Maison >base de données >tutoriel mysql >Analyse MySQL - Expliquez l'introduction détaillée
Analyse MySQL - Expliquez l'introduction détaillée

- 黄舟original
- 2017-03-02 16:24:012570parcourir
Pourquoi vous devez comprendre expliquer :
Vous voulez comprendre la situation interne de la requête sélectionnée, le fonctionnement de l'optimiseur de requête, et s'il faut l'utiliser. En matière d'indexation, expliquer peut le faire.
Comment fonctionne l'optimiseur de requêtes MySQL :
L'optimiseur de requêtes MySQL a plusieurs objectifs, mais parmi eux le principal L'objectif est d'utiliser des index autant que possible et d'utiliser l'index le plus strict possible pour éliminer autant de lignes de données que possible. Le but ultime est de soumettre une instruction SELECT pour rechercher des lignes de données, et non pour exclure des lignes de données. La raison pour laquelle l'optimiseur tente d'exclure des lignes est que plus il peut exclure des lignes rapidement, plus il trouvera rapidement les lignes qui correspondent à la condition. Les requêtes peuvent s'exécuter plus rapidement si les tests les plus rigoureux sont effectués en premier.
1.explain Il existe dix paramètres d'attribut 
2. Explication de la colonne EXPLAIN :
1.id : Le numéro de séquence interrogé dans le plan d'exécution sélectionné. Indique l'ordre dans lequel les clauses de sélection ou les tables d'opérations sont exécutées dans la requête. Plus la valeur de l'identifiant est grande, plus la priorité est élevée et plus l'exécution est précoce. Les identifiants sont les mêmes et l'ordre d'exécution est de haut en bas.
2.select_type : Type de requête, description :

3.table : Afficher cette ligne Sur quelle table portent les données ? Colonne importante indiquant le type de
utilisé par la connexion. Les types de jointure, du meilleur au pire, sont const, eq_reg, ref, range, index et ALL 5.possible_keys : spectaclespossibleL'index appliqué à ce tableau. S'il est vide, aucun index n'est possible. Une instruction appropriée peut être sélectionnée parmi les instructions WHERE 6.key : > L'index réel utilisé . Si NULL, aucun index n'est utilisé. Rarement, MYSQL sélectionnera un index sous-optimisé. Dans ce cas, vous pouvez utiliser USEINDEX(indexname) dans l'instruction SELECT pour forcer l'utilisation d'un index ou utiliser IGNORE
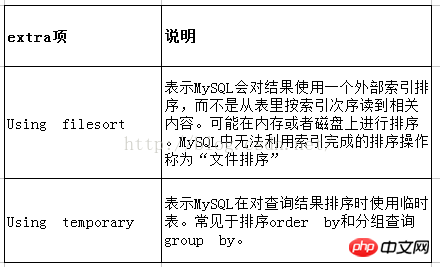
INDEX(indexname) pour forcer MYSQL à ignorer l'index 7.key_len : La longueur de l'index utilisé par . Plus la longueur est courte, mieux c'est sans perdre en précision 8.ref : Montre quelle colonne de l'index est utilisée , si possible, est une constante 9.rows : Le nombre de lignes qui, selon MYSQL, doivent être vérifiées pour renvoyer les données demandées 10.Extra : Informations supplémentaires sur la façon dont MYSQL analyse la requête. Le mauvais exemple que vous pouvez voir ici est Using
temporaire et l'utilisation de filesort signifient que MYSQL ne peut pas du tout utiliser l'index. Le résultat est que la récupération sera très lente et doit être évitée. Évidemment, lorsque le type est ALL, c'est le pire des cas. L'utilisation du tri de fichiers apparaît également dans Extra, ce qui est également le pire des cas et une optimisation est nécessaire. Plus vous ajoutez d'index, mieux c'est. Il existe des compromis dans les tableaux de différentes ampleurs. La maintenance de l'index lui-même peut devenir un fardeau, vous devez donc être en mesure d'ajouter des index de manière raisonnable. Utiliser expliquer pour voir si votre relevé doit être optimisé ? Ce qui précède est une introduction détaillée à Mysql Analysis-Explain. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !