
Maison >base de données >tutoriel mysql >【MySQL】Architecture logique MySQL
【MySQL】Architecture logique MySQL

- 黄舟original
- 2017-02-25 10:26:211692parcourir
Si vous pouvez créer dans votre esprit un diagramme d'architecture montrant comment les différents composants de MySQL fonctionnent ensemble, cela vous aidera à comprendre en profondeur le serveur MySQL.
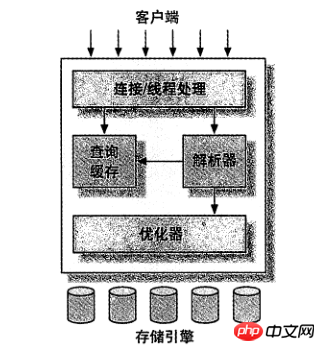
Le service de niveau supérieur n'est pas unique à MySQL, la plupart des outils client/serveur basés sur le réseau ont une architecture similaire. Tels que le traitement de la connexion, l'authentification des autorisations, la sécurité, etc.
L'architecture de deuxième couche est la partie la plus intéressante de MySQL. La plupart des fonctions de base du service MySQL se trouvent dans cette couche, y compris l'analyse des requêtes, l'analyse, l'optimisation, la mise en cache et toutes les fonctions intégrées (par exemple, les fonctions de date, d'heure, mathématiques et de chiffrement). cette couche. Implémentation : procédures stockées, déclencheurs, vues, etc.
La troisième couche contient le moteur de stockage. Le moteur de stockage est responsable du stockage et de la récupération des données dans MySQL. Comme divers systèmes de fichiers sous GNU/Linux, chaque moteur de stockage a ses avantages et ses inconvénients. Le serveur communique avec le moteur de stockage via des API. Ces interfaces masquent les différences entre les différents moteurs de stockage, rendant ces différences transparentes pour le processus de requête de couche supérieure. L'API du moteur de stockage contient plus d'une douzaine de fonctions de bas niveau permettant d'effectuer des opérations telles que « démarrer une transaction » ou « extraire une ligne d'enregistrements en fonction de la clé primaire ». Mais le moteur de stockage n'analysera pas SQL (remarque : InnoDB est une exception, il analysera les définitions de clés étrangères, car le serveur MySQL lui-même n'implémente pas cette fonction), et les différents moteurs de stockage ne communiqueront pas entre eux, mais répondront simplement. à la requête du serveur de couche supérieure.
Gestion et sécurité des connexions
Chaque connexion client aura un thread dans le processus serveur. La requête pour cette connexion ne sera exécutée que dans ce thread séparé, qui ne peut se relayer que lors de l'exécution. un certain cœur de processeur ou processeur. Le serveur sera responsable de la mise en cache des threads, il n'est donc pas nécessaire de créer ou de détruire des threads pour chaque nouvelle connexion. (Remarque : MySQL 5.5 ou version ultérieure fournit une API qui prend en charge le plug-in de pool de threads, qui peut utiliser un petit nombre de threads dans le pool pour desservir un grand nombre de connexions).
Lorsqu'un client (application) se connecte au serveur MySQL, le serveur doit l'authentifier. L'authentification est basée sur le nom d'utilisateur, les informations d'origine de l'hôte et le mot de passe. Si vous utilisez une connexion SSL (Secure Socket), vous pouvez également utiliser l'authentification par certificat X.509. Une fois que le client se connecte avec succès, le serveur continuera à vérifier si le client a l'autorisation pour une requête spécifique (par exemple, si le client est autorisé à exécuter une instruction SELECT sur la table Country de la base de données mondiale).
Optimisation et exécution
MySQL analysera la requête et créera une structure de données interne (arbre d'analyse), puis y effectuera diverses optimisations, notamment la réécriture de la requête, la détermination de l'ordre de lecture du table, ainsi que le choix des index appropriés, etc. Les utilisateurs peuvent influencer le processus de prise de décision de l'optimiseur grâce à des indices de mots clés spéciaux. Vous pouvez également demander à l'optimiseur d'expliquer divers facteurs du processus d'optimisation, afin que les utilisateurs puissent savoir comment le serveur prend des décisions d'optimisation, et fournir une référence de référence pour aider les utilisateurs à reconstruire les requêtes et le schéma, et à modifier les configurations associées pour rendre l'application aussi performante. fonctionner le plus efficacement possible.
L'optimiseur ne se soucie pas du moteur de stockage utilisé, mais le moteur de stockage a un impact sur l'optimisation des requêtes. L'optimiseur demandera au moteur de stockage de fournir des informations sur la capacité ou le coût d'une opération spécifique, ainsi que des informations statistiques sur les données des tables, etc. Par exemple, certains index de certains moteurs de stockage peuvent être optimisés pour certaines requêtes.
Pour les instructions SELECT, avant d'analyser la requête, le serveur vérifiera d'abord le cache de requête (Query Cache). Si la requête correspondante peut y être trouvée, le serveur n'a pas besoin d'effectuer l'intégralité du processus de requête. analyse, optimisation et exécution. Au lieu de cela, le résultat défini dans le cache de requêtes est renvoyé directement.
Si vous pouvez créer dans votre esprit un diagramme d'architecture montrant comment les différents composants de MySQL fonctionnent ensemble, cela vous aidera à comprendre en profondeur le serveur MySQL.
Le service de niveau supérieur n'est pas unique à MySQL, la plupart des outils client/serveur basés sur le réseau ont une architecture similaire. Tels que le traitement de la connexion, l'authentification des autorisations, la sécurité, etc.
L'architecture de deuxième couche est la partie la plus intéressante de MySQL. La plupart des fonctions de service principales de MySQL se trouvent dans cette couche, y compris l'analyse des requêtes, l'analyse, l'optimisation, la mise en cache et toutes les fonctions intégrées (par exemple, les fonctions de date, d'heure, mathématiques et de chiffrement). cette couche. Implémentation : procédures stockées, déclencheurs, vues, etc.
La troisième couche contient le moteur de stockage. Le moteur de stockage est responsable du stockage et de la récupération des données dans MySQL. Comme divers systèmes de fichiers sous GNU/Linux, chaque moteur de stockage a ses avantages et ses inconvénients. Le serveur communique avec le moteur de stockage via des API. Ces interfaces masquent les différences entre les différents moteurs de stockage, rendant ces différences transparentes pour le processus de requête de couche supérieure. L'API du moteur de stockage contient plus d'une douzaine de fonctions de bas niveau permettant d'effectuer des opérations telles que « démarrer une transaction » ou « extraire une ligne d'enregistrements en fonction de la clé primaire ». Mais le moteur de stockage n'analysera pas SQL (remarque : InnoDB est une exception, il analysera les définitions de clés étrangères, car le serveur MySQL lui-même n'implémente pas cette fonction), et les différents moteurs de stockage ne communiqueront pas entre eux, mais répondront simplement. à la requête du serveur de couche supérieure.
Gestion et sécurité des connexions
Chaque connexion client aura un thread dans le processus serveur. La requête pour cette connexion ne sera exécutée que dans ce thread séparé, qui ne peut se relayer que lors de l'exécution. un certain cœur de processeur ou processeur. Le serveur sera responsable de la mise en cache des threads, il n'est donc pas nécessaire de créer ou de détruire des threads pour chaque nouvelle connexion. (Remarque : MySQL 5.5 ou version ultérieure fournit une API qui prend en charge le plug-in de pool de threads, qui peut utiliser un petit nombre de threads dans le pool pour desservir un grand nombre de connexions).
Lorsqu'un client (application) se connecte au serveur MySQL, le serveur doit l'authentifier. L'authentification est basée sur le nom d'utilisateur, les informations d'origine de l'hôte et le mot de passe. Si vous utilisez une connexion SSL (Secure Socket), vous pouvez également utiliser l'authentification par certificat X.509. Une fois que le client se connecte avec succès, le serveur continuera à vérifier si le client a l'autorisation pour une requête spécifique (par exemple, si le client est autorisé à exécuter une instruction SELECT sur la table Country de la base de données mondiale).
Optimisation et exécution
MySQL analysera la requête et créera une structure de données interne (arbre d'analyse), puis y effectuera diverses optimisations, notamment la réécriture de la requête, la détermination de l'ordre de lecture du table, ainsi que le choix des index appropriés, etc. Les utilisateurs peuvent influencer le processus de prise de décision de l'optimiseur grâce à des indices de mots clés spéciaux. Vous pouvez également demander à l'optimiseur d'expliquer divers facteurs du processus d'optimisation, afin que les utilisateurs puissent savoir comment le serveur prend des décisions d'optimisation, et fournir une référence de référence pour aider les utilisateurs à reconstruire les requêtes et le schéma, et à modifier les configurations associées pour rendre l'application aussi performante. fonctionner le plus efficacement possible.
L'optimiseur ne se soucie pas du moteur de stockage utilisé, mais le moteur de stockage a un impact sur l'optimisation des requêtes. L'optimiseur demandera au moteur de stockage de fournir des informations sur la capacité ou le coût d'une opération spécifique, ainsi que des informations statistiques sur les données des tables, etc. Par exemple, certains index de certains moteurs de stockage peuvent être optimisés pour certaines requêtes.
Pour les instructions SELECT, avant d'analyser la requête, le serveur vérifiera d'abord le cache de requête (Query Cache). Si la requête correspondante peut y être trouvée, le serveur n'a pas besoin d'effectuer l'intégralité du processus de requête. analyse, optimisation et exécution. Au lieu de cela, le résultat défini dans le cache de requêtes est renvoyé directement.
Ce qui précède est le contenu de l'architecture logique [MySQL] MySQL. Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois (www.php.cn) !