
Maison >Java >javaDidacticiel >Chapitre d'amélioration de Java (33) -----Résumé de la carte
Chapitre d'amélioration de Java (33) -----Résumé de la carte

- 黄舟original
- 2017-02-11 10:24:081558parcourir
Avant, LZ a présenté en détail les méthodes d'implémentation de HashMap, HashTable et TreeMap et les a développées sous trois aspects : la structure des données, le principe d'implémentation et l'analyse du code source. Vous devriez en avoir une compréhension plus claire. trois classes. Ci-dessous, LZ fait un bref résumé de Map.
Lecture recommandée :
Chapitre sur l'amélioration de Java (partie 2) 3) —-HashMap
>
Chapitre sur l'amélioration de Java (26) -----hashCode
Chapitre sur l'amélioration de Java (27) – TreeMap1. Présentation de la carte
Regardez d'abord le schéma structurel de Map

Carte : Interface abstraite pour le mappage "clé-valeur". La carte n'inclut pas les clés en double, une clé correspond à une valeur.
SortedMap : Interface de paire clé-valeur ordonnée, héritant de l'interface Map.
NavigableMap : hérite de SortedMap et possède une méthode de navigation qui renvoie la correspondance la plus proche pour une interface cible de recherche donnée .
AbstractMap : implémente la plupart des interfaces fonctionnelles de Map. Cela réduit le codage répété de la « classe d'implémentation de carte ».
Dictionnaire : La classe parent abstraite de toute classe qui mappe les clés aux valeurs correspondantes. Actuellement remplacé par l'interface Carte.
TreeMap : Table de hachage ordonnée, implémente l'interface SortedMap et la couche inférieure est implémentée via un rouge -arbre noir.
HashMap : est une table de hachage implémentée sur la base de la "méthode zip". La couche inférieure est implémentée à l'aide d'une "liste chaînée de tableaux".
WeakHashMap : Une table de hachage implémentée sur la base de la "méthode zippé".
HashTable : Une table de hachage implémentée sur la base de la "méthode zippé".
Le résumé est le suivant :
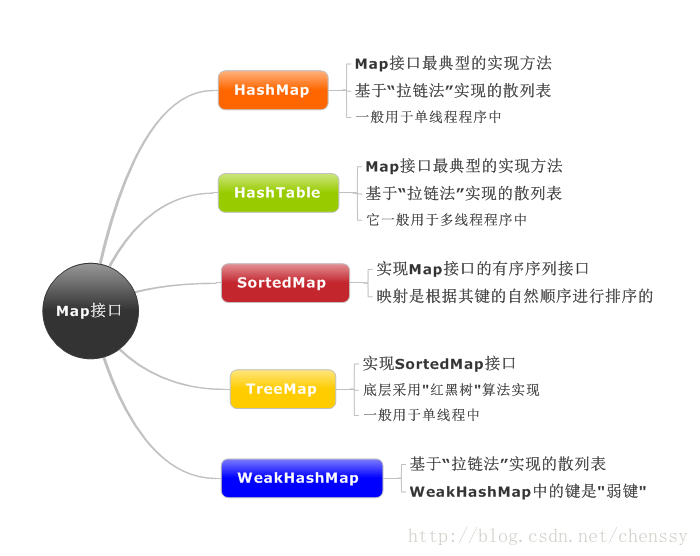
La différence entre eux :
Presque toutes les cartes générales utilisent la technologie de cartographie de hachage. Pour nous, programmeurs, nous devons le comprendre. La technologie de mappage de hachage est une technologie très simple qui mappe des éléments à des tableaux. Puisque la carte de hachage utilise un résultat de tableau, il doit y avoir un mécanisme d'indexation pour déterminer l'accès au tableau par n'importe quelle clé. Ce mécanisme peut fournir un entier plus petit que la taille du tableau. Nous appelons ce mécanisme une fonction de hachage. En Java, nous n'avons pas à nous soucier de trouver un tel entier, car chaque objet doit avoir une méthode hashCode qui renvoie une valeur entière, et tout ce que nous avons à faire est de le convertir en un entier, puis de diviser la valeur par le tableau. prenez le reste de la taille. Comme suit : Voici HashMap et HashTable : L'index de position représente la position du nœud dans le tableau. La figure suivante est le schéma de principe de base du mappage de hachage : La méthode put de HashMap montre l'idée de base du hash mapping. En fait, si l'on regarde d'autres Maps, on constate que les principes sont similaires ! La taille est de seulement 1 et tous les éléments seront mappés à cette position (0 ), formant ainsi une liste chaînée plus longue. Puisque nous devons effectuer une recherche linéaire sur cette liste chaînée lors de la mise à jour et de l'accès, cela réduira inévitablement l'efficacité. Nous supposons que s'il existe un très grand tableau et qu'il n'y a qu'un seul élément à chaque position dans la liste chaînée, l'objet sera obtenu en calculant sa valeur d'index lors de l'accès. Bien que cela améliorera l'efficacité de notre recherche, cela sera du gaspillage. contrôle. Certes, bien que ces deux méthodes soient extrêmes, elles nous donnent une idée d'optimisation : Utiliser un tableau plus grand pour que les éléments puissent être répartis uniformément. Il y a deux facteurs dans Map qui affecteront son efficacité. L'un est la taille initiale du conteneur et l'autre est le facteur de charge. En tant que « bucket », le nombre de buckets disponibles (c'est-à-dire la taille du tableau interne) est appelée capacité. Afin de permettre à l'objet Map de gérer efficacement un nombre quelconque d'éléments, nous avons conçu la Map pour pouvoir ajuster sa taille. Nous savons que lorsque les éléments de la Map atteignent une certaine quantité, le conteneur lui-même sera redimensionné, mais ce processus de redimensionnement est très coûteux. Le redimensionnement nécessite l'insertion de tous les éléments d'origine dans le nouveau tableau. Nous savons que index = hash(key) % length. Cela peut faire en sorte que les clés en conflit d'origine ne soient plus en conflit et que les clés non en conflit entrent désormais en conflit. Le processus de recalcul, d'ajustement et d'insertion est très coûteux et inefficace. Ainsi, Si nous commençons à connaître la taille attendue de la carte et à redimensionner la carte suffisamment grande, nous pouvons réduire considérablement, voire éliminer le besoin de redimensionnement, ce qui améliorera très probablement la vitesse. Ce qui suit est le processus par lequel HashMap ajuste la taille du conteneur. Grâce au code suivant, nous pouvons voir la complexité de son processus d'expansion : . 为了确认何时需要调整Map容器,Map使用了一个额外的参数并且粗略计算存储容器的密度。在Map调整大小之前,使用”负载因子”来指示Map将会承担的“负载量”,也就是它的负载程度,当容器中元素的数量达到了这个“负载量”,则Map将会进行扩容操作。负载因子、容量、Map大小之间的关系如下:负载因子 * 容量 > map大小 ----->调整Map大小。 例如:如果负载因子大小为0.75(HashMap的默认值),默认容量为11,则 11 * 0.75 = 8.25 = 8,所以当我们容器中插入第八个元素的时候,Map就会调整大小。 负载因子本身就是在控件和时间之间的折衷。当我使用较小的负载因子时,虽然降低了冲突的可能性,使得单个链表的长度减小了,加快了访问和更新的速度,但是它占用了更多的控件,使得数组中的大部分控件没有得到利用,元素分布比较稀疏,同时由于Map频繁的调整大小,可能会降低性能。但是如果负载因子过大,会使得元素分布比较紧凑,导致产生冲突的可能性加大,从而访问、更新速度较慢。所以我们一般推荐不更改负载因子的值,采用默认值0.75. 推荐阅读:
java提高篇(二三)—–HashMap java提高篇(二五)—–HashTable Java提高篇(二六)-----hashCode Java提高篇(二七)—–TreeMap
以上就是Java提高篇(三三)-----Map总结的内容,更多相关内容请关注PHP中文网(www.php.cn)!
2. Hachage interne : technologie de cartographie de hachage
int hashValue = Maths.abs(obj.hashCode()) % size;
----------HashMap------------
//计算hash值
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//计算key的索引位置
static int indexFor(int h, int length) {
return h & (length-1);
}
-----HashTable--------------
int index = (hash & 0x7FFFFFFF) % tab.length; //确认该key的索引位置
Dans cette figure, les étapes 1 à 4 consistent à trouver l'élément dans la position du tableau, les étapes 5 à 8 consistent à insérer l'élément dans le tableau. Il y aura un peu de frustration pendant le processus d'insertion. Il peut y avoir plusieurs éléments avec la même valeur de hachage, ils obtiendront donc la même position d'index, ce qui signifie que plusieurs éléments seront mappés à la même position. Ce processus est appelé « conflit ». La façon de résoudre le conflit consiste à insérer une liste chaînée à la position d'index et d'ajouter simplement l'élément à cette liste chaînée. Bien sûr, il ne s'agit pas d'une simple insertion. Le processus de traitement dans HashMap est le suivant : Obtenez la liste chaînée à la position d'index. Si la liste chaînée est nulle, insérez l'élément directement. Sinon, comparez s'il existe une clé. la même chose que la clé. Si elle existe, écrasez-la La valeur de la clé d'origine et renvoie l'ancienne valeur, sinon l'élément est enregistré en tête de chaîne (le premier élément enregistré est placé en fin de chaîne) . Voici la méthode put de HashMap, qui montre en détail l'ensemble du processus de calcul de la position de l'index et d'insertion de l'élément dans la position appropriée : public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode());
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length);
//从i出开始迭代 e,判断是否存在相同的key
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}3. Optimisation de la carte
3.1. Ajuster la taille de l'implémentation
void resize(int newCapacity) {
Entry[] oldTable = table; //原始容器
int oldCapacity = oldTable.length; //原始容器大小
if (oldCapacity == MAXIMUM_CAPACITY) { //是否超过最大值:1073741824
threshold = Integer.MAX_VALUE;
return;
}
//新的数组:大小为 oldCapacity * 2
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
/*
* 重新计算阀值 = newCapacity * loadFactor > MAXIMUM_CAPACITY + 1 ?
* newCapacity * loadFactor :MAXIMUM_CAPACITY + 1
*/
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//将元素插入到新数组中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}3.2、负载因子
最后