluster MC et optimisez et gérez uniformément le cache système
4. Lancer une stratégie de disjoncteur commercial et de déclassement à plusieurs niveaux
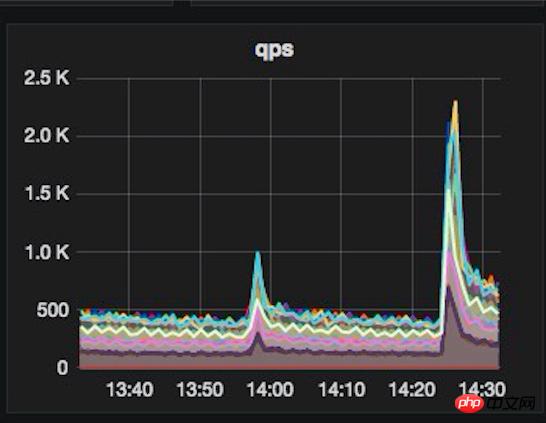
Mais les Jeux olympiques approchent vraiment et le système est encore confronté à un grand test. Au début des Jeux olympiques, afin de garantir que tous les indicateurs du système fonctionnent normalement sans aucun problème, nous avons fait en sorte que des ingénieurs soient de service dans l'entreprise. 24 heures sur 24. PUSH, la première médaille d'or olympique, a répondu aux attentes et a apporté un succès instantané avec un trafic plus de 5 fois supérieur à celui d'habitude, les diverses ressources ont été limitées et le serveur a commencé à fonctionner à pleine capacité. Nos préparatifs précédents sont entrés en jeu à ce moment-là. L'ingénieur de service a toujours prêté attention au grand écran de surveillance, a ajusté les paramètres du système à tout moment en fonction des données de surveillance et de l'état de charge du serveur, et en même temps a réchauffé diverses données dans avance et a réussi la première médaille d'or olympique ! Après la première médaille d'or, j'ai observé pendant les Jeux olympiques que le trafic apporté par les autres épreuves médaillées d'or n'était pas trop important par rapport à la première médaille d'or. Je pensais naïvement que tout le pic de trafic olympique avait été franchi en toute sécurité. [La première image de surveillance anormale de l'or est la suivante]
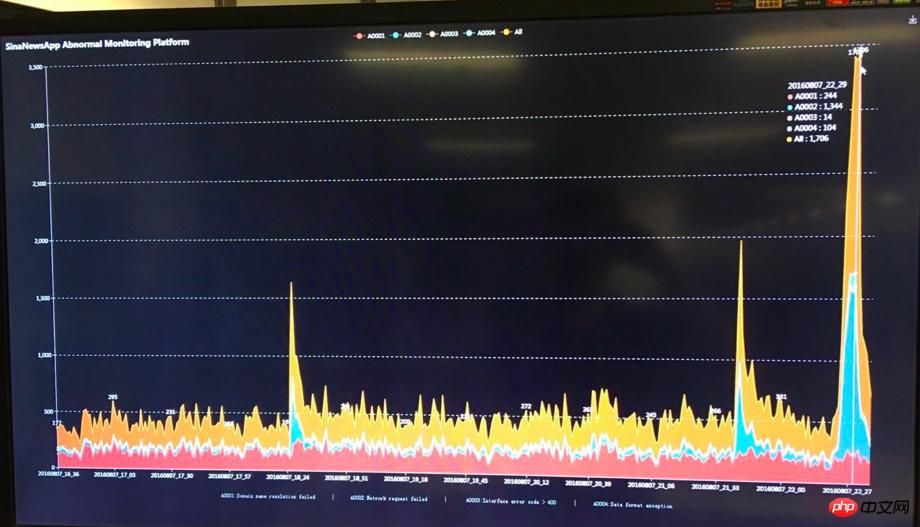
Mais [Dieu travaille pour le bien. . 】L'incident du bébé frappe soudainement et chevauche les Jeux olympiques ! Le trafic généré par PUSH le premier jour de l'incident du bébé a largement dépassé le trafic maximal du premier or. Avec le fort soutien de nombreux utilisateurs de Bagua, notre système a finalement subi le plus gros test de notre vie. Le serveur fonctionnait à pleine charge. , et l'accès à l'APP a commencé à répondre instantanément à PUSH. Dans les cas lents, le taux d'erreur d'affichage du temps de surveillance en temps réel commence également à augmenter.
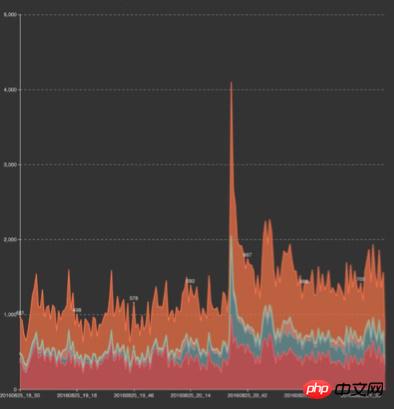 Événement bébé PUSH et trafic superposé Jeux Olympiques
Événement bébé PUSH et trafic superposé Jeux Olympiques
Nous avons immédiatement activé un plan d'urgence pour protéger le système contre les surcharges et rétrograder les services par ordre d'importance [comprenant généralement : réduire la fréquence de mise à jour, prolonger la durée du cache et désactiver] pour protéger la disponibilité globale du système contre toute affectation et garantir que le Le système peut passer en douceur le pic de trafic. Une fois la rétrogradation activée manuellement, le système commence à libérer rapidement une grande quantité de ressources, la charge du système commence à diminuer régulièrement et le temps de réponse côté utilisateur revient à des niveaux normaux. Une fois le PUSH passé [le pic dure généralement environ 3 minutes], annulez manuellement le déclassement.
Bien que l'incident du bébé ait soudainement éclaté pendant les Jeux olympiques, nous avons réussi à nous en sortir sans problème, il n'y a eu aucun problème avec le service global et les données commerciales globales de l'APP se sont également grandement améliorées avec ces deux incidents.
BOSS a également invité les étudiants à se régaler et à passer un bon moment !
Résumé : 1. Le système de surveillance doit être plus détaillé et une surveillance des ressources doit être ajoutée, car grâce à une analyse post-mortem, il s'avère que certains des problèmes observés ne sont pas causés par le trafic, mais peuvent être dus à une dépendance à l'égard du trafic. problèmes de ressources, provoquant une congestion du système et amplifiant l’impact. 2. Améliorer le système d'alarme En raison de la survenance imprévisible des situations d'urgence, il est impossible pour quelqu'un d'être de service 24 heures sur 24. 3. Le système de gestion des services du mécanisme de rétrogradation automatique attend d'être établi. S'il rencontre un trafic soudain ou des anomalies soudaines dans les ressources dépendantes, il rétrogradera automatiquement sans surveillance.
5. Hors du corps : optimisation du business et ajustement de l'architecture du serveur
L'activité en développement rapide a également imposé des exigences plus élevées sur divers indicateurs de notre système. Le premier est le temps de réponse côté serveur.
La vitesse de réponse des deux modules fonctionnels de base de l'APP, le flux de flux et le texte, a un impact important sur l'expérience utilisateur globale. Selon les exigences de la direction, nous avons tout d'abord un objectif préliminaire : le temps de réponse moyen. du flux d'alimentation est de 100 ms. À ce moment-là, le temps de réponse global du flux est d'environ 500 à 700 ms, ce qui est un long chemin à parcourir !
L'activité de streaming de flux est complexe et repose sur de nombreuses ressources de données, telles que la publicité en temps réel, la personnalisation, les commentaires, le transfert d'image à image, les images ciblées, la livraison à position fixe, etc. Certaines ressources ne peuvent pas être mises en cache pour les données de calcul en temps réel. , nous ne pouvons pas compter sur la mise en cache. Nous pouvons seulement trouver un autre moyen et le résoudre par d'autres moyens.
Tout d'abord, nous avons travaillé avec l'équipe d'exploitation et de maintenance pour mettre à niveau l'environnement du système logiciel du serveur dans son ensemble, mis à niveau Nginx vers Tengine, puis mis à niveau PHP. L'effet de la mise à niveau était assez évident et le temps de réponse global a été réduit d'environ 20 %. à 300-400 ms, même si les performances ont été améliorées, elles sont encore loin de l'objectif. Au fur et à mesure de l'optimisation, nous effectuons une analyse des logs sur l'ensemble du lien business du flux pour connaître les zones les plus consommatrices de performances et les attaquer une par une.
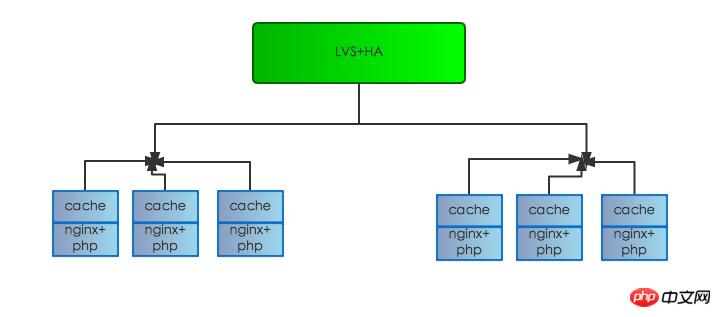
La structure originale du serveur est la suivante :
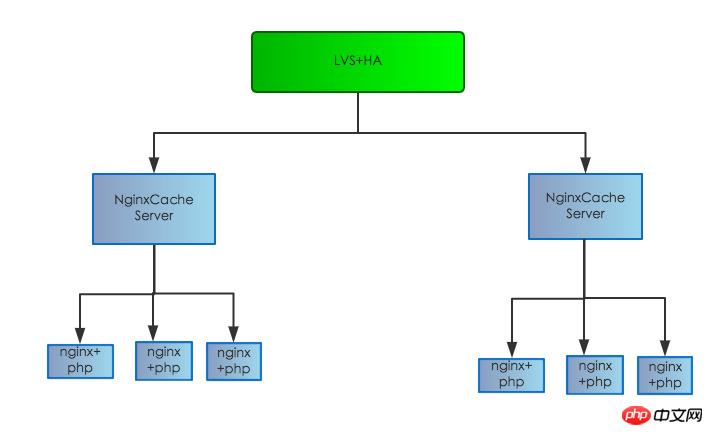
Il est divisé en : couche d'équilibrage de charge, couche proxy et couche Web. L'accès client est d'abord transmis à la machine Web Nginx PHP-FPM via le proxy de couche proxy Nginx. Il existe même un proxy inter-salles de machines. la machine Web n'est pas sur le même appareil, ni même sur la même machine. Dans une salle informatique, il peut y avoir de graves pertes de performances, grâce à de nombreuses analyses de journaux, qui, comme prévu, le temps de réponse de la couche proxy Nginx. L'enregistrement du journal est des dizaines, voire des centaines de millisecondes, plus long que le temps de réponse de l'enregistrement du journal de la couche Web, et il y a un seul point dans la couche de cache d'origine. Une fois le problème détecté, nous avons ajusté la structure du serveur comme suit : hors ligne. couche de cache d'origine et l'a déplacée vers la machine frontale Web pour réduire les goulots d'étranglement ponctuels et éliminer le risque de défaillances ponctuelles affectant la disponibilité globale du service.
Une fois l'ajustement de la structure du serveur terminé, le temps de réponse du flux a également été considérablement réduit et les performances ont été considérablement améliorées, atteignant environ 200 à 350 ms. Se rapprocher de l'objectif fixé, mais toujours pas atteindre l'objectif fixé.
Un jour, nos ingénieurs ont accidentellement découvert un problème lors du débogage du code. Le délai d'attente en millisecondes défini par PHP-CURL n'était pas valide. Nous avons vérifié grâce à un grand nombre de tests que la bibliothèque CURL par défaut fournie avec PHP ne prend pas en charge les millisecondes. documentation officielle PHP, nous avons constaté que l'ancienne version de la bibliothèque PHP libcurl présentait ce problème [nous avons découvert plus tard que la plupart des environnements de version PHP professionnelle de l'entreprise avaient ce problème] Cela signifie que le contrôle précis du grand nombre de délais d'attente d'interface dépendants que nous avons effectués dans le Le système n'a pas pris effet, ce qui a également entraîné un retard dans les performances du système. Une raison importante de ce retard est que la résolution de ce problème améliorera certainement les performances globales. Immédiatement, nous avons commencé les tests de vérification des niveaux de gris en ligne avec les étudiants d'exploitation et de maintenance. plusieurs jours de tests en ligne, aucun autre problème n'a été trouvé et les performances se sont vraiment beaucoup améliorées, nous avons donc progressivement élargi la portée jusqu'à ce que tous les serveurs soient en ligne. Les données ont montré qu'après la mise à niveau de la bibliothèque de versions libcurl, le temps de réponse du serveur est directement affiché. atteint 100-100 sans aucune autre optimisation. Environ 150 ms, très évident.
La couche de structure du serveur et la couche d'environnement du système logiciel ont fait tout ce qu'elles pouvaient, mais elles n'ont pas encore atteint l'exigence fixée de 100 ms pour le temps de réponse moyen du flux. À ce moment-là, elles ne peuvent commencer qu'avec le code métier. La demande de flux reposait sur des ressources exécutées séquentiellement. La congestion d'une ressource entraînera la mise en file d'attente des demandes suivantes, ce qui entraînera une augmentation du temps de réponse global. Nous avons commencé à essayer de changer PHP CURL en requêtes simultanées multithread, de changer la série en parallèle et de demander plusieurs interfaces de ressources dépendantes en même temps sans attendre. Grâce aux recherches techniques de nos amis, nous avons réécrit la bibliothèque de classes CURL pour fournir To. Pour éviter les problèmes, nous avons effectué une longue période de vérification des tests en niveaux de gris à grande échelle. Les tests ont réussi et ont été publiés dans l'environnement de production en ligne. Dans le même temps, les efforts de nos amis ont été récompensés directement. moins de 100 ms. Dans le même temps, le temps de réponse moyen de l'interface est contrôlé à 15 ms près.
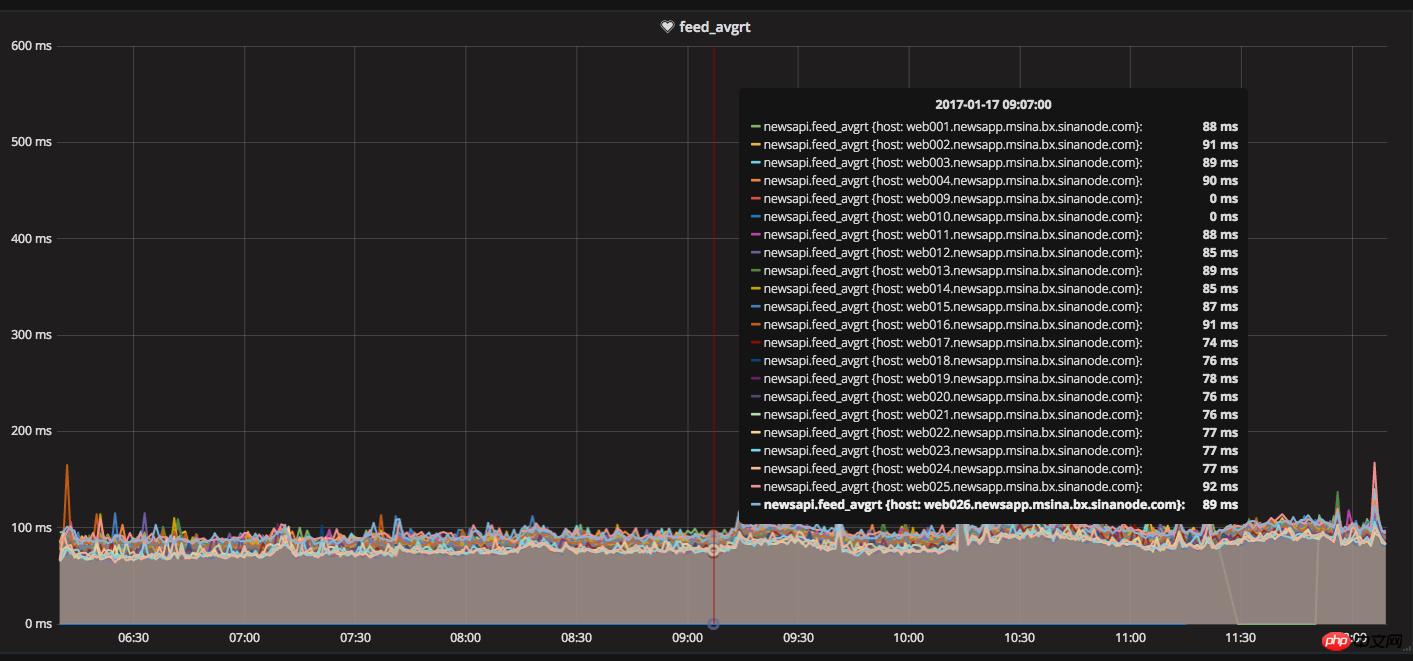
Temps de réponse du flux d'alimentation
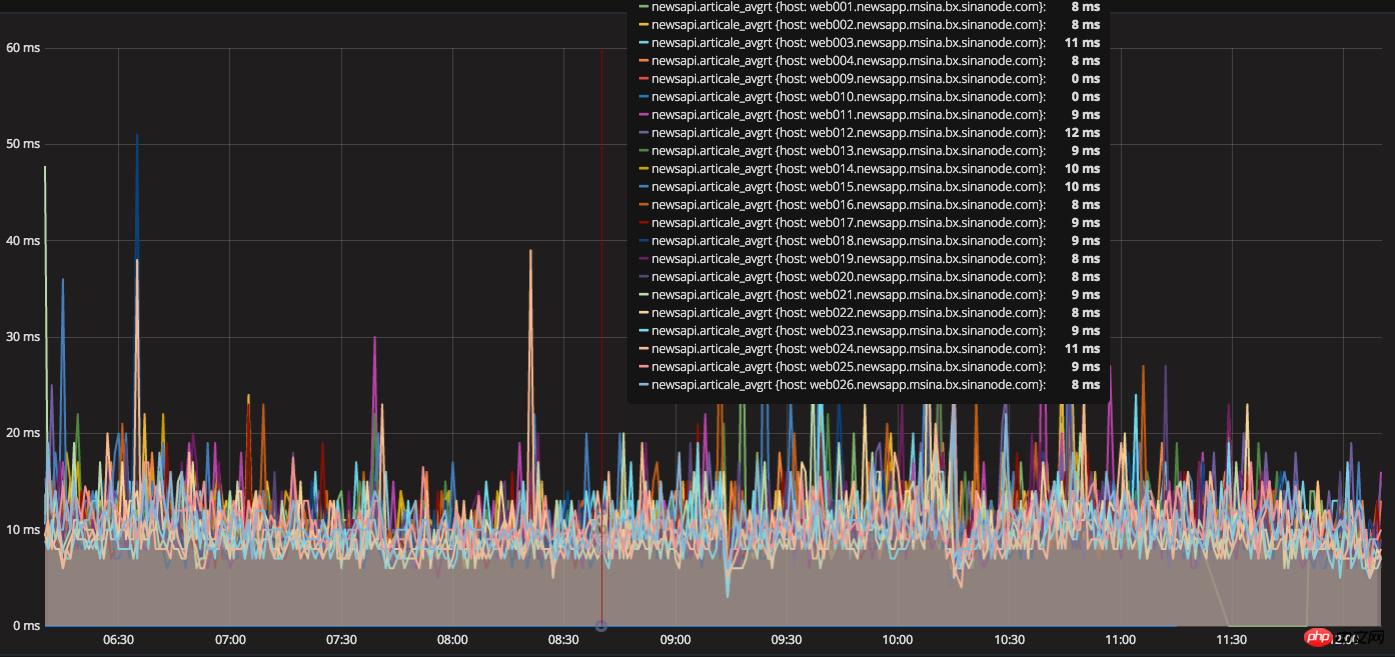 Temps de réponse moyen du texte
Temps de réponse moyen du texte
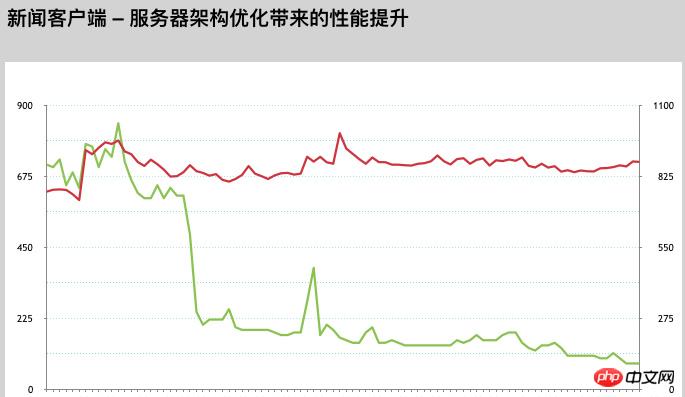
Par la suite, nous avons procédé à un déploiement distribué de serveurs dans chaque salle informatique, redistribué les nœuds d'accès au réseau VIP, optimisé les ressources d'appel réseau et évité l'impact négatif sur l'expérience utilisateur qui peut être causé par un accès inter-opérateurs nord-sud.
Grâce au grand nombre d'ajustements d'optimisation ci-dessus, la capacité de charge de l'ensemble de notre système a également été considérablement améliorée.
Le pic actuel de QPS atteint 134 000, et le nombre quotidien le plus élevé de demandes HIT atteint environ 800 millions. Le niveau de volume est déjà très impressionnant.
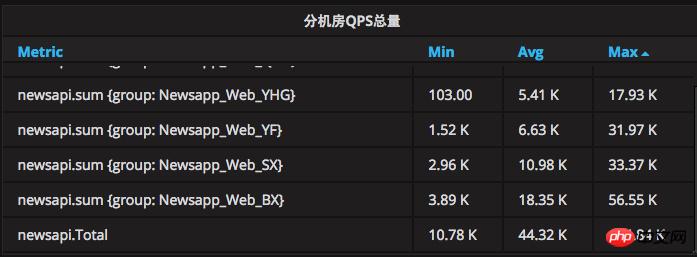
La capacité de charge QPS d'une seule machine a également été considérablement améliorée. Le système original 500-800QPS avec une seule machine était entièrement chargé, mais maintenant le système 2,5K avec une seule machine est toujours solide et immobile.
Grâce aux efforts continus des membres de l'équipe, ainsi qu'aux étudiants en exploitation et maintenance pour leur grande aide, les performances et la résistance à la charge du système d'interface news APP ont été considérablement améliorées.
6. Surmonter la tribulation : plateforme de gestion des services
Ce n'est qu'en élaborant une stratégie que nous pouvons gagner mille milles.
Les interfaces News APP s'appuient actuellement sur des centaines d'interfaces et de ressources tierces. Lorsqu'un problème survient avec une ou plusieurs interfaces et ressources, il est facile d'affecter la disponibilité du système.
Sur la base de cette situation, nous avons conçu et développé ce système. Les principaux modules du système sont les suivants :
Autoprotection du service, dégradation du service, analyse des erreurs et surveillance de la chaîne d'appels, surveillance et alarme. Centre de données hors ligne auto-construit, s'appuyant sur le système de détection de la durée de vie des ressources, le commutateur de planification d'accès à l'interface, le centre de données hors ligne collecte les données commerciales clés en temps réel, le système de détection de la durée de vie détecte l'état et la disponibilité des ressources en temps réel, le commutateur de planification d'accès à l'interface contrôle la demande d'interface, une fois la détection de la vie Lorsque le système détecte un problème avec une ressource, il rétrogradera et réduira automatiquement la fréquence d'accès via le commutateur de contrôle d'accès à l'interface, et prolongera automatiquement le temps de cache des données. Le système de détection de la vie détecte en permanence. la santé de la ressource. Une fois la ressource complètement indisponible, le commutateur de contrôle fermera complètement l'accès à la demande d'interface pour une dégradation automatique du service et permettra au centre de données local de fournir des données aux utilisateurs. Une fois que la sonde de vie a détecté que la ressource est disponible, reprenez l'appel. Ce système a réussi à éviter une forte dépendance aux ressources [telles que le CMS, les systèmes de commentaires, la publicité, etc.] à plusieurs reprises Défauts L'impact sur la disponibilité des services clients d'actualités. les ressources dépendantes échouent, la réponse de l'entreprise sera Le client n'en est fondamentalement pas conscient. Dans le même temps, nous avons mis en place un système complet de surveillance des exceptions, d'analyse des erreurs et de surveillance de la chaîne d'appels pour garantir que les problèmes peuvent être prédits, découverts et résolus dès que possible [détaillé dans le chapitre 7 Haute disponibilité du serveur].
Dans le même temps, l'activité client continue de se développer rapidement et chaque module fonctionnel est mis à jour et itéré rapidement. Afin de répondre à l'itération rapide sans problèmes sérieux de code, nous avons également augmenté les niveaux de gris du code et le processus de publication. Lorsqu'une nouvelle fonction est lancée, elle subira d'abord une vérification en niveaux de gris. Après avoir réussi la vérification, elle sera lancée à pleine capacité. En même temps, un nouveau et un ancien module de commutation sont réservés en cas de problème avec la nouvelle fonction. , il peut être basculé vers l'ancienne version à tout moment pour assurer un service normal.
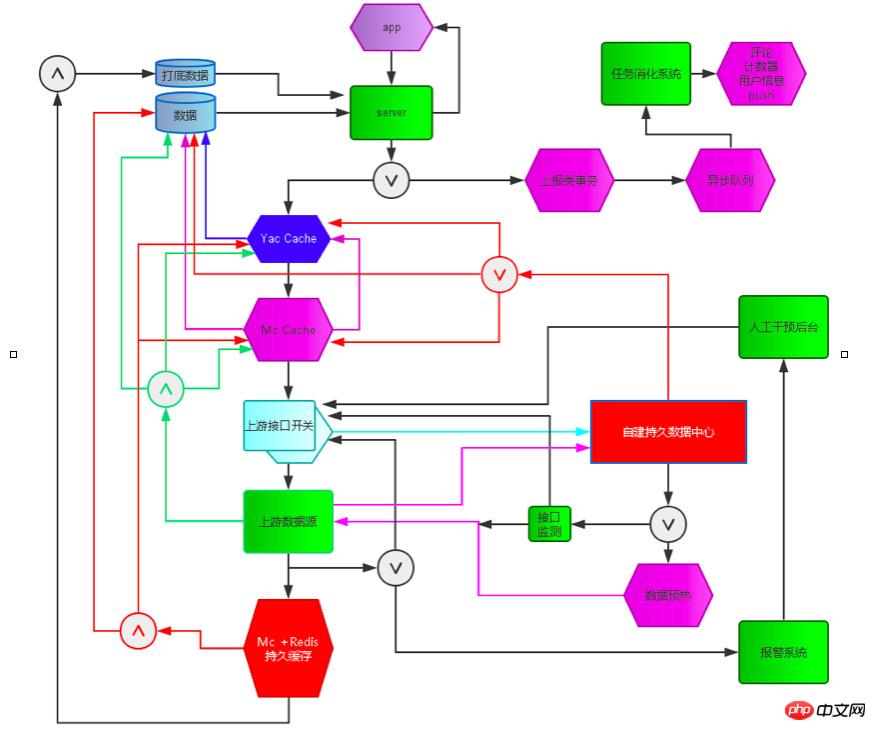 Mise en œuvre technologique de la plateforme de gouvernance des services
Mise en œuvre technologique de la plateforme de gouvernance des services
Une fois la plate-forme de gouvernance des services construite, notre architecture de services système est à peu près la suivante :
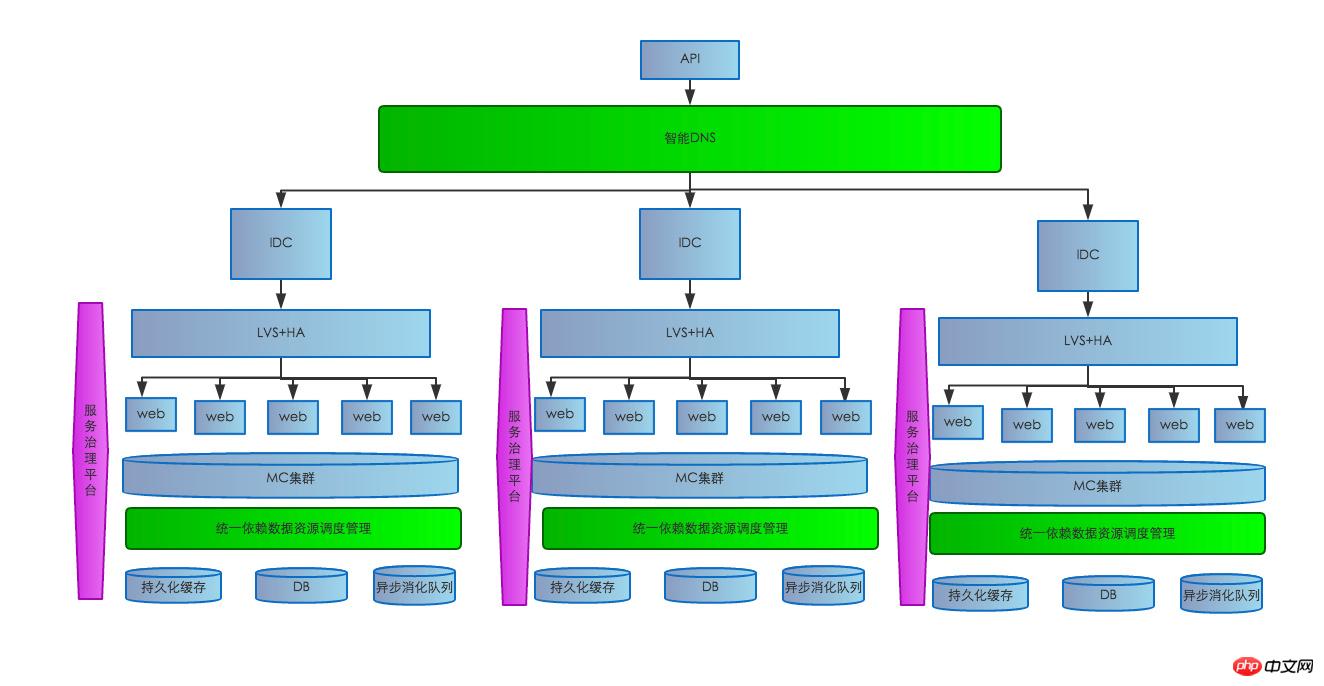
7. Mahayana : haute disponibilité du serveur
La haute disponibilité est actuellement l'un des problèmes les plus préoccupants dans les systèmes de services WEB à forte concurrence et à fort trafic. La conception à haute disponibilité est un projet systématique qui implique de nombreux aspects tels que le réseau, le matériel serveur, les services Web, le cache, la base de données, la dépendance aux ressources en amont, les journaux, la surveillance, les alarmes, l'autoprotection, la reprise après sinistre et la récupération rapide.
Définition de la haute disponibilité :
La formule de définition de la disponibilité du système (Disponibilité) est : Disponibilité = MTBF / (MTBF MTTR) × 100 %
Le MTBF (Mean Time Between Failure), qui est le temps moyen entre les pannes, est un indicateur qui décrit la fiabilité de l'ensemble du système. Pour un système Web à grande échelle, le MTBF fait référence au temps moyen nécessaire à l'exécution continue des services de l'ensemble du système sans interruption ni panne.
Le MTTR (Mean Time to Repair), qui est le temps moyen de récupération du système, est un indicateur qui décrit la capacité de tolérance aux pannes de l'ensemble du système.
Pour un grand système Web, MTTR fait référence au temps moyen nécessaire au système pour passer de l'état de panne à l'état normal lorsqu'un composant du système tombe en panne.
La formule montre que l’augmentation du MTBF ou la réduction du MTTR peuvent améliorer la disponibilité du système.
La question devient alors : comment améliorer la disponibilité du système grâce à ces deux indicateurs ?
À partir de la définition ci-dessus, nous pouvons voir qu'un facteur important dans la haute disponibilité : le MTBF est la fiabilité du système [temps moyen entre les pannes].
Ensuite, énumérons les problèmes qui affecteront le MTBF. Les facteurs possibles sont : 1. Matériel du serveur, 2. Réseau, 3. Base de données, 4. Cache, 5. Ressources dépendantes, 6. Erreurs de code, 7. Trafic important et soudain. Concurrence élevée. ces problèmes sont résolus, les échecs peuvent être évités et le MTBF peut être amélioré.
Sur la base de ces questions, comment le client de presse procède-t-il actuellement ?
La première panne matérielle du serveur : Si une panne matérielle du serveur entraîne l'indisponibilité du service sur ce serveur, la structure est la suivante. Le système actuel est LVS HA avec plusieurs MEM. serveurs., LVS HA dispose d'un système de détection de vie. Si une anomalie est détectée, elle sera supprimée de l'équilibrage de charge à temps pour empêcher les utilisateurs d'accéder au serveur problématique et de provoquer des pannes.
Le deuxième problème de réseau interne : Si une panne de réseau interne à grande échelle se produit, une série de problèmes se produiront, tels que l'échec de la lecture des ressources dépendantes, l'échec de l'accès à la base de données et échec de lecture et d'écriture du cluster Cache, etc., la portée de l'impact est relativement importante et les conséquences sont graves. Ensuite, nous écrirons plus d'articles cette fois. De manière générale, les problèmes de réseau surviennent principalement lorsque l'accès entre les salles informatiques est bloqué ou bloqué. Il est extrêmement rare que le réseau d’une même salle informatique soit déconnecté. Étant donné que certaines interfaces dépendantes sont distribuées dans différentes salles informatiques, les problèmes de réseau entre salles informatiques affecteront principalement la lenteur de réponse ou le délai d'attente des interfaces dépendantes. Pour ce problème, nous adoptons une stratégie de mise en cache à plusieurs niveaux une fois la salle informatique dépendante. L'interface est anormale, le cache localisé en temps réel sera pris en premier. Si pour une pénétration du cache localisé, accédez immédiatement au cache en temps réel du cluster de cache dans la salle informatique locale. Si le cache en temps réel du cluster est pénétré, Accédez au cache de défense persistant de la salle informatique locale. Dans des conditions extrêmement difficiles, s'il n'y a aucun résultat dans le cache persistant, la source de données de sauvegarde sera renvoyée à l'utilisateur. En même temps, la source de données de sauvegarde préchauffée est uniquement mise en cache. de manière persistante, afin que les utilisateurs n'en soient pas conscients et évitent les pannes à grande échelle. Pour résoudre le problème des retards dans la base de données causés par des problèmes de réseau, nous utilisons principalement l'écriture de file d'attente asynchrone pour augmenter le réservoir afin d'éviter que l'écriture de la base de données ne soit encombrée et n'affecte la stabilité du système.
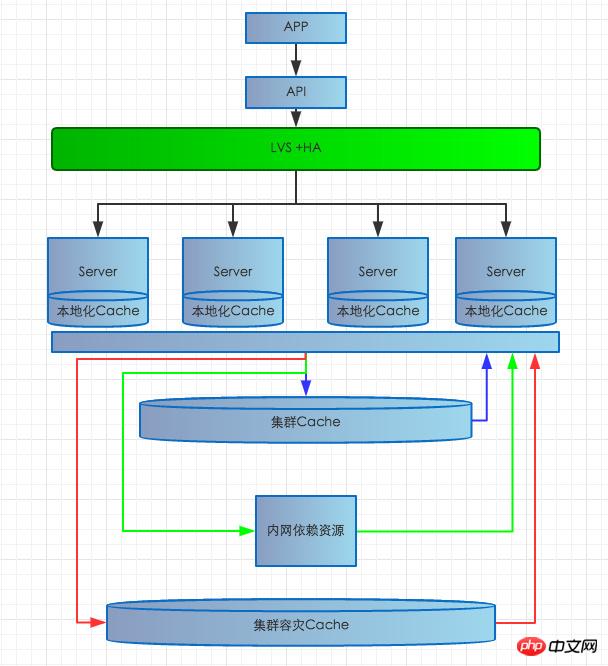
La sixième erreur de code : Il y a eu des cas dans le passé où des erreurs de codage ont provoqué des échecs sanglants en ligne, et de nombreux problèmes étaient causés par des erreurs de bas niveau, nous nous sommes donc également concentrés sur beaucoup de travail dans ce domaine.
Tout d'abord, nous devons standardiser le processus de développement et de publication du code. À mesure que l'entreprise se développe, les exigences en matière de stabilité et de fiabilité du système augmentent également de jour en jour. État social primitif d'agriculture sur brûlis et de travail seul. Toutes les opérations nécessitent d'être standardisées et orientées vers les processus.
Nous avons amélioré : l'environnement de développement, l'environnement de test, l'environnement de simulation, l'environnement en ligne et le processus en ligne. Une fois que l'ingénieur a terminé l'auto-test dans l'environnement de développement, il mentionne l'environnement de test et le service de test effectue le test. Après avoir réussi le test, il se rend dans l'environnement de simulation et effectue des tests de simulation. Si le test réussit, il le mentionne. au système en ligne. Le système en ligne doit être approuvé par l'administrateur avant de pouvoir être utilisé en ligne, une fois la régression en ligne terminée, la vérification de la régression en ligne est effectuée. Si la vérification est réussie, le processus de code en ligne est fermé. la vérification échoue, le système en ligne peut être ramené à l'environnement de pré-lancement en un seul clic.
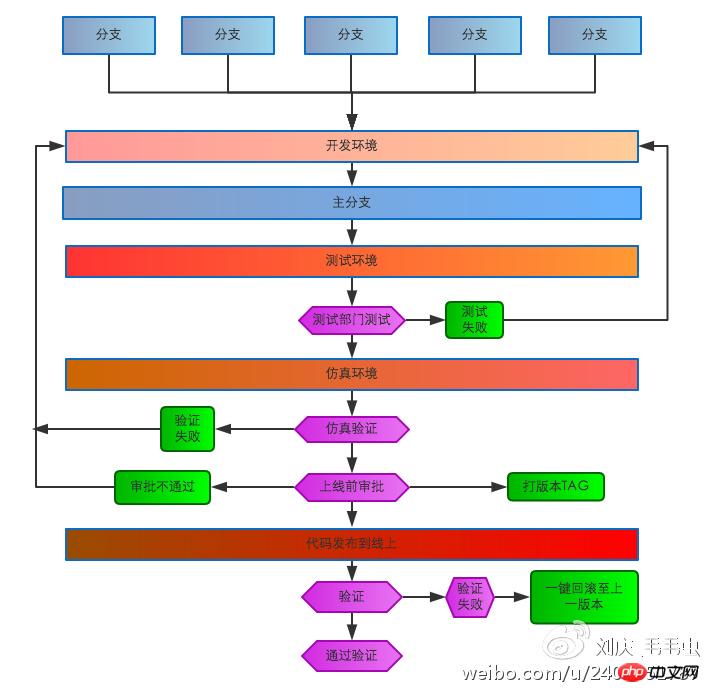 Processus de développement et de publication du code
Processus de développement et de publication du code
Ensuite, pour l'article 7 : Comment gérer un trafic soudain et important et une concurrence élevée ?
Nous définissons généralement un trafic important et soudain comme des points chauds et des urgences qui entraînent un grand nombre de demandes d'accès dans un court laps de temps, ce qui dépasse de loin la plage de charge attendue des logiciels et du matériel système. S'il n'est pas traité, cela peut affecter le service global. Cette situation dure peu de temps. S'il est trop tard pour ajouter temporairement une nouvelle machine en ligne, cela n'aura aucun sens une fois que la machine sera en ligne et que le pic de trafic sera passé. Si un grand nombre de machines de sauvegarde sont préparées en ligne à tout moment, ces machines resteront inactives 99 % du temps, ce qui gaspillera beaucoup de ressources financières et matérielles.
Dans une telle situation, nous avons besoin d’un système complet de planification du trafic, d’un disjoncteur de service et de mesures de limitation de courant. Si un trafic important et soudain provient de certaines zones spécifiques ou est concentré dans une ou plusieurs salles informatiques IDC, vous pouvez diviser une partie du trafic de la salle informatique avec une charge plus élevée vers la salle informatique avec un trafic inactif pour partager la pression ensemble. Cependant, si la segmentation du trafic n'est pas suffisante pour résoudre le problème, ou si la charge de trafic de toutes les salles informatiques est relativement élevée, nous ne pouvons alors protéger l'ensemble du service du système qu'au moyen d'un disjoncteur et d'une limitation de courant. Tout d'abord, trier en fonction de la priorité du système. module d'affaires, puis procéder en fonction de l'activité de faible priorité. Si la rétrogradation de l'entreprise ne parvient toujours pas à résoudre le problème, nous commencerons à désactiver les services de faible priorité un par un pour conserver les modules fonctionnels importants et continuer à fournir des services externes. Dans les cas extrêmes, si le déclassement de l'entreprise ne peut pas survivre au pic de trafic, nous prendrons les mesures de protection actuelles et abandonnerons temporairement un petit nombre d'utilisateurs pour maintenir la disponibilité de la plupart des utilisateurs de grande valeur.
Un autre indicateur important de la haute disponibilité est le temps de récupération moyen du système MTTR, qui correspond au temps nécessaire au service pour récupérer après une panne.
Les principaux points pour résoudre ce problème sont : 1. Trouver la panne, 2. Localiser la cause de la panne, 3. Résoudre la panne
Ces trois points sont tout aussi importants. Premièrement, il faut détecter les pannes à temps. En fait, ce n'est pas terrible si un problème survient, ce qui est terrible, c'est qu'on n'a pas trouvé le problème depuis longtemps, ce qui a provoqué un grand nombre de problèmes. pertes d'utilisateurs. C'est la chose la plus grave. Alors comment détecter les défauts à temps ?
Le système de surveillance est le maillon le plus important de l'ensemble du système, et même de tout le cycle de vie du produit. Il fournit des avertissements en temps opportun pour détecter les défauts à l'avance et fournit ensuite des données détaillées pour tracer et localiser les problèmes.
Tout d'abord, nous devons disposer d'un mécanisme de surveillance complet. La surveillance est nos yeux, mais la surveillance ne suffit pas. Nous devons également émettre des alarmes à temps et avertir le personnel concerné pour résoudre les problèmes en temps opportun. À cet égard, nous avons mis en place un système de surveillance et d’alarme avec le soutien du service d’exploitation et de maintenance.
De manière générale, un système de surveillance complet comporte principalement ces cinq aspects : 1. Ressources système, 2. Serveur, 3. État du service, 4. Exceptions d'application, 5. Performances des applications, 6. Système de suivi des exceptions
1. Surveillance des ressources système
Surveiller divers paramètres réseau et ressources liées au serveur (processeur, mémoire, disque, réseau, demandes d'accès, etc.) pour garantir le fonctionnement sécurisé du système serveur et fournir un mécanisme de notification d'exception pour permettre aux administrateurs système de localiser/résoudre rapidement divers ; problèmes existants.
2. Surveillance des serveurs
La surveillance des serveurs consiste principalement à vérifier si les réponses aux requêtes de chaque serveur, nœud de réseau, passerelle et autre équipement réseau sont normales. Grâce au service programmé, chaque périphérique de nœud de réseau reçoit régulièrement une requête ping pour confirmer si chaque périphérique réseau est normal. Si un périphérique réseau présente une anomalie, un message de rappel est émis.
3. Surveillance des services
La surveillance des services fait référence au fonctionnement normal des services de divers services Web et d'autres systèmes de plate-forme. Vous pouvez utiliser des services planifiés pour demander des services associés à intervalles réguliers afin de garantir que les services de la plate-forme fonctionnent normalement.
4. Surveillance des exceptions applicatives
Inclut principalement les journaux d'expiration anormaux, les erreurs de format de données, etc.
5. Surveillance des performances des applications
Surveillez si les indicateurs de temps de réponse de l'activité principale sont normaux, affichez la tendance de la courbe de performance de l'activité principale et découvrez et prédisez en temps opportun les problèmes possibles.
6. Système de suivi des exceptions
Le système de suivi des exceptions surveille principalement les ressources sur lesquelles l'ensemble du système s'appuie en amont et en aval. En surveillant l'état de santé des ressources dépendantes, telles que les modifications du temps de réponse, les modifications du taux de délai d'attente, etc., il peut prendre des décisions précoces et les gérer. risques possibles dans l’ensemble du système. Il peut également localiser rapidement les pannes survenues pour voir si elles sont causées par un problème de ressource dépendante, afin de résoudre rapidement la panne.
Les principaux systèmes de surveillance que nous utilisons actuellement en ligne sont les suivants :
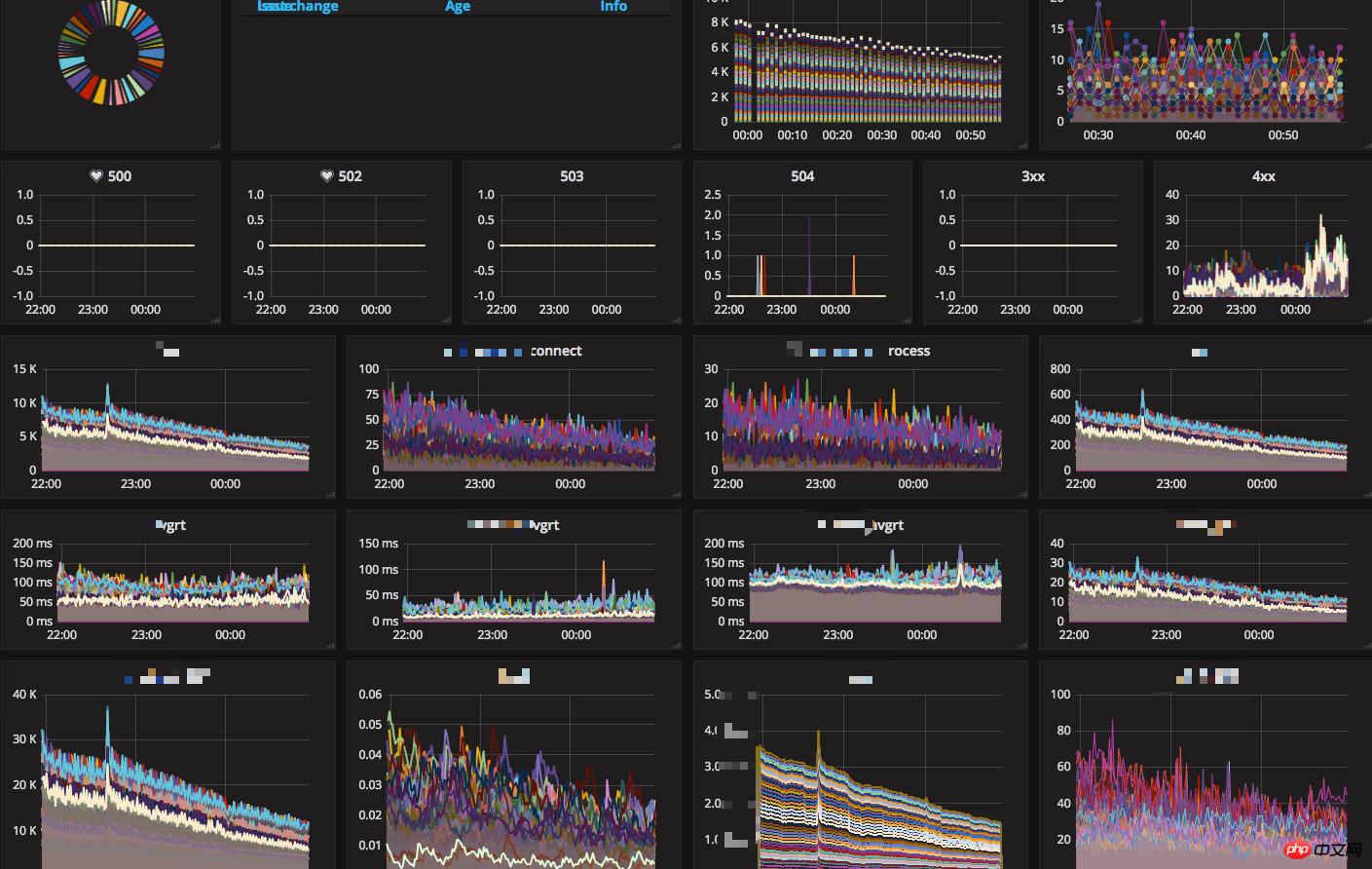 tableau de bord
tableau de bord
 Surveillance des délais d'attente des ressources dépendantes
Surveillance des délais d'attente des ressources dépendantes
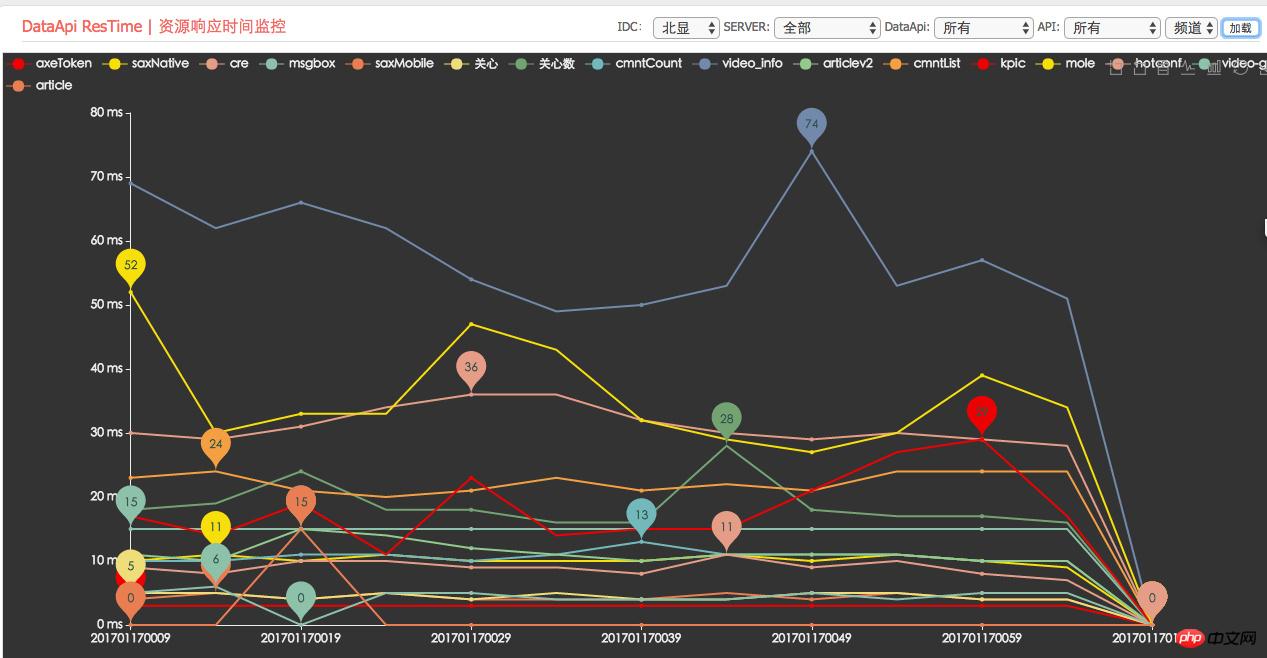 Surveillance du temps de réponse moyen des ressources dépendantes
Surveillance du temps de réponse moyen des ressources dépendantes
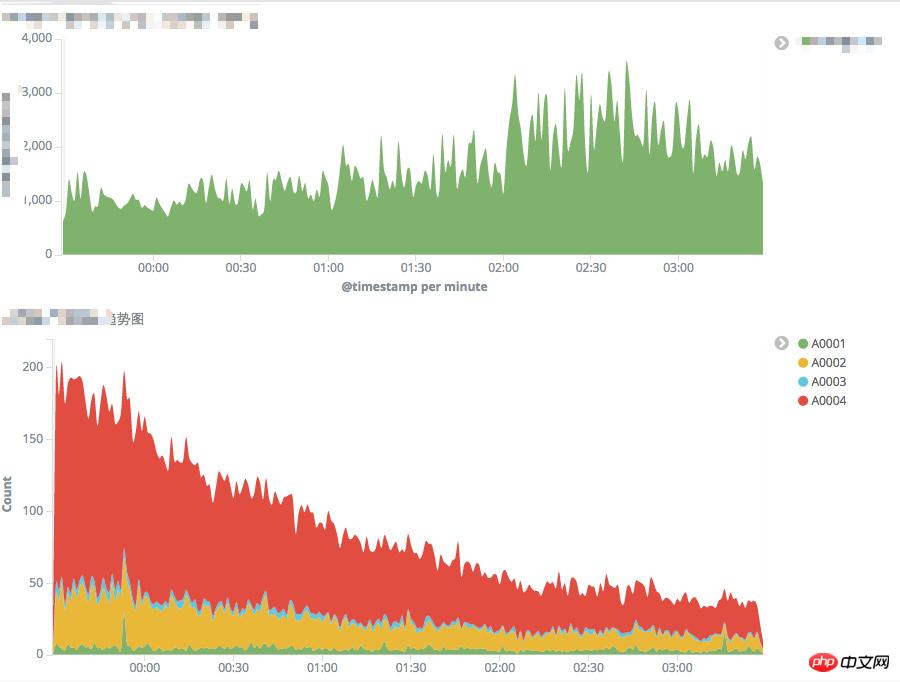
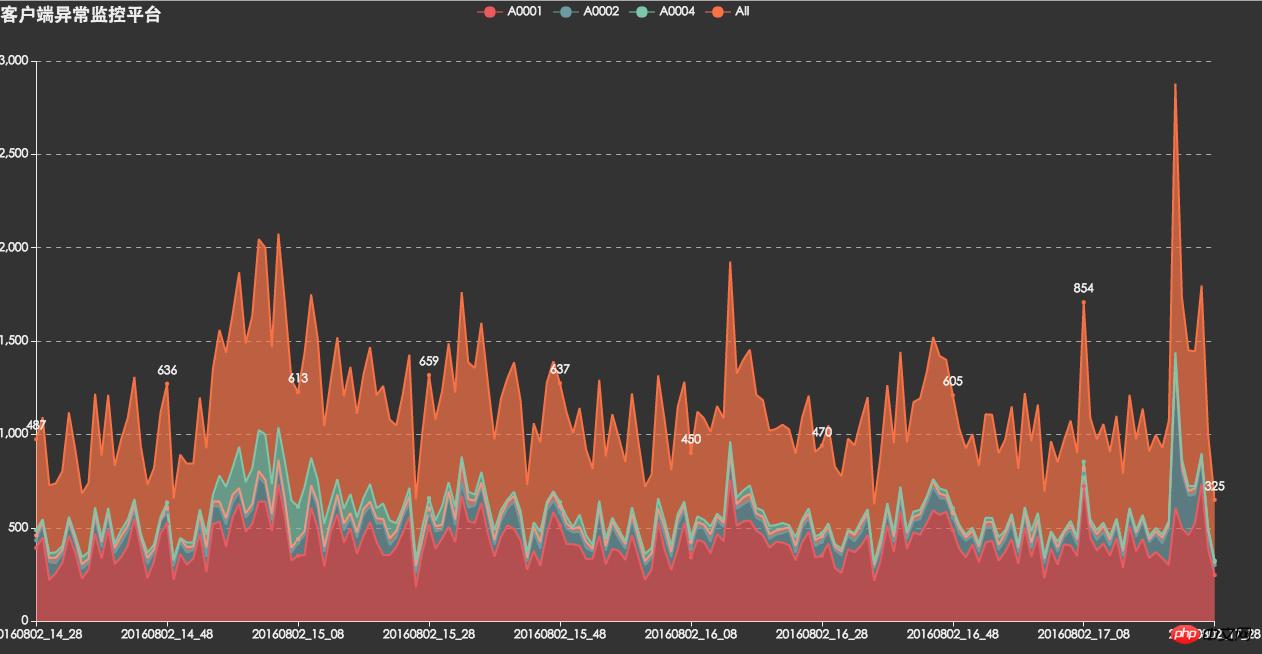 Surveillance des erreurs API
Surveillance des erreurs API
Remarque : [Citation, Étude] Il y a deux points principaux pour juger de la qualité d'un système de surveillance : 1. minutieux, 2. clair en un coup d'œil. Ces deux éléments semblent être en conflit l'un avec l'autre. Puisqu'il doit y avoir de très nombreux projets de surveillance en détail, ils ne peuvent pas être clairement compris d'un seul coup d'œil, mais ce n'est pas le cas. Être clair en un coup d'œil, c'est principalement être capable de détecter les problèmes à temps, car il est impossible d'avoir autant de temps et d'énergie pour regarder des centaines de graphiques de surveillance à tout moment. Ensuite, vous avez besoin d'un tableau de bord complet pour résumer si divers indicateurs sont normaux et répertorier les indicateurs anormaux pour identifier les problèmes en un coup d'œil. Être méticuleux consiste principalement à préparer le dépannage après l'apparition d'un problème. Vous pouvez vérifier si divers points de données de surveillance sont normaux pour localiser rapidement le problème.
8. Ascension : haute disponibilité pour le client
[Objectif important en 2017, haute disponibilité pour le client]
De nombreux articles ont été publiés récemment dans les médias Internet sur le HTTPS. L'une des raisons est que le comportement malveillant des opérateurs est de plus en plus faible et que des publicités ont été insérées à chaque instant il y a quelques jours. a publié conjointement une déclaration commune sur la résistance aux activités illégales telles que le détournement de trafic et a dénoncé certains opérateurs. D'un autre côté, cela est également fortement encouragé par la politique ATS d'Apple, obligeant tout le monde à utiliser la communication HTTPS dans toutes les applications. L’utilisation du HTTPS présente de nombreux avantages : protéger les données des utilisateurs contre les fuites, empêcher les intermédiaires de falsifier les données et authentifier les informations de l’entreprise.
Bien que la technologie HTTPS soit utilisée, certains opérateurs malveillants bloquent HTTPS et utilisent la technologie de pollution DNS pour pointer les noms de domaine vers leurs propres serveurs afin d'effectuer un piratage DNS.
Si ce problème n’est pas résolu, même HTTPS ne pourra pas résoudre fondamentalement le problème et de nombreux utilisateurs auront toujours des problèmes d’accès. Au moins, cela peut conduire à une méfiance à l'égard du produit, mais au pire, cela peut directement empêcher les utilisateurs d'utiliser le produit, entraînant ainsi une perte d'utilisateur.
Ainsi, selon des données tierces, quelle est la gravité de l'anomalie dans la résolution des noms de domaine pour des sociétés Internet comme Echang ? Chaque jour, le système distribué de surveillance de la résolution des noms de domaine de Gouchang détecte en permanence tous les LocalDNS clés à travers le pays. Le nombre d'exceptions de résolution quotidiennes pour les noms de domaine de Gouchang à travers le pays a dépassé 800 000. Cela a causé d’énormes pertes à l’entreprise.
Les opérateurs feront tout pour gagner de l'argent grâce à la publicité et économiser les règlements inter-réseaux. Une méthode de détournement courante qu’ils utilisent consiste à fournir de faux noms de domaine DNS via les FAI.
"En fait, nous sommes également confrontés au même problème grave"
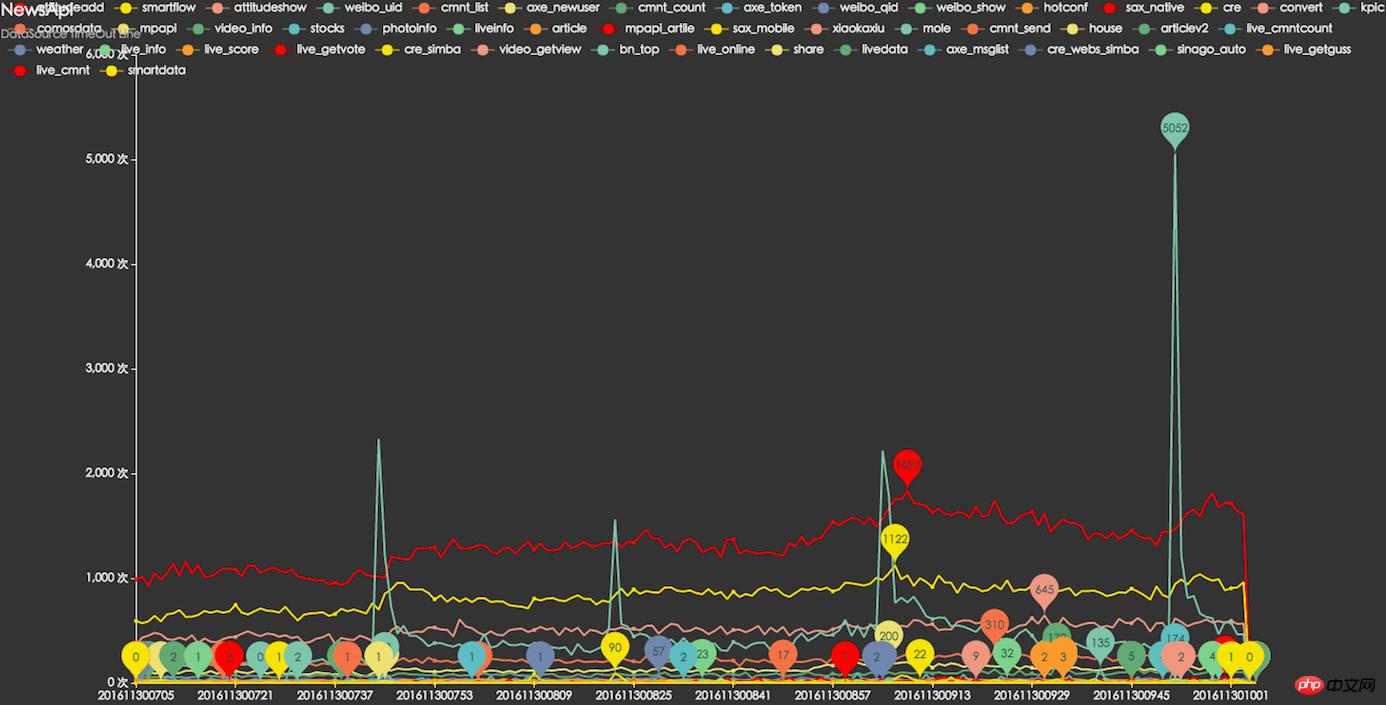
Grâce à la surveillance et à l'analyse des journaux sur l'application d'actualités, il a été constaté que 1 à 2 % des utilisateurs présentent des anomalies de résolution DNS et des problèmes d'accès à l'interface.
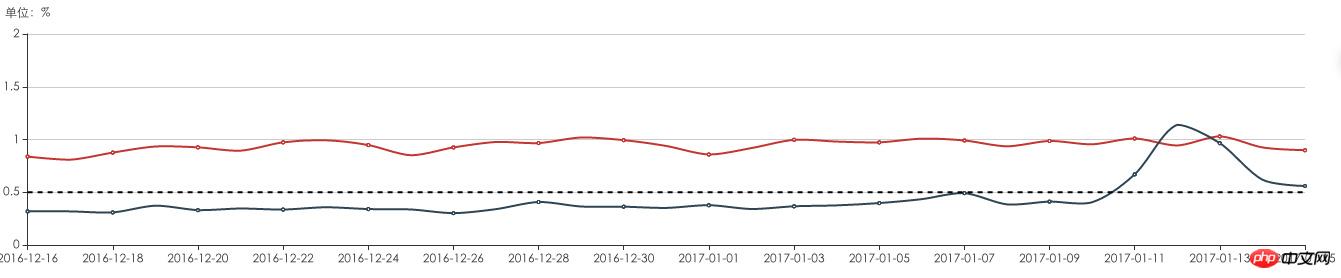
Anomalie DNS et impossibilité d'accéder à l'interface
En provoquant invisiblement un grand nombre de pertes d'utilisateurs, en particulier pendant la période de développement rapide des affaires, cela a causé de graves dommages à l'expérience commerciale.
Existe-t-il donc une solution technique capable de résoudre la cause profonde des anomalies de résolution de noms de domaine, des problèmes d'accès des utilisateurs entre réseaux et du piratage DNS ?
L'industrie a une solution pour résoudre ce genre de scénario, à savoir HTTP DNS.
Qu'est-ce que HttpDNS ? HttpDNS envoie des demandes de résolution de nom de domaine au serveur DNS sur la base du protocole Http, remplaçant la méthode traditionnelle d'initiation des demandes de résolution au LocalDNS de l'opérateur basée sur le protocole DNS. Il peut éviter le détournement de nom de domaine et les problèmes d'accès inter-réseaux causés par LocalDNS. et résolvez le problème de la résolution anormale des noms de domaine dans les services Internet mobiles.
Quels problèmes HttpDNS résout-il ?
HttpDNS résout principalement trois types de problèmes :Résout les anomalies de résolution DNS et le piratage de noms de domaine LocalDNS dans l'Internet mobile, le temps de réponse moyen augmente et le taux d'échec de connexion des utilisateurs reste élevé
1. Exception de résolution DNS et détournement de LocalDNS :
-
La situation actuelle du DNS mobile : l'exportation LocalDNS de l'opérateur effectue un NAT sur la base de l'adresse IP cible DNS faisant autorité, ou transmet la demande de résolution à d'autres serveurs DNS, ce qui empêche le DNS faisant autorité d'identifier correctement l'adresse IP LocalDNS de l'opérateur, ce qui entraîne le nom de domaine. erreurs de résolution et trafic traversant le réseau.
- Conséquences du piratage de nom de domaine : inaccessibilité du site Internet (impossibilité de se connecter au serveur), pop-up publicitaire, accès à des sites de phishing, etc.
- Les conséquences des résultats d'analyse inter-domaines, inter-provinces, inter-opérateurs et inter-pays : l'accès aux sites Web est lent, voire inaccessible.
Étant donné que l'adresse IP est directement accessible, un processus de résolution de domaine est omis et le nœud le plus rapide est trouvé pour l'accès après tri via des algorithmes intelligents.
3. Réduction du taux d'échec de connexion des utilisateurs :Réduisez le classement des serveurs avec des taux d'échec excessifs dans le passé grâce à des algorithmes, améliorez le classement des serveurs grâce aux données récemment consultées et améliorez les serveurs grâce à l'historique des succès d'accès. Trier les enregistrements. S'il y a une erreur d'accès à ip(a), les enregistrements triés de ip(b) ou ip(c) seront renvoyés la prochaine fois. (LocalDNS est susceptible de renvoyer des enregistrements dans un ttl (ou plusieurs ttl) HTTPS peut empêcher au maximum les opérateurs de détourner le trafic, y compris la falsification de la sécurité du contenu.
HTTP-DNS peut résoudre le problème du DNS client, en garantissant que les requêtes des utilisateurs sont dirigées directement vers le serveur ayant la réponse la plus rapide.
Le principe de mise en œuvre de HttpDNS
Le principe du HTTP DNS est très simple. Il convertit le DNS, un protocole facilement détournable, en requêtes de protocole HTTP
Cartographie DomainIP. Après avoir obtenu la bonne IP, le Client assemble lui-même le protocole HTTP pour empêcher le FAI de falsifier les données.
Le client accède directement à l'interface HTTPDNS pour obtenir l'IP optimale du nom de domaine. (Sur la base de considérations de reprise après sinistre, la méthode d'utilisation du LocalDNS de l'opérateur pour résoudre les noms de domaine est réservée comme alternative.)
Une fois que le client a obtenu l’adresse IP professionnelle, il envoie une demande de protocole métier directement à cette adresse IP. En prenant la requête HTTP comme exemple, vous pouvez envoyer une requête HTTP standard à l'IP renvoyée par HTTPDNS en spécifiant le champ hôte dans l'en-tête.
Si vous souhaitez obtenir une haute disponibilité côté client, vous devez d’abord résoudre ce problème. Nous avons commencé les préparatifs avec nos étudiants en développement d'APP et nos étudiants en exploitation et maintenance, en nous efforçant de lancer HTTPDNS le plus rapidement possible afin d'atteindre une haute disponibilité pour le client APP et de fournir une garantie fiable pour le développement rapide de l'entreprise !
Après un an de travail acharné, l'ensemble du système back-end de l'APP est passé de l'ère barbare à l'état de perfection actuel. J'ai également appris beaucoup de connaissances grâce à un peu d'exploration, et je pense avoir également atteint. une forte croissance, mais en même temps, nous sommes confrontés à de très nombreux problèmes, avec le développement rapide des entreprises, les exigences en matière de services back-end sont de plus en plus élevées. Il reste encore de nombreux problèmes à résoudre à l'avenir. Nous nous imposerons également des normes plus élevées et nous préparerons à l’échelle de centaines de millions d’utilisateurs.
www.php.cn) !
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)