
Maison >base de données >tutoriel mysql >Stratégie de pagination d'optimisation Mysql sous un grand volume de données
Stratégie de pagination d'optimisation Mysql sous un grand volume de données

- 黄舟original
- 2017-03-02 16:07:371622parcourir
Un. Préface
Habituellement, comment implémentons-nous la pagination ?
SELECT * FROM table ORDER BY id LIMIT 1000, 10;
Mais que se passe-t-il lorsque la quantité de données augmente considérablement ?
SELECT * FROM table ORDER BY id LIMIT 1000000, 10;
La deuxième requête ci-dessus est très lente et sera retardée jusqu'à la mort.
La raison la plus critique est le problème du mécanisme de requête MySQL :
Il ne s'agit pas de sauter d'abord et d'interroger plus tard ; >
Au lieu de cela, interrogez d'abord et ignorez plus tard. (Explication ci-dessous) Que signifie
? Par exemple, limitez 100 000,10. Lorsque les 10 éléments requis sont trouvés, les 100 000 premiers éléments de données seront interrogés. Tout d'abord, les données de champ des 100 000 premiers éléments seront récupérées, puis supprimées si elles s'avèrent inutiles, jusqu'à ce que. les 10 éléments requis sont enfin trouvés.
Deux. Analyse
limit offset,N, lorsque le offset est très grand, l'efficacité est extrêmement faible,
La raison est que MySQL ne le fait pas ignorez la ligne de décalage. Ensuite, prenez simplement N lignes,
mais prenez les N lignes de décalage, renvoyez les lignes de décalage avant d'abandonner et renvoyez N lignes [comme mentionné ci-dessus pour interroger d'abord, puis ignorez ].
L'efficacité est inférieure Lorsque le décalage est plus grand, l'efficacité est inférieure.
1 :Résolvez-le d'un point de vue commercial
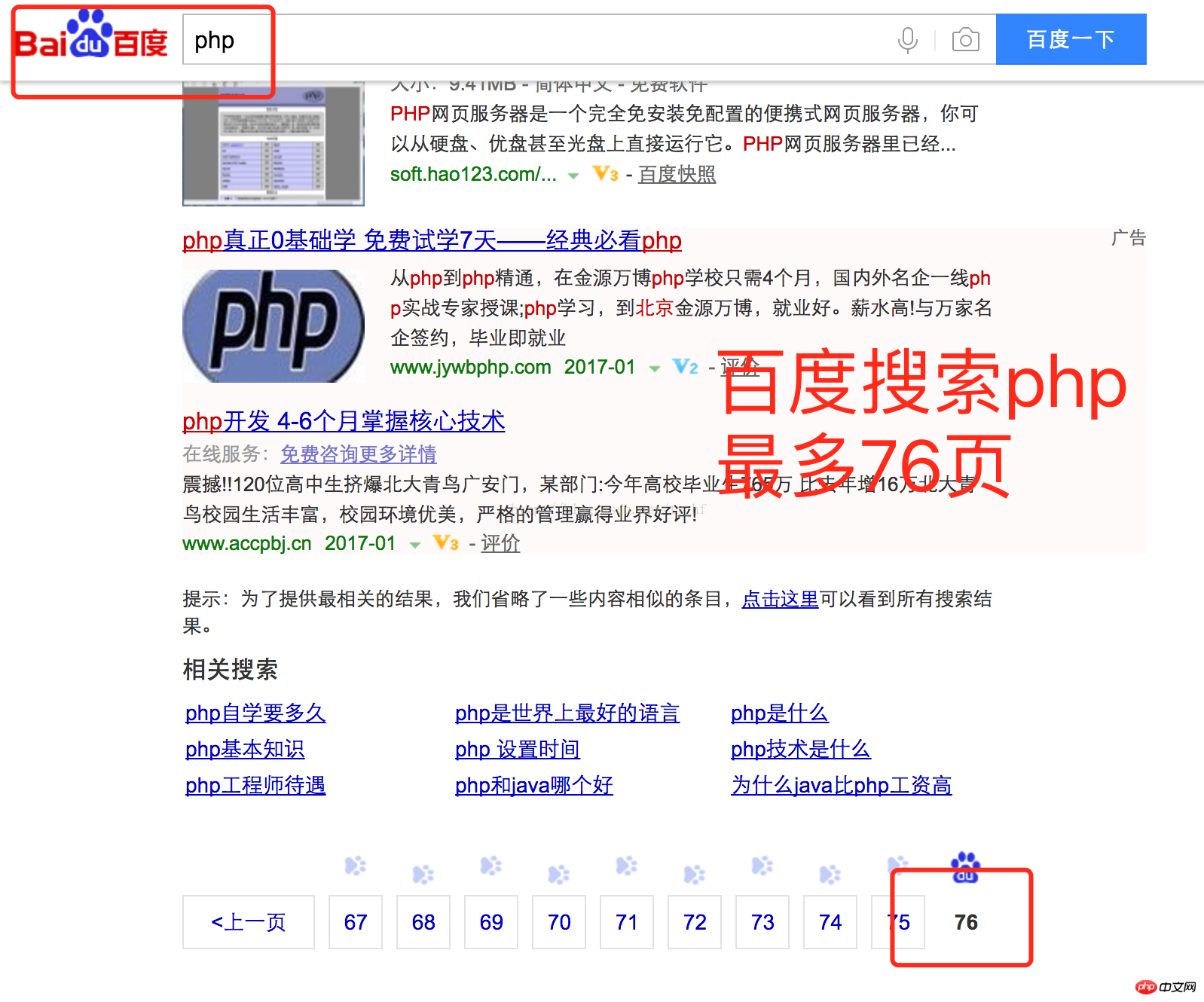
Méthode :Interdit de retourner 100 pages
Prenons Baidu comme exemple , tournent généralement la page à environ 70 pages .
2 :Pas besoindécalage, Requête avec conditions.
Exemple :
Phénomènes : De 5,3 secondes à moins de 100 millisecondes, la vitesse de requête est considérablement accélérée mais les résultats des données sont différentsmysql> select id, from lx_com limit 5000000,10; +---------+--------------------------------------------+ | id | name | +---------+--------------------------------------------+ | 5554609 |温泉县人民政府供暖中心 | .................. | 5554618 |温泉县邮政鸿盛公司 | +---------+--------------------------------------------+ 10 rows in set (5.33 sec) mysql> select id,name from lx_com where id>5000000 limit 10; +---------+--------------------------------------------------------+ | id | name | +---------+--------------------------------------------------------+ | 5000001 |南宁市嘉氏百货有限责任公司 | ................. | 5000002 |南宁市友达电线电缆有限公司 | +---------+--------------------------------------------------------+ 10 rows in set (0.00 sec)
Avantages ; : Utilisez la condition Where pour éviter la première requête , puis ignorez les questions . Au lieu de cela, la condition réduit la portée et saute directement.
Il y a un problème : Parfois, on constate que les résultats de l'utilisation de cette méthode et de la limiteM, N, deux fois sont incohérents [ comme le montre l'exemple ci-dessus ]
Cause :Les données ont été physiquement supprimées,Il y a des trous.
Solution :Les données ne sont pas supprimées physiquement(peuvent être logiquement supprimées). 最终在页面上显示数据时,逻辑删除的条目不显示即可. (一般来说,大网站的数据都是不物理删除的,只做逻辑删除 ,比如 is_delete=1) 3:延迟索引. 非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办? 优化思路: 利用索引覆盖,快速查询出满足条件的主键id;然后凭借主键id作为where条件,达到快速查询。 (速度快在哪里?利用索引覆盖不需要回行就可以快速查询出满足条件的id,时间节约在这里了) 我们现在必须要查,则只查索引,不查数据,得到id.再用id去查具体条目. 这种技巧就是延迟索引. 慢原因: 查询100W条数据的id,name,m每次查询回行抛弃,跨过100W后取到真正要的数据。【就是我们刚刚说的,先查询,后跳过】 优化后快原理: a.利用索引覆盖先查询出主键id,在索引上就拿到信息了,避免回行 b.找到主键后,根据已知的目标主键在查询,避免跨大数据行去寻找,而是直接定位哪几条数据直接查询。 本方法即延迟索引查询。 四。总结: 从方案上来说,肯定是方法一优先,从业务上去满足是否要翻那么多页。 如果业务要求,则用id>n limit m的方式来代替limit n,m,但缺点是不能有物理删除 如果非有物理删除有空缺不能用方法二,则用延迟索引法,本质是利用索引覆盖先快速取出索引值,根据锁定的目标的索引值。一次性去回行取值,效果很明显。 以上就是Mysql优化-大数据量下的分页策略的内容,更多相关内容请关注PHP中文网(www.php.cn)!mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id);
+---------+-----------------------------------------------+
| id | name |
+---------+-----------------------------------------------+
| 5050425 | 陇县河北乡大谈湾小学 |
........
| 5050434 | 陇县堎底下镇水管站 |
+---------+-----------------------------------------------+
10 rows in set (1.35 sec)