
Maison >base de données >tutoriel mysql >Expérience d'optimisation Mysql (1) – Partition
Expérience d'optimisation Mysql (1) – Partition

- 黄舟original
- 2017-02-28 13:43:041829parcourir
Le concept d'optimisation est toujours mentionné dans le processus de développement d'un projet.Cet article est un voyage d'exploration de la pratique d'optimisation des données Mysql. Il présente brièvement les raisons, les méthodes, les méthodes de gestion des tables de partition et une pratique simple du partitionnement.
[Pourquoi partitionner]
Lors de l'exploitation du Big Data, divisez et conquérez la table de données et divisez une table avec une grande quantité de données dans Une unité opérationnelle plus petite, chaque unité opérationnelle aura un nom distinct. Dans le même temps, pour les développeurs de programmes, le partitionnement équivaut à l'absence de partitionnement. De manière générale, le partitionnement MySQL est transparent pour les applications du programme et n'est qu'un réarrangement des données par la base de données.
Fonction de partition :
(1) Améliorer les performances.
Le but ultime du partitionnement est d'améliorer les performances. Une fois le partitionnement terminé, MySQL génère des fichiers de données et des fichiers d'index spécifiques pour chaque partition, et récupère des données partielles spécifiques lors de la récupération. mieux mettre en œuvre et maintenir la base de données. En effet, les tables partitionnées sont affectées à différents disques physiques, ce qui réduit les conflits d'E/S physiques entre partitions lors de l'accès à plusieurs partitions en même temps.
(2) Facile à gérer.
Après le partitionnement, les données de gestion peuvent gérer directement la partition correspondante. L'opération est simple. Lorsque les données atteignent des millions, l'exploitation directe de la partition est bien plus directe que l'exploitation de la table de données.
(3) Tolérance aux pannes
Une fois la partition terminée, si une partition est détruite, d'autres données seront ne soit pas affecté.
[Méthode de partitionnement]
Les méthodes de partitionnement de MySQL incluent : la partition RANGE, la partition LIST, la partition HASH et la partition KEY.
Partitionnement RANGE : La gestion des partitions est effectuée en fonction de la valeur d'un certain champ. Elle est partitionnée lors de la création directe d'une table. par exemple :
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date, salary int ) partition by range(salary) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than maxvalue );
Partition LIST : similaire à la partition RANG, la différence est que la partition liste est une valeur de hachage, Le partitionnement RANG est basé sur une certaine plage de champs. Par exemple :
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by list(deptno) ( partition p1 values in (10,15), partition p2 values in (20,25), partition p3 values in (30,35) );
Partition HASH : garantit que les données sont réparties uniformément dans les partitions de bibliographies prédéfinies, et que le les partitions sont spécifiées en fonction des valeurs de colonne et du nombre de partitions. Par exemple :
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by hash(year(birthdate)) partitions 4;
Partition KEY : similaire à la partition HASH, différente de la partition KEY qui ne prend en charge que le calcul d'une ou plusieurs colonnes , MySQL Le serveur fournit sa propre fonction de hachage, qui doit avoir une ou plusieurs colonnes contenant des valeurs entières. Par exemple :
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by key(birthdate) partitions 4;
【Méthode d'opération de gestion des partitions】
Supprimer la partition :
alter table emp drop partition p1;
Les partitions de hachage ou de clé ne peuvent pas être supprimées.
Supprimer plusieurs partitions à la fois, altérer table emp drop partition p1,p2;
Ajouter une partition :
alter table emp ajouter partition (partition p3 valeurs inférieures à (4000));
alter table empl ajouter partition ( partition p3 valeurs dans (40));
Réorganiser la partition :
Le mot-clé Reorganizepartition peut modifier tout ou partie des partitions de la table sans perdre ses données. La portée globale de la partition doit être cohérente avant et après la décomposition.
altérer table te
réorganiser la partition p1 en
(
partition p1 valeurs inférieures à (100) ,
partition p3 valeurs inférieures à (1000)
); ----Aucune perte de données
Fusionner des partitions :
Fusionner des partitions : Fusionner 2 partitions en une seule.
modifier tablete
réorganiser la partition p1,p3 en
(partition p1 valeurs inférieures à (1000));
----Aucune perte de données
Redéfinir la table de partition de hachage :
Alter table emp partition by hash(salary ) les partitions 7;
---- ne seront pas perdues Données
Redéfinir la table de partition de plage :
Alter table partition emppargamme(salaire)
(
partition p1 valeurs inférieure à (2000),
partition p2 valeurs inférieure à (4000 )
) ----Aucune perte de données
Supprimer toutes les partitions de la table :
Alter table emp removepartitioning;--Aucune perte de données
Reconstruire la partition :
Cela a le même effet que de supprimer d'abord tous les enregistrements enregistrés dans la partition, puis de les réinsérer. effet. Il peut être utilisé pour défragmenter les partitions.
ALTER TABLE emp reconstruction partitionp1,p2;
Optimiser le partitionnement :
Si un grand nombre de lignes sont supprimées d'une partition, ou si une partition avec une variable Si la longueur de la ligne (c'est-à-dire s'il y a des colonnes de type VARCHAR, BLOB ou TEXT) a été modifiée plusieurs fois, vous pouvez utiliser "ALTER TABLE ... OPTIMIZE PARTITION" pour récupérer l'espace inutilisé et défragmenter les données de la partition. déposer.
ALTER TABLE emp optimiser partition p1,p2;
Partition d'analyse :
Lire et enregistrer le distribution des clés de la partition.
ALTER TABLE emp analyser partition p1,p2;
Corriger la partition :
Corriger celle endommagée Partition.
ALTER TABLE emp repairpartition p1,p2;
Vérification des partitions :
Les partitions peuvent être vérifiées de la même manière qu'en utilisant CHECK TABLE pour un non- table partitionnée.
ALTER TABLE emp CHECK partition p1,p2;
这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。
【分区实践】
1. 创建分区表和不分区表:
-- 创建分区表 CREATE TABLE part_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null) PARTITION BY RANGE(year(c3)) (PARTITION p0 VALUES LESS THAN (1995), PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) , PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) , PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) , PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) , PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010), PARTITION p11 VALUES LESS THAN (MAXVALUE) );
-- 创建没有分区表 CREATE TABLE nopart_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null)
2. 创建大数据操作环境。为了测试结果的准确度提高,需要表中存在大数据,通过以下事务可在数据表中创建800万条数据:
-- 创建生成数据事物
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end;
执行事务:call load_part_tab(); ,因为执行此事务执行的时间很长,我只在表中插入了283304条数据。
创建完成一张表后,可以将该表的数据复制到未分区表,这样执行速度会很快:
insert into test.nopart_tab select * from test.part_tab
3. 查看分区表分区结构:
-- 查询分区情况 select partition_name part, partition_expression expr, partition_description descr, table_rows from information_schema.partitions where table_schema = schema() and table_name='part_tab';
执行结果:
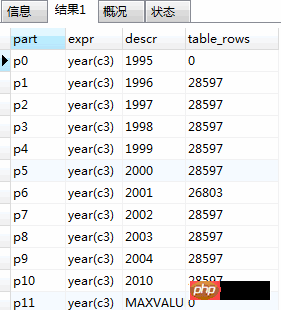
3. 测试速度:
执行分区表查询语句:
select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

执行未分区表查询语句:
select count(*) from nopart_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

从时间对比可以看出,同样的查询语句,分区表执行速度在20ms左右,未分区表在175ms左右,执行速度相差8倍左右,因此得出结论:分区表的执行速度要比未分区表执行速度快。
【分区局限性】
1. MySQL分区处理NULL值的方式
如果分区键所在列没有notnull约束。
如果是range分区表,那么null行将被保存在范围最小的分区。
如果是list分区表,那么null行将被保存到list为0的分区。
在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。
2. La clé de partition doit être de type INT, ou renvoyer le type INT via une expression, qui peut être NULL. La seule exception est que lorsque le type de partition est le partitionnement KEY, vous pouvez utiliser d'autres types de colonnes comme clés de partition (à l'exception des colonnes BLOB ou TEXT).
3. Créez un index sur la clé de partition de la table de partition, puis cet index sera également partitionné Il n'y a pas de global. index pour la clé de partition.
4. Seules les partitions RANG et LIST peuvent être sous-partitionnées, les partitions HASH et KEY ne peuvent pas être sous-partitionnées.
5. Les tables temporaires ne peuvent pas être partitionnées.
Ce qui précède est le contenu de l'expérience d'optimisation Mysql (1) - partition Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !