
Maison >base de données >tutoriel mysql >Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes
Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes

- 黄舟original
- 2017-02-23 10:51:521399parcourir
Cet article présentera en détail les causes des caractères tronqués de MySQL et des solutions spécifiques
Les raisons des caractères tronqués de MySQL
Pour comprendre pourquoi les caractères tronqués apparaissent, nous devons d'abord comprendre : à partir du moment où le client initie une requête, jusqu'au moment où MySQL stocke les données, puis lorsque le client récupère les données de la table la prochaine fois, quels liens auront un encodage /comportement de décodage. Afin de mieux expliquer ce processus, le blogueur a réalisé deux organigrammes, correspondant aux deux étapes de dépôt et de retrait.
Processus de conversion d'encodage pour le stockage dans MySQL
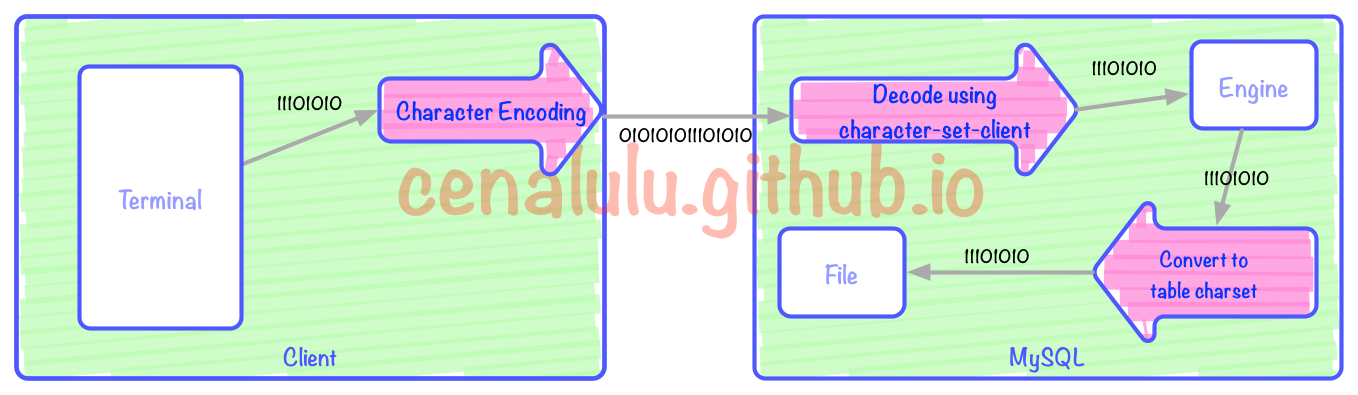
Il existe trois processus d'encodage/décodage dans l'image ci-dessus (flèches rouges). Les trois flèches rouges correspondent respectivement à : l'encodage client, le décodage MySQL Server et la conversion de l'encodage Client vers l'encodage table. Le Terminal peut être un Bash, une page Web ou une APP. Dans cet article, nous supposons que Bash est notre terminal, qui est l'interface de saisie et d'affichage du côté utilisateur. Le comportement correspondant à chaque case de la figure est le suivant :
Utilisez la méthode de saisie dans le terminal pour saisir
Le terminal le convertit dans un flux binaire selon le codage des caractères
Le flux binaire est transmis au serveur MySQL via le client MySQL
Le serveur décode via des caractères- set-client
Déterminez si le jeu de caractères-client est cohérent avec le jeu de caractères de la table cible
-
S'ils sont incohérents, effectuez une conversion de codage de caractères du jeu de caractères client en jeu de caractères de table
Enregistrez le flux binaire de codage de caractères converti dans un fichier
Le processus de conversion de codage de récupération des données de la table MySQL
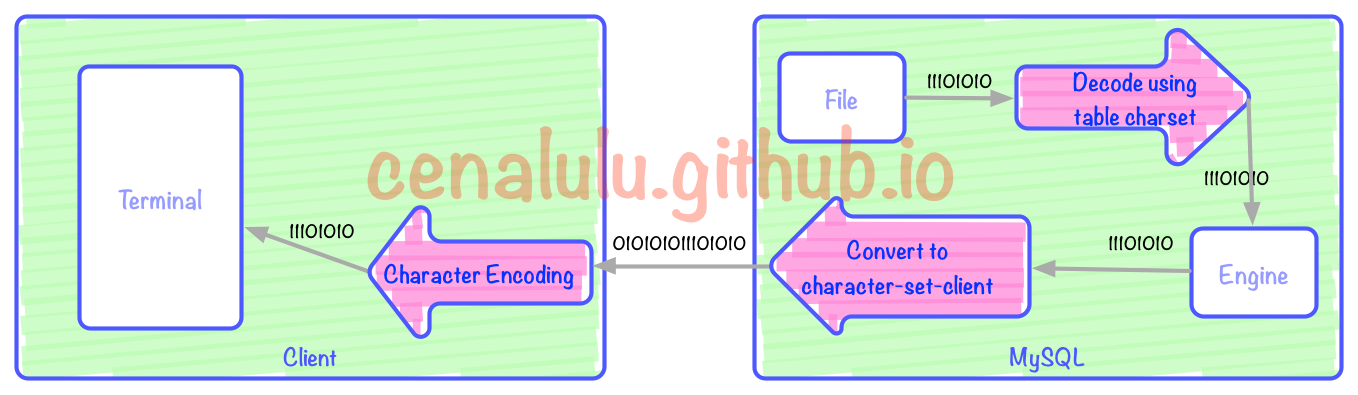
L'image ci-dessus comporte trois processus d'encodage/décodage (flèches rouges). Les trois flèches rouges dans la figure ci-dessus correspondent respectivement à : l'affichage du décodage du client, l'encodage du serveur MySQL en fonction du jeu de caractères client et la conversion de l'encodage de table en codage client du jeu de caractères.
Lire le flux de données binaires à partir du fichier
Décoder à l'aide du codage du jeu de caractères de table
Convertir les données à l'encodage du jeu de caractères-client
Utilisez le jeu de caractères-client pour l'encoder dans un flux binaire
Le serveur est transmis à le serveur via le réseau Le client distant
le client affiche les résultats de la requête via le codage de caractères configuré dans bash
La raison pour laquelle les caractères MySQL sont tronqués
1. Le codage des liens correspondants lors du dépôt et du retrait est incohérent
Il est évident que cela entraînera des codes tronqués. Nous numérotons les jeux de caractères utilisés dans les trois étapes de codage et de décodage de l'étape de stockage comme C1, C2 et C3 (de gauche à droite sur la figure 1) ; les trois jeux de caractères utilisés dans l'étape de récupération sont numérotés comme C1', C2 ; ', C3' (de gauche à droite). Ensuite, lors de la sauvegarde, bash C1 utilise l'encodage UTF-8, mais lors de sa suppression, nous utilisons le terminal Windows (la valeur par défaut est l'encodage GBK) pour C1', donc le résultat sera presque certainement tronqué. Ou lors de l'enregistrement sur MySQL, les noms d'ensemble utf8(C2) sont utilisés, mais lors de la suppression, les noms d'ensemble gbk(C2') sont utilisés, alors le résultat doit être tronqué
2. Trois étapes dans un seul processus Le codage des étapes est incohérent
C'est-à-dire que parmi les trois étapes dans la même direction dans l'une des images ci-dessus, tant que le codage de deux étapes ou plus est incohérent, des erreurs de codage et de décodage peut survenir. Si la conversion de codage sans perte ne peut pas être effectuée entre les deux jeux de caractères différents (décrits en détail ci-dessous), des caractères tronqués apparaîtront définitivement. Par exemple : notre shell est codé en UTF8, le client de jeu de caractères de MySQL est configuré en GBK et la structure de la table est Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes=utf8, alors il y aura sans aucun doute des caractères tronqués.
Ici, nous allons simplement démontrer cette situation
master [localhost] {msandbox} (test) > create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_utf8 (id int primary key auto_increment, char_col varchar(50)) Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes = utf8;
Query OK, 0 rows affected (0.04 sec)
master [localhost] {msandbox} (test) > set names gbk;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_utf8 (char_col) values ('中文');
Query OK, 1 row affected, 1 warning (0.01 sec)
master [localhost] {msandbox} (test) > show warnings;
+---------+------+---------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: '\xAD\xE6\x96\x87' for column 'char_col' at row 1 |
+---------+------+---------------------------------------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col from Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_utf8;
+----+----------------+----------+
| id | hex(char_col) | char_col |
+----+----------------+----------+
| 1 | E6B6933FE69E83 | �?�� |
+----+----------------+----------+
1 row in set (0.01 sec)À propos de l'encodage/décodage MySQL
Puisque les systèmes sont transmis selon des flux binaires, transférez directement cette chaîne. Stockez simplement le flux binaire directement dans le fichier table. Pourquoi devons-nous effectuer deux opérations d’encodage et de décodage avant de stocker ?
La raison du codage et du décodage client vers serveur est que MySQL doit effectuer une analyse syntaxique et lexicale sur le flux binaire entrant. Si nous n'effectuons pas d'analyse et de vérification du codage, nous ne pouvons même pas savoir si le flux binaire transmis est une insertion ou une mise à jour.
L'encodage et le décodage de File to Engine consistent à connaître la situation de segmentation des mots dans le flux binaire. Pour donner un exemple simple : nous voulons récupérer les deux premiers caractères d'un champ de la table, et exécuter une instruction du formulaire select left(col,2) from table Le moteur de stockage lit la valeur de la colonne dans le fichier. .E4B8ADE69687. Ainsi, à ce stade, si nous divisons cette valeur en trois mots E4B8, ADE6 et 9687 selon GBK, la valeur renvoyée au client devrait être E4B8ADE6 si nous la divisons en E4B8AD et E69687 selon UTF8, alors les deux mots E4B8ADE69687 ; devrait être retourné. On peut voir que si les données sont lues à partir du fichier de données et qu'aucun codage ou décodage n'est effectué, les opérations au niveau des caractères ne peuvent pas être effectuées à l'intérieur du moteur de stockage.
关于错进错出
在MySQL中最常见的乱码问题的起因就是把错进错出神话。所谓的错进错出就是,客户端(web或shell)的字符编码和最终表的字符编码格式不同,但是只要保证存和取两次的字符集编码一致就仍然能够获得没有乱码的输出的这种现象。但是,错进错出并不是对于任意两种字符集编码的组合都是有效的。我们假设客户端的编码是C,MySQL表的字符集编码是S。那么为了能够错进错出,需要满足以下两个条件
MySQL接收请求时,从C编码后的二进制流在被S解码时能够无损
MySQL返回数据是,从S编码后的二进制流在被C解码时能够无损
编码无损转换
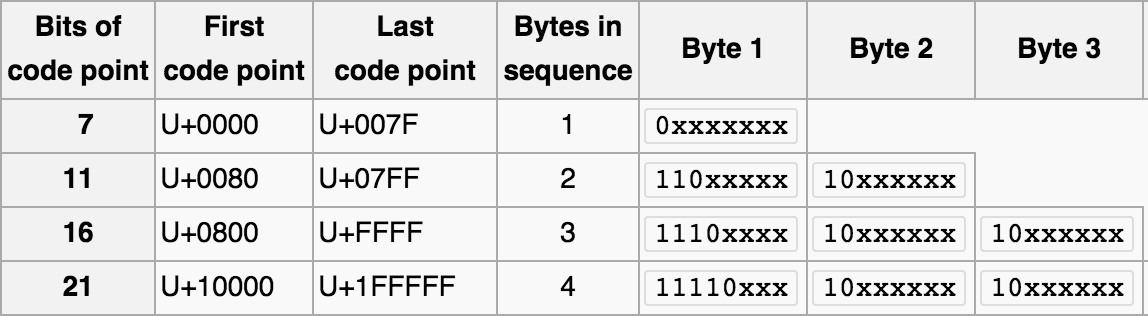
那么什么是有损转换,什么是无损转换呢?假设我们要把用编码A表示的字符X,转化为编码B的表示形式,而编码B的字形集中并没有X这个字符,那么此时我们就称这个转换是有损的。那么,为什么会出现两个编码所能表示字符集合的差异呢?如果大家看过博主之前的那篇 十分钟搞清字符集和字符编码,或者对字符编码有基础理解的话,就应该知道每个字符集所支持的字符数量是有限的,并且各个字符集涵盖的文字之间存在差异。UTF8和GBK所能表示的字符数量范围如下
GBK单个字符编码后的取值范围是:8140 - FEFE 其中不包括**7E,总共字符数在27000左右
UTF8单个字符编码后,按照字节数的不同,取值范围如下表:
由于UTF-8编码能表示的字符数量远超GBK。那么我们很容易就能找到一个从UTF8到GBK的有损编码转换。我们用字符映射器(见下图)找出了一个明显就不在GBK编码表中的字符,尝试存入到GBK编码的表中。并再次取出查看有损转换的行为
字符信息具体是:ਅ GURMUKHI LETTER A Unicode: U+0A05, UTF-8: E0 A8 85
在MySQL中存储的具体情况如下:
master [localhost] {msandbox} (test) > create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_gbk (id int primary key auto_increment, char_col varchar(50)) Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes = gbk;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > set names utf8;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_gbk (char_col) values ('ਅ');
Query OK, 1 row affected, 1 warning (0.01 sec)
master [localhost] {msandbox} (test) > show warnings;
+---------+------+-----------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: '\xE0\xA8\x85' for column 'char_col' at row 1 |
+---------+------+-----------------------------------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_gbk;
+----+---------------+----------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+---------------+----------+-----------------------+
| 1 | 3F | ? | 1 |
+----+---------------+----------+-----------------------+
1 row in set (0.00 sec)出错的部分是在编解码的第3步时发生的。具体见下图
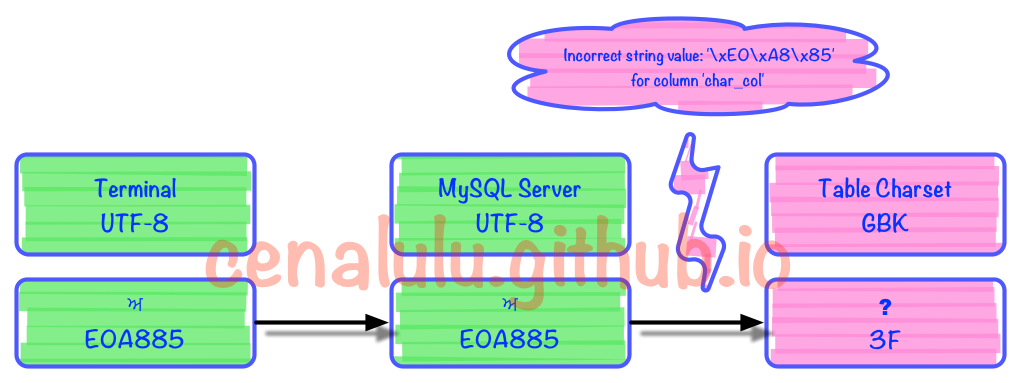
可见MySQL内部如果无法找到一个UTF8字符所对应的GBK字符时,就会转换成一个错误mark(这里是问号)。而每个字符集在程序实现的时候内部都约定了当出现这种情况时的行为和转换规则。例如:UTF8中无法找到对应字符时,如果不抛错那么就将该字符替换成� (U+FFFD)
那么是不是任何两种字符集编码之间的转换都是有损的呢?并非这样,转换是否有损取决于以下几点:
被转换的字符是否同时在两个字符集中
目标字符集是否能够对不支持字符,保留其原有表达形式
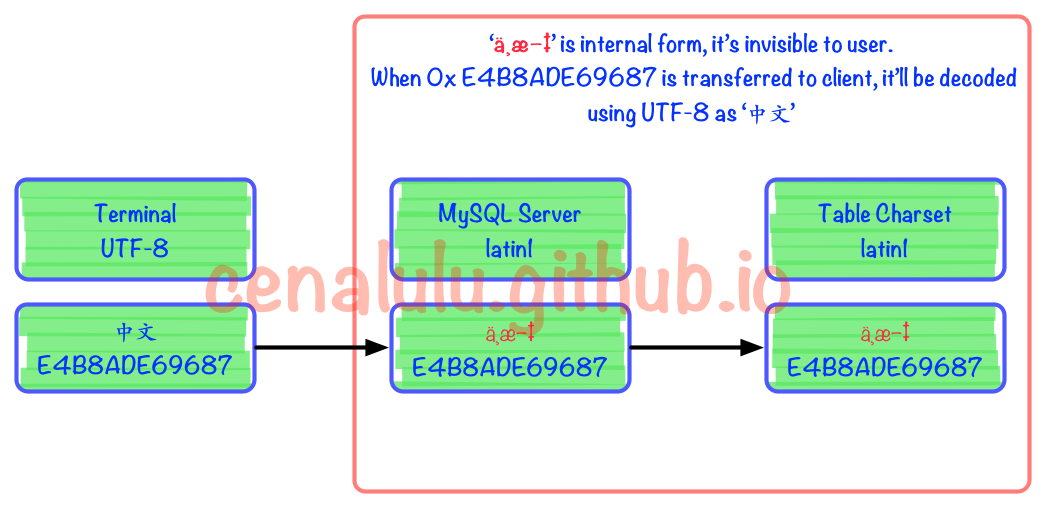
关于第一点,刚才已经通过实验来解释过了。这里来解释下造成有损转换的第二个因素。从刚才的例子我们可以看到由于GBK在处理自己无法表示的字符时的行为是:用错误标识替代,即0x3F。而有些字符集(例如latin1)在遇到自己无法表示的字符时,会保留原字符集的编码数据,并跳过忽略该字符进而处理后面的数据。如果目标字符集具有这样的特性,那么就能够实现这节最开始提到的错进错出的效果。
我们来看下面这个例子
master [localhost] {msandbox} (test) > create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test (id int primary key auto_increment, char_col varchar(50)) Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes = latin1;
Query OK, 0 rows affected (0.03 sec)
master [localhost] {msandbox} (test) > set names latin1;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test (char_col) values ('中文');
Query OK, 1 row affected (0.01 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col from Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test;
+----+---------------+----------+
| id | hex(char_col) | char_col |
+----+---------------+----------+
| 2 | E4B8ADE69687 | 中文 |
+----+---------------+----------+
2 rows in set (0.00 sec)具体流程图如下。可见在被MySQL Server接收到以后实际上已经发生了编码不一致的情况。但是由于Latin1字符集对于自己表述范围外的字符不会做任何处理,而是保留原值。这样的行为也使得错进错出成为了可能。
如何避免乱码
理解了上面的内容,要避免乱码就显得很容易了。只要做到“三位一体”,即客户端,MySQL character-set-client,table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes三个字符集完全一致就可以保证一定不会有乱码出现了。而对于已经出现乱码,或者已经遭受有损转码的数据,如何修复相对来说就会有些困难。下一节我们详细介绍具体方法。
如何修复已经编码损坏的数据
在介绍正确方法前,我们先科普一下那些网上流传的所谓的“正确方法”可能会造成的严重后果。
错误方法一
无论从语法还是字面意思来看:ALTER TABLE ... CHARSET=xxx 无疑是最像包治乱码的良药了!而事实上,他对于你已经损坏的数据一点帮助也没有,甚至连已经该表已经创建列的默认字符集都无法改变。我们看下面这个例子
master [localhost] {msandbox} (test) > show create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test;
+--------------+--------------------------------+
| Table | Create Table |
+--------------+--------------------------------+
| Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test | CREATE TABLE `Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`char_col` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1 |
+--------------+--------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > alter table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes=gbk;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
master [localhost] {msandbox} (test) > show create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test;
+--------------+--------------------------------+
| Table | Create Table |
+--------------+--------------------------------+
| Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test | CREATE TABLE `Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`char_col` varchar(50) CHARACTER SET latin1 DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=gbk |
+--------------+--------------------------------+
1 row in set (0.00 sec)可见该语法紧紧修改了表的默认字符集,即只对以后创建的列的默认字符集产生影响,而对已经存在的列和数据没有变化。
错误方法二
ALTER TABLE … CONVERT TO CHARACTER SET … 的相较于方法一来说杀伤力更大,因为从 官方文档的解释 他的作用就是用于对一个表的数据进行编码转换。下面是文档的一小段摘录:
To change the table default character set and all character columns (CHAR, VARCHAR, TEXT) to a new character set, use a statement like this:
ALTER TABLE tbl_name
CONVERT TO CHARACTER SET Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_name [COLLATE collation_name];
而实际上,这句语法只适用于当前并没有乱码,并且不是通过错进错出的方法保存的表。。而对于已经因为错进错出而产生编码错误的表,则会带来更糟的结果。我们用一个实际例子来解释下,这句SQL实际做了什么和他会造成的结果。假设我们有一张编码是latin1的表,且之前通过错进错出存入了UTF-8的数据,但是因为通过terminal仍然能够正常显示。即上文错进错出章节中举例的情况。一段时间使用后我们发现了这个错误,并打算把表的字符集编码改成UTF-8并且不影响原有数据的正常显示。这种情况下使用alter table convert to character set会有这样的后果:
master [localhost] {msandbox} (test) > create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 (id int primary key auto_increment, char_col varchar(50)) Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes = latin1;
Query OK, 0 rows affected (0.01 sec)
master [localhost] {msandbox} (test) > set names latin1;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 (char_col) values ('这是中文');
Query OK, 1 row affected (0.01 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1;
+----+--------------------------+--------------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+--------------------------+--------------+-----------------------+
| 1 | E8BF99E698AFE4B8ADE69687 | 这是中文 | 12 |
+----+--------------------------+--------------+-----------------------+
1 row in set (0.01 sec)
master [localhost] {msandbox} (test) > alter table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 convert to character set utf8;
Query OK, 1 row affected (0.04 sec)
Records: 1 Duplicates: 0 Warnings: 0
master [localhost] {msandbox} (test) > set names utf8;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1;
+----+--------------------------------------------------------+-----------------------------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+--------------------------------------------------------+-----------------------------+-----------------------+
| 1 | C3A8C2BFE284A2C3A6CB9CC2AFC3A4C2B8C2ADC3A6E28093E280A1 | 这是ä¸æ–‡ | 12 |
+----+--------------------------------------------------------+-----------------------------+-----------------------+
1 row in set (0.00 sec)从这个例子我们可以看出,对于已经错进错出的数据表,这个命令不但没有起到“拨乱反正”的效果,还会彻底将数据糟蹋,连数据的二进制编码都改变了。
正确的方法一 Dump & Reload
这个方法比较笨,但也比较好操作和理解。简单的说分为以下三步:
通过错进错出的方法,导出到文件
用正确的字符集修改新表
将之前导出的文件导回到新表中
还是用上面那个例子举例,我们用UTF-8将数据“错进”到latin1编码的表中。现在需要将表编码修改为UTF-8可以使用以下命令
shell> mysqldump -u root -p -d --skip-set-Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes --default-character-set=utf8 test Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 > data.sql #确保导出的文件用文本编辑器在UTF-8编码下查看没有乱码 shell> mysql -uroot -p -e 'create table Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 (id int primary key auto_increment, char_col varchar(50)) Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes = utf8' test shell> mysql -uroot -p --default-character-set=utf8 test < data.sql
正确的方法二 Convert to Binary & Convert Back
这种方法比较取巧,用的是将二进制数据作为中间数据的做法来实现的。由于,MySQL再将有编码意义的数据流,转换为无编码意义的二进制数据的时候并不做实际的数据转换。而从二进制数据准换为带编码的数据时,又会用目标编码做一次编码转换校验。通过这两个特性就相当于在MySQL内部模拟了一次“错出”,将乱码“拨乱反正”了。
还是用上面那个例子举例,我们用UTF-8将数据“错进”到latin1编码的表中。现在需要将表编码修改为UTF-8可以使用以下命令
mysql> ALTER TABLE Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 MODIFY COLUMN char_col VARBINARY(50); mysql> ALTER TABLE Apprenez à comprendre et à résoudre les problèmes tronqués de MySQL en 10 minutes_test_latin1 MODIFY COLUMN char_col varchar(50) character set utf8;
以上就是10分钟学会理解和解决MySQL乱码问题的内容,更多相关内容请关注PHP中文网(www.php.cn)!