
Maison >base de données >tutoriel mysql >JDBC - système de gestion de base de données
JDBC - système de gestion de base de données

- 黄舟original
- 2017-02-11 11:12:012469parcourir
1-Présentation de JDBC
Préface : Persistance des données
Persistance : Enregistrez les données sur un périphérique de stockage hors tension pour une utilisation ultérieure. Dans la plupart des cas, en particulier pour les applications de niveau entreprise, la persistance des données signifie sauvegarder les données en mémoire sur le disque dur et les « solidifier », et le processus de mise en œuvre de la persistance est principalement complété par diverses bases de données relationnelles.
La principale application de la persistance est de stocker des données en mémoire dans une base de données relationnelle. Bien entendu, elles peuvent également être stockées dans des fichiers disque et des fichiers de données XML.
Technologie de stockage de données en Java
En Java, la technologie d'accès aux bases de données peut être divisée dans les catégories suivantes :
JDBC accède directement à la base de données
Technologie JDO
Outils O/R tiers, tels que Hibernate, ibatis, etc.
JDBC C'est la pierre angulaire de l'accès de Java aux bases de données JDO, Hibernate, etc. pour mieux encapsuler JDBC.
Bases de JDBC
JDBC (Java Database Connectivity) est une interface publique pour l'accès et le fonctionnement universels des bases de données SQL, indépendantes d'un système de gestion de base de données spécifique ( Un ensemble d'API) qui définit les bibliothèques de classes Java standard (java.sql, javax.sql) utilisées pour accéder aux bases de données. Grâce à cette bibliothèque de classes, vous pouvez facilement accéder aux ressources de la base de données de manière standard. Cette approche protège certains détails des développeurs.
L'objectif de JDBC est de permettre aux programmeurs Java d'utiliser JDBC pour se connecter à n'importe quel système de base de données fournissant un pilote JDBC, afin que les programmeurs n'aient pas besoin d'avoir trop de connaissances sur les caractéristiques d'un système spécifique. système de base de données. Cela simplifie et accélère considérablement le processus de développement.
Architecture JDBC
L'interface JDBC (API) comprend deux niveaux :
Orienté Application API : API Java, interface abstraite, utilisée par les développeurs d'applications (se connecter à la base de données, exécuter des instructions SQL et obtenir des résultats).
API orientée base de données : API de pilote Java, permettant aux développeurs de développer des pilotes de base de données.
JDBC est un ensemble d'interfaces fournies par Sun pour les opérations de base de données. Les programmeurs Java n'ont besoin de programmer que pour cet ensemble d'interfaces. Différents fournisseurs de bases de données doivent fournir différentes implémentations pour cet ensemble d'interfaces. Un ensemble de différentes implémentations sont des pilotes pour différentes bases de données. ——Programmation orientée interface
Classification des pilotes JDBC.
Pilote JDBC : une bibliothèque de classes de classes d'implémentation JDBC produites par divers fournisseurs de bases de données selon les spécifications JDBC
Il existe quatre types de pilotes JDBC au total :
Catégorie 1 : Pont JDBC-ODBC.
La deuxième catégorie : quelques API locales et quelques pilotes Java.
La troisième catégorie : pilote Java pur réseau JDBC.
Catégorie 4 : Pilote Java pur pour les protocoles locaux.
Les troisième et quatrième catégories sont de purs pilotes Java. Par conséquent, pour les développeurs Java, ils ont les meilleures performances et portabilité. de performance et de fonction.
Catégorie 1 : ODBC
L'accès anticipé à la base de données était basé sur l'appel de l'API propriétaire fournie par le fournisseur de la base de données. Afin de fournir une méthode d'accès unifiée sous la plate-forme Windows, Microsoft a lancé ODBC (Open Database Connectivity, connexion à une base de données ouverte) et a fourni une API ODBC. Les utilisateurs n'ont qu'à appeler l'API ODBC dans le programme, et le pilote ODBC convertira l'API. appel. Cela devient une demande d'appel à une base de données spécifique. Une application basée sur ODBC ne s'appuie sur aucun SGBD (système de gestion de base de données) pour les opérations de base de données et ne traite pas directement avec le SGBD. Toutes les opérations de base de données sont effectuées par le pilote ODBC de. le SGBD correspondant. En d'autres termes, qu'il s'agisse de FoxPro, Access
, la base de données MYSQL ou Oracle est accessible par l'API ODBC. On peut constater que le plus grand avantage d’ODBC est qu’il peut gérer toutes les bases de données de manière unifiée.
Pont JDBC-ODBC
Le pont JDBC-ODBC lui-même est également un pilote En utilisant ce pilote, vous pouvez utiliser l'API JDBC. accéder via la base de données ODBC. Ce mécanisme convertit en fait les appels JDBC standard en appels ODBC correspondants et accède à la base de données via ODBC. Parce qu'il nécessite plusieurs couches d'appels, il est inefficace d'utiliser le pont JDBC-ODBC pour accéder à la base de données. fourni. La classe d'implémentation du pont ODBC (sun.jdbc.odbc.JdbcOdbcDriver).
La deuxième catégorie : API locale partielle et pilote Java partiel
Ce type de pilote JDBC est écrit en Java, et il appelle l'API locale fournie par le fabricant de la base de données via ce type L'accès du pilote JDBC à la base de données réduit le nombre d'appels ODBC et améliore l'efficacité de l'accès à la base de données. De cette manière, un pilote JDBC local et l'API locale d'un fournisseur spécifique doivent être installés sur la machine du client.
La troisième catégorie : pilote Java pur réseau JDBC
Ce type de pilote utilise le serveur d'applications middleware pour accéder à la base de données. Le serveur d'applications agit comme une passerelle vers plusieurs bases de données, via laquelle les clients peuvent se connecter à différents serveurs de bases de données.
Le serveur d'applications possède généralement son propre protocole réseau. Le programme utilisateur Java envoie des appels JDBC au serveur d'applications via le pilote JDBC. Le serveur d'applications utilise le pilote de programme local pour accéder à la base de données afin de terminer le processus. demande.
Catégorie 4 : pilote Java pur pour les protocoles natifs
La plupart des fournisseurs de bases de données permettent déjà aux programmes clients de communiquer directement avec le protocole réseau pour la communication avec la base de données.
Ce type de pilote est entièrement écrit en Java. Grâce à la connexion Socket établie avec la base de données, il utilise le protocole réseau spécifique du fabricant pour convertir les appels JDBC en appels réseau directement connectés à l'API JDBC.
L'API JDBC est une série d'interfaces qui permettent aux applications de se connecter à des bases de données, d'exécuter des instructions SQL et d'obtenir des résultats renvoyés.
2-Obtenir la connexion à la base de données
Interface du pilote
java.sql. L'interface du pilote est l'interface que tous les pilotes JDBC doivent implémenter. Cette interface est fournie aux fournisseurs de bases de données. Différents fournisseurs de bases de données proposent différentes implémentations. Il n'est pas nécessaire d'accéder directement aux classes qui implémentent l'interface Driver dans le programme. Au lieu de cela, la classe du gestionnaire de pilotes (java.sql.DriverManager) les appelle. mise en œuvre.
Pilote Oracle : oracle.jdbc.driver.OracleDriver
Pilote mySql : com.mysql.jdbc.Driver
Chargement et enregistrement du pilote JDBC
Méthode 1 : Pour charger le pilote JDBC, vous devez appeler la méthode statique forName() de la classe Class et la transmettre le pilote JDBC à charger
Class.forName(“com.mysql.jdbc.Driver”);
Méthode 2 : Classe DriverManager Est la classe du gestionnaire de pilotes, responsable de la gestion du pilote
Habituellement, il n'est pas nécessaire d'appeler explicitement la méthode registerDriver() de la classe DriverManager pour enregistrer une instance de la classe driver, car les classes driver de l'interface Driver contiennent toutes des blocs de code statiques dans cette statique. bloc de code, la méthode DriverManager.registerDriver() sera appelée pour enregistrer une instance d'elle-même.
Vous pouvez appeler la méthode getConnection() de la classe DriverManager pour établir une connexion à la base de données.
Utilisateur, le mot de passe peut être communiqué à la base de données en utilisant "nom d'attribut = valeur d'attribut" ;
L'URL JDBC est utilisée pour identifier un pilote enregistré, gestionnaire de pilotes Sélectionnez le pilote correct via cette URL pour établir une connexion à la base de données.
Le standard URL JDBC se compose de trois parties, séparées par des deux-points.
jdbc : sous-protocole : sous-nom
Protocole : Le protocole dans l'URL JDBC est toujours jdbc.
Sous-protocole : le sous-protocole est utilisé pour identifier un pilote de base de données.
Sous-nom : Un moyen d'identifier la base de données. Le sous-nom peut changer selon différents sous-protocoles. Le but de l'utilisation du sous-nom est de fournir suffisamment d'informations pour localiser la base de données. Contient le nom d'hôte (correspondant à l'adresse IP du serveur), le numéro de port et le nom de la base de données.
URL JDBC de plusieurs bases de données couramment utilisées
jdbc:mysql://localhost:3306/test
Sous-protocole de protocole Sous-nom
Pour la connexion à la base de données Oracle, utilisez le formulaire suivant :
jdbc:oracle:thin:@localhost:1521:atguigu
Pour la connexion à la base de données SQLServer, utilisez le formulaire suivant :
jdbc:microsoft:sqlserver//localhost:1433; DatabaseName=sid
Pour la connexion à la base de données MYSQL , utilisez le formulaire suivant :
jdbc:mysql://localhost:3306/atguigu
Statement
Une fois le objet de connexion La connexion est obtenue, SQL ne peut pas encore être exécuté. Vous devez obtenir l'instruction de l'objet d'exécution à partir de l'objet Connection pour exécuter SQL.
Connection connection = getConnection(); Statement state = connection.createStatement(); int n = state.executeUpdate(“insert,update,delete…”);
où n est le nombre d'enregistrements qui seront affectés par l'ajout, la suppression ou la modification de la table Si une requête est exécutée, un ResultSet. L'objet de jeu de résultats est renvoyé.
Attaque par injection SQL
L'injection SQL est l'utilisation de certains systèmes qui ne vérifient pas complètement le données saisies par l'utilisateur. Injecter des segments ou des commandes d'instruction SQL illégales dans les données (telles que : SELECT user, password FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1'), utilisant ainsi le moteur SQL du système pour compléter un comportement malveillant. Pour Java, pour empêcher l'injection SQL, utilisez simplement PreparedStatement (étendu de Statement)
Remplacez simplement Statement .
3-Utiliser PreparedStatement
table de conversion de type de données
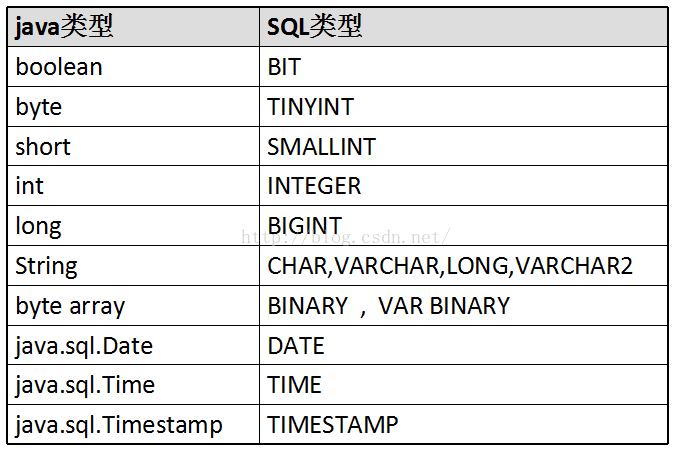
peut être appelé en appelant l'objet Connection La méthode PreparedStatement() obtient l'objet PreparedStatement.
L'interface PreparedStatement est une sous-interface de Statement, qui représente une instruction SQL précompilée.
Les paramètres de l'instruction SQL représentés par l'objet PreparedStatement sont représentés par des points d'interrogation (?). Appelez la méthode setXxx() de l'objet PreparedStatement pour définir ces paramètres. deux paramètres, le premier paramètre One est l'index (à partir de 1) du paramètre dans l'instruction SQL à définir, et le second est la valeur du paramètre dans l'instruction SQL à définir.
PreparedStatement vs Statement
Lisibilité et maintenabilité du code.
PreparedStatement peut maximiser les performances :
DBServer fournira une optimisation des performances pour les instructions préparées. Étant donné que les instructions précompilées peuvent être appelées à plusieurs reprises, le code d'exécution de l'instruction après avoir été compilé par le compilateur DBServer est mis en cache. Ensuite, la prochaine fois que l'instruction est appelée, tant qu'il s'agit de la même instruction précompilée, il n'est pas nécessaire de la compiler. , tant que les paramètres sont transmis directement, les instructions compilées seront exécutées dans le code d'exécution.
Dans l'instruction, même s'il s'agit de la même opération mais que le contenu des données est différent, l'instruction entière elle-même ne peut pas correspondre et la mise en cache de l'instruction n'a aucun sens. Le fait est qu'aucune base de données ne mettra en cache le code d'exécution compilé des instructions ordinaires. De cette manière, l'instruction entrante doit être compilée une fois à chaque exécution. (Vérification syntaxique, vérification sémantique, traduction en commandes binaires, mise en cache).
PreparedStatement peut empêcher l'injection SQL
Étapes pour se connecter à la base de données et à la table d'opération :
Enregistrer le chauffeur (ne le faites qu'une seule fois)
Établir une connexion (Connexion)
Créer une instruction pour exécuter SQL (PreparedStatement)
Instruction d'exécution
Gérer l'exécution résultats (ResultSet)
Ressources de publication
Connection conn = null;
PreparedStatement st=null;
ResultSet rs = null;
try {
//获得Connection
//创建PreparedStatement
//处理查询结果ResultSet
}catch(Exception e){
e.printStackTrance();
} finally {
//释放资源ResultSet,
// PreparedStatement ,
//Connection
释放ResultSet, PreparedStatement ,Connection。
数据库连接(Connection)是非常稀有的资源,用完后必须马上释放,如果Connection不能及时正确的关闭将导致系统宕机。Connection的使用原则是尽量晚创建,尽量早的释放。
4-使用ResultSet、ResultSetMetaData操作数据表:SELECT
ORM:Object Relation Mapping
表 与 类 对应
表的一行数据 与 类的一个对象对应
表的一列 与类的一个属性对应
ResultSet
通过调用 PreparedStatement 对象的 excuteQuery() 方法创建该对象。
ResultSet 对象以逻辑表格的形式封装了执行数据库操作的结果集,ResultSet 接口由数据库厂商实现。
ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象的 next() 方法移动到下一行。
ResultSet 接口的常用方法:
boolean next()
getString()
…
处理执行结果(ResultSet)
读取(查询)对应SQL的SELECT,返回查询结果
st = conn.createStatement();
String sql = "select id, name, age,birth from user";
rs = st.executeQuery(sql);
while (rs.next()) {
System.out.print(rs.getInt("id") + " \t ");
System.out.print(rs.getString("name") + " \t");
System.out.print(rs.getInt("age") + " \t");
System.out.print(rs.getDate(“birth") + " \t ");
System.out.println();}
}
关于Result的说明
1. 查询需要调用 Statement 的 executeQuery(sql) 方法,查询结果是一个 ResultSet 对象
2. 关于 ResultSet:代表结果集
ResultSet: 结果集. 封装了使用 JDBC 进行查询的结果. 调用 Statement 对象的 executeQuery(sql) 可以得到结果集.
ResultSet 返回的实际上就是一张数据表. 有一个指针指向数据表的第一条记录的前面.
3.可以调用 next() 方法检测下一行是否有效. 若有效该方法返回 true, 且指针下移. 相当于Iterator 对象的 hasNext() 和 next() 方法的结合体
4.当指针指向一行时, 可以通过调用 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值.
例如: getInt(1), getString("name")
5.ResultSet 当然也需要进行关闭.
MySQL BLOB 类型
MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据。
MySQL的四种BLOB类型(除了在存储的最大信息量上不同外,他们是等同的)。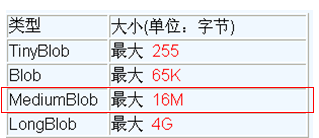
实际使用中根据需要存入的数据大小定义不同的BLOB类型。
需要注意的是:如果存储的文件过大,数据库的性能会下降。
ResultSetMetaData 类
可用于获取关于 ResultSet 对象中列的类型和属性信息的对象。
ResultSetMetaData meta = rs.getMetaData();
getColumnName(int column):获取指定列的名称
getColumnLabel(int column):获取指定列的别名
getColumnCount():返回当前 ResultSet 对象中的列数。
getColumnTypeName(int column):检索指定列的数据库特定的类型名称。
getColumnDisplaySize(int column):指示指定列的最大标准宽度,以字符为单位。
isNullable(int column):指示指定列中的值是否可以为 null。
isAutoIncrement(int column):指示是否自动为指定列进行编号,这样这些列仍然是只读的。
JDBC API 小结
java.sql.DriverManager est utilisé pour charger le pilote et obtenir la connexion à la base de données.
java.sql.Connection termine la connexion à une base de données spécifiée.
java.sql.Statement sert de conteneur pour les instructions d'exécution SQL dans une connexion donnée. Il contient deux sous-types importants.
Java.sql.PreparedSatement est utilisé pour exécuter des instructions SQL précompilées.
Java.sql.CallableStatement est utilisé pour exécuter des appels aux procédures stockées dans la base de données.
java.sql.ResultSet est le moyen d'obtenir le résultat d'une instruction donnée.
Deux pensées
L'idée de programmation orientée interface ;
Idée ORM : SQL doit être écrit en combinant les noms de colonnes et les noms d'attributs de table, et en faisant attention aux alias.
Deux technologies
Métadonnées JDBC : ResultSetMetaData ;
PropertyUtils : créez un objet via Class.newInstance() et assemblez la valeur de la colonne interrogée à l'objet créé via cette classe.
Traitement en 5 lots
Traitement par lots de JDBC déclarations Améliorer la vitesse de traitement.
Lorsque vous devez insérer ou mettre à jour des enregistrements par lots. Le mécanisme de mise à jour par lots de Java peut être utilisé, ce qui permet de soumettre simultanément plusieurs instructions à la base de données pour un traitement par lots. Il est généralement plus efficace que le traitement des soumissions individuelles.
Les instructions de traitement par lots JDBC incluent les deux méthodes suivantes :
addBatch(String) : ajouter du SQL instructions ou paramètres qui nécessitent un traitement par lots ;
executeBatch() : exécute les instructions de traitement par lots ; clearBatch() : efface les données mises en cache
Habituellement, nous rencontrons deux ; situations d'exécution par lots d'instructions SQL :
Traitement par lots de plusieurs instructions SQL
Transfert de paramètres par lots d'une instruction SQL
6-Pool de connexion à la base de données
La nécessité d'une connexion à la base de données JDBC pool
Lors du développement de programmes Web basés sur des bases de données, le modèle traditionnel suit essentiellement les étapes suivantes :
Établir une connexion à la base de données dans le programme principal (comme un servlet, des beans)
Effectuer des opérations SQL
Déconnecter la connexion à la base de données
Problèmes avec ce modèle de développement :
Les connexions à la base de données JDBC ordinaires sont obtenues à l'aide de DriverManager à chaque fois. vous établissez une connexion à la base de données, vous devez charger la connexion en mémoire puis vérifier le nom d'utilisateur et le mot de passe (cela prend 0,05 s à 1 s). Lorsqu'une connexion à la base de données est nécessaire, demandez-en une à la base de données, puis déconnectez-vous une fois l'exécution terminée. Cette approche consommera beaucoup de ressources et de temps. Les ressources de connexion à la base de données ne sont pas bien réutilisées. S'il y a des centaines, voire des milliers de personnes en ligne en même temps, les opérations fréquentes de connexion à la base de données occuperont beaucoup de ressources système et provoqueront même un crash du serveur. Chaque connexion à la base de données doit être déconnectée après utilisation. Sinon, si le programme ne se ferme pas en raison d'une anomalie, cela provoquera une fuite de mémoire dans le système de base de données et éventuellement le redémarrage de la base de données. Ce type de développement ne peut pas contrôler le nombre d'objets de connexion créés et les ressources système seront allouées sans considération. S'il y a trop de connexions, cela peut également provoquer des fuites de mémoire et des pannes de serveur.
Pool de connexions à la base de données (pool de connexions)
Pour résoudre les problèmes de connexion à la base de données dans le développement traditionnel, la technologie du pool de connexions à la base de données peut être utilisée.
L'idée de base du pool de connexions à la base de données est d'établir un "pool tampon" pour les connexions à la base de données. Mettez à l'avance un certain nombre de connexions dans le pool tampon. Lorsque vous devez établir une connexion à la base de données, il vous suffit d'en retirer une du « pool tampon » et de la remettre après utilisation.
Le pool de connexions à la base de données est responsable de l'allocation, de la gestion et de la libération des connexions à la base de données. Il permet aux applications de réutiliser une connexion à la base de données existante au lieu d'en établir une nouvelle.
Le pool de connexions à la base de données créera un certain nombre de connexions à la base de données et les placera dans le pool de connexions lors de l'initialisation. Le nombre de ces connexions à la base de données est défini par le nombre minimum de connexions à la base de données. Que ces connexions à la base de données soient utilisées ou non, le pool de connexions sera toujours assuré d'avoir au moins ce nombre de connexions. Le nombre maximum de connexions à la base de données dans le pool de connexions limite le nombre maximum de connexions que le pool de connexions peut occuper. Lorsque le nombre de connexions demandées par l'application au pool de connexions dépasse le nombre maximum de connexions, ces requêtes seront ajoutées au pool de connexions. file d'attente.
Fonctionnement du pooling de connexions de base de données
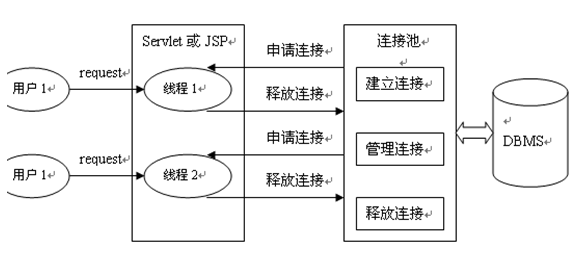
Avantages de la technologie de pooling de connexions de base de données
Réutilisation des ressources
Étant donné que les connexions à la base de données peuvent être réutilisées, une grande quantité de surcharge de performances causée par la création et la libération fréquentes de connexions est évité. D'autre part, en réduisant la consommation du système, cela augmente également la stabilité de l'environnement d'exploitation du système.
Vitesse de réponse du système plus rapide
Pendant le processus d'initialisation du pool de connexions à la base de données, plusieurs bases de données ont souvent été créées La connexion est placée dans le pool de connexions pour une utilisation ultérieure. À ce stade, le travail d’initialisation de la connexion est terminé. Pour le traitement des demandes métier, les connexions disponibles existantes sont directement utilisées pour éviter la surcharge de temps liée au processus d'initialisation et de libération de la connexion à la base de données, réduisant ainsi le temps de réponse du système.
Nouvelle méthode d'allocation des ressources
Pour les systèmes où plusieurs applications partagent la même base de données, vous pouvez Grâce à la configuration de Dans le pool de connexions à la base de données, le nombre maximum de connexions à la base de données disponibles pour une certaine application est limité afin d'empêcher une certaine application de monopoliser toutes les ressources de la base de données.
Gestion uniforme des connexions pour éviter les fuites de connexion à la base de données
Dans une implémentation de pool de connexions à la base de données relativement complète, vous pouvez selon En fonction du paramètre de délai d'attente de préoccupation, la connexion occupée est recyclée de force, évitant ainsi les fuites de ressources qui peuvent survenir lors des opérations normales de connexion à la base de données.
Deux pools de connexions à la base de données open source :
Le pool de connexions à la base de données JDBC est représenté par javax.sql.DataSource n'est qu'une interface, qui est généralement utilisée par le. serveur. (Weblogic, WebSphere, Tomcat) assure la mise en œuvre, et certaines organisations open source
assurent la mise en œuvre :
Pool de connexion à la base de données DBCP
Pool de connexion à la base de données C3P0
DataSource est généralement appelé source de données. Il contient deux parties : le pool de connexions et la gestion du pool de connexions. Il est d'usage d'appeler DataSource un pool de connexions.
DataSource est utilisé pour remplacer DriverManager pour obtenir une connexion, qui est rapide et peut grandement améliorer la vitesse d'accès à la base de données.
Source de données DBCP
DBCP est une implémentation de pool de connexions open source sous Apache Software Foundation. Le pool de connexions s'appuie sur un autre système open source sous l'organisation : Common-. pool . Si vous souhaitez utiliser cette implémentation de pool de connexions, vous devez ajouter les deux fichiers jar suivants au système :
Commons-dbcp.jar : pool de connexions. implémentation
Commons-pool.jar : bibliothèque de dépendances pour l'implémentation du pool de connexions
Le pool de connexions de Tomcat est implémenté à l'aide de ce pool de connexions. Le pool de connexions à la base de données peut être intégré au serveur d'applications ou utilisé indépendamment par l'application.
Exemple d'utilisation de source de données DBCP
Les sources de données sont différentes des connexions à la base de données. Il n'est pas nécessaire de créer plusieurs sources de données. l'ensemble de l'application n'a donc besoin que d'une seule source de données.
Lorsque l'accès à la base de données se termine, le programme ferme toujours la connexion à la base de données comme avant : conn.close(); Mais le code ci-dessus ne ferme pas la connexion physique de la base de données, il libère et renvoie uniquement la connexion à la base de données Un pool de connexions à la base de données est fourni.
7-Transaction de base de données
Transaction : un ensemble d'unités d'opération logiques qui transforment les données d'un état à un autre état.
Traitement des transactions (opération de transaction) : assurez-vous que toutes les transactions sont exécutées en tant qu'unité de travail. Même en cas d'échec, cette méthode d'exécution ne peut pas être modifiée. Lorsque plusieurs opérations sont effectuées dans une transaction, soit toutes les transactions sont validées et les modifications sont enregistrées de manière permanente ; soit le système de gestion de base de données abandonne toutes les modifications et la transaction entière est restaurée à son état initial.
Pour assurer la cohérence des données dans la base de données, la manipulation des données doit être constituée de groupes discrets d'unités logiques : lorsque tout est terminé, la cohérence des données peut être maintenue, et lorsque la partie If de l'opération échoue, la transaction entière doit être considérée comme une erreur et toutes les opérations à partir du point de départ doivent être rétablies à l'état de départ.
Attribut ACID (acide) de la transaction
Atomicité
L'atomicité signifie qu'une transaction est une unité de travail indivisible et que les opérations d'une transaction se produisent toutes ou qu'aucune ne se produit.
2. Cohérence
Une transaction doit faire passer la base de données d'un état de cohérence à un autre état de cohérence.
3. Isolement
L'isolement d'une transaction signifie que l'exécution d'une transaction ne peut pas être interférée par d'autres transactions, c'est-à-dire les opérations et les utilisations au sein d'un transaction Les données sont isolées des autres transactions simultanées et les transactions exécutées simultanément ne peuvent pas interférer les unes avec les autres.
4. Durabilité
La durabilité signifie qu'une fois qu'une transaction est soumise, ses modifications apportées aux données dans la base de données sont permanentes et les échecs de la base de données devraient être permanents. n'a aucun impact sur celui-ci
Traitement des transactions JDBC
Lorsque l'objet de connexion est créé, la transaction est automatiquement validé par défaut : chaque fois qu'une instruction SQL est exécutée, si l'exécution réussit, elle sera automatiquement soumise à la base de données et ne pourra pas être annulée.
Afin d'exécuter plusieurs instructions SQL en une seule transaction :
Appelez setAutoCommit(false) de l'objet Connection ; Pour annuler la transaction de validation automatique
Une fois que toutes les instructions SQL ont été exécutées avec succès, appelez la méthode commit() pour valider la transaction
Lorsqu'une exception se produit Quand, appelez la méthode rollback(); pour annuler la transaction
Si la connexion n'est pas fermée à ce moment, vous devez restaurer son état de soumission automatique
Statut des données après soumission
Les modifications des données ont été enregistrées dans la base de données.
Les données avant le changement ont été perdues.
Tous les utilisateurs peuvent voir les résultats.
Le verrou est libéré et d'autres utilisateurs peuvent opérer sur les données concernées.
Classe d'outils 8-DBUtils
Une collection de classes et de méthodes JDBC couramment utilisées pour faire fonctionner des bases de données Ensemble, c'est DBUtils.
BeanHandler : convertir l'ensemble de résultats en JavaBean
BeanBeanListHandler : convertir le résultat set Convertir en une collection de Beans
MapHandler : convertir l'ensemble de résultats en une carte
MapMapListHandler : convertir l'ensemble de résultats en une liste de cartes
ScalarHandler : convertir le résultat défini sur une carte Renvoie un type de données, qui fait généralement référence à une chaîne ou à 8 autres types de données de base
Ce qui précède est la base de données JDBC. Contenu du système de gestion, veuillez faire attention au site Web PHP chinois (www.php.cn) pour plus de contenu connexe !