
Maison >base de données >tutoriel mysql >Détails du calcul de la longueur de l'index dans MySQL
Détails du calcul de la longueur de l'index dans MySQL

- 黄舟original
- 2017-03-01 13:31:022395parcourir
Regardons d'abord une question. Pour la table t, elle contient trois champs a, b et c. En supposant que leurs valeurs par défaut ne soient pas vides, créez maintenant un index combiné (a. , b, c) analyse Quelle est la différence entre select * from t où a=1 et c=1 et select * from t où a=1 et b=1 ?
Créez d'abord la table
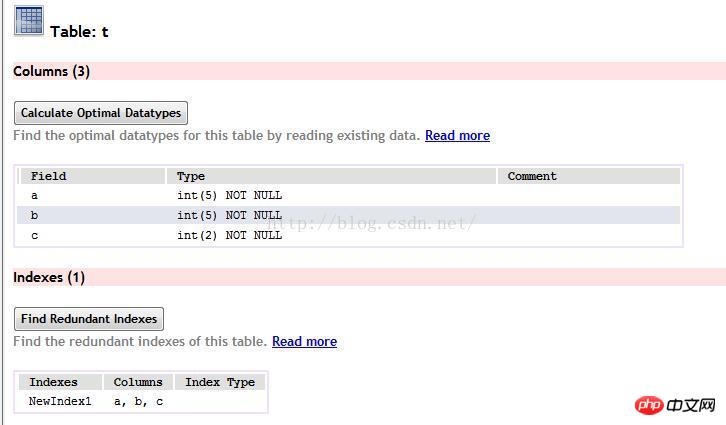
Exécutez ces deux éléments respectivement La déclaration
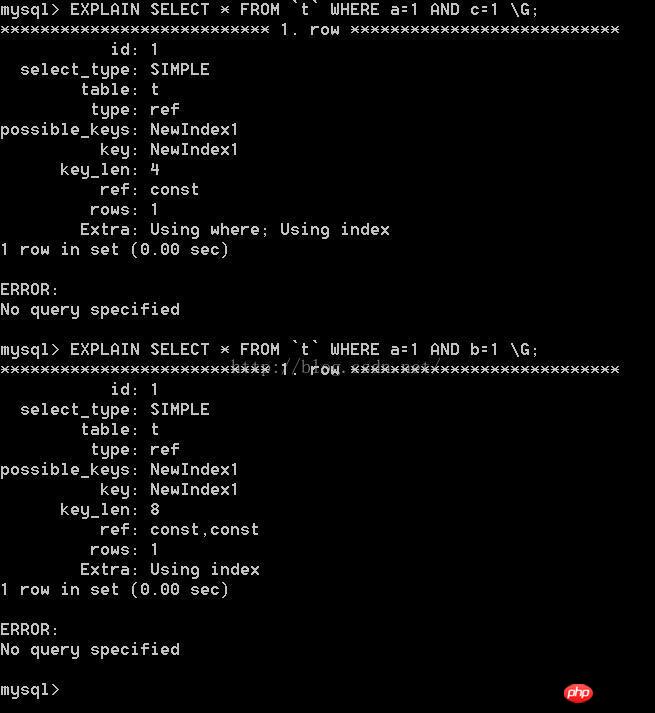
a révélé que la différence entre les deux déclarations réside principalement dans key_len Pourquoi les différences. entre les deux déclarations différentes ?
Ma compréhension est la suivante :
Nous pouvons considérer l'index combiné comme le répertoire de premier niveau, le répertoire de deuxième niveau et le répertoire de troisième niveau du livre, tel que index(a,b,c) équivaut à a étant un répertoire de premier niveau, b étant un répertoire de deuxième niveau sous le répertoire de premier niveau et c étant un répertoire de troisième niveau répertoire sous le répertoire de deuxième niveau. Pour utiliser un répertoire, vous devez d'abord utiliser son répertoire supérieur, à l'exception du répertoire de premier niveau.
Donc
où a=1 et c=1 n'utilise que le répertoire de premier niveau, c est dans le troisième- répertoire de niveau, et il n'y a pas d'utilisation du répertoire de deuxième niveau, alors le répertoire de troisième niveau ne peut pas être utilisé
où a=1 et b=1 n'utilisent qu'un répertoire de premier niveau et un répertoire de deuxième niveau.
Donc, le key_len de la deuxième requête est plus grand.
Mais comment est calculé key_len ? Comment calcule-t-on 4 et 8 ci-dessus ? Je n'y ai pas prêté beaucoup d'attention auparavant ? Lors de l'analyse des performances des instructions de requête SQL via expliquer, j'ai accordé plus d'attention à select_type, type, possible_key, key, ref, rows, plus cette fois, je pense qu'il est nécessaire de le faire. clarifier le calcul de key_len.
1 Pour tous les champs d'index, si non null n'est pas défini, un octet doit être ajouté.
2. Champ de longueur fixe, int occupe quatre octets, date occupe trois octets et char(n) occupe n caractères.
3. Pour le champ varchar(n), il y a n caractères et deux octets.
4. Différents jeux de caractères, le nombre d'octets occupés par un caractère est différent. En codage latin1, un caractère occupe un octet, en codage gbk, un caractère occupe deux octets et en codage utf8, un caractère occupe trois octets.
Par conséquent peut être conclu que
où a=1 et c = 1, key_len=4
où a=1 et c=1, key_len=4 4=8
Maintenant, faisons une autre question, créons une table t2 , la structure des données est la suivante
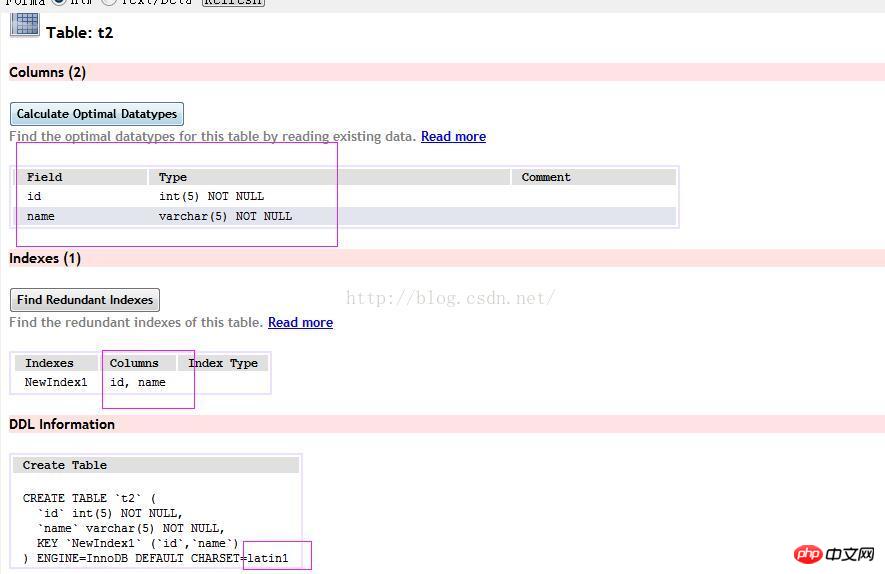
Veuillez exécuter expliquer select * from t2 Where name="001" et id=1 G ; Qu'est-ce que key_len ?
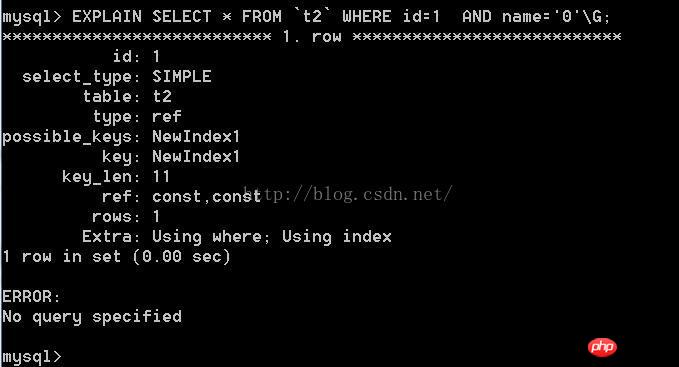
Analyse key_len=4 5*1 2=11, car les champs ne sont pas nuls, le type int est de 4 octets et varchar(5) occupe 5 caractères et 2 octets, chacun Le caractère de la table codée en latin1 occupe 1 octet, donc varchar(5) occupe 7 octets. La structure est la suivante
Supplément
Parce que MySQL dispose d'un optimiseur de requêtes, pour les requêtes de type où a=1 et c=1, les champs Le l'ordre n'a aucun effet, l'optimiseur de requêtes optimisera automatiquement. où c=1 et a=1 seront optimisés pour où a=1 et c=1, mais il est recommandé d'utiliser où a=1 et c=1, pour faciliter la compréhension et la mise en mémoire tampon des requêtes. Étant donné que la mise en mémoire tampon des requêtes et les valeurs de clé de hachage sont calculées sur la base d'instructions SQL et sont sensibles à la casse, lors de l'écriture d'instructions SQL, essayez de les maintenir cohérentes pour éviter que la même requête ne soit mise en cache plusieurs fois.
Ce qui précède contient les détails du calcul de la longueur de l'index dans MySQL. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !