
Maison >Périphériques technologiques >IA >Qu'est-ce que le mélange d'experts?
Qu'est-ce que le mélange d'experts?

- William Shakespeareoriginal
- 2025-03-14 10:03:10696parcourir
Le mélange de modèles d'experts (MOE) révolutionne les modèles de grands langues (LLM) en améliorant l'efficacité et l'évolutivité. Cette architecture innovante divise le modèle en sous-réseaux spécialisés, ou «experts», chacun formé pour des types ou des tâches de données spécifiques. En activant uniquement un sous-ensemble d'experts pertinent en fonction de l'entrée, les modèles MOE augmentent considérablement la capacité sans augmenter proportionnellement les coûts de calcul. Cette activation sélective optimise l'utilisation des ressources et permet de gérer des tâches complexes dans divers domaines tels que le traitement du langage naturel, la vision par ordinateur et les systèmes de recommandation. Cet article explore les modèles MOE, leurs fonctionnalités, leurs exemples populaires et la mise en œuvre de Python.
Cet article fait partie du blogathon des sciences des données.
Table des matières:
- Que sont le mélange d'experts (Moes)?
- Moes en Deep Learning
- Comment fonctionnent les modèles MOE?
- Modèles basés sur le MOE
- Implémentation Python de Moes
- Comparaison des sorties de différents modèles MOE
- Dbrx
- Deepseek-V2
- Questions fréquemment posées
Que sont le mélange d'experts (Moes)?
Les modèles MOE améliorent l'apprentissage automatique en utilisant plusieurs modèles spécialisés plus petits au lieu d'un seul grand. Chaque modèle plus petit excelle à un type de problème spécifique. Un «décideur» (mécanisme de déclenchement) sélectionne le modèle approprié pour chaque tâche, améliorant les performances globales. Les modèles modernes d'apprentissage en profondeur, y compris les transformateurs, utilisent des unités interconnectées en couches ("neurones") qui traitent les données et transmettent les résultats aux couches suivantes. Le MOE reflète cela en divisant des problèmes complexes en composants spécialisés ("experts"), chacun s'attaquant à un aspect spécifique.
Avantages clés des modèles MOE:
- Pré-formation plus rapide par rapport aux modèles denses.
- Inférence plus rapide, même avec des dénombrements de paramètres similaires.
- Demande élevée de VRAM en raison du stockage simultané de tous les experts en mémoire.
Un modèle MOE comprend deux parties principales: des experts (réseaux de neurones plus petits spécialisés) et un routeur (qui active les experts pertinents en fonction de la contribution). Cette activation sélective stimule l'efficacité.
Moes en Deep Learning
Dans l'apprentissage en profondeur, le MOE améliore les performances du réseau neuronal en décomposant des problèmes complexes. Au lieu d'un seul grand modèle, il utilise plusieurs modèles "experts" plus petits spécialisés dans différents aspects de données d'entrée. Un réseau de déclenchement détermine les experts à utiliser pour chaque entrée, améliorant l'efficacité et l'efficacité.
Comment fonctionnent les modèles MOE?
Les modèles MOE fonctionnent comme suit:
- Plusieurs experts: le modèle contient plusieurs réseaux de neurones plus petits ("experts"), chacun formé pour des types ou des tâches d'entrée spécifiques.
- Réseau de déclenchement: Un réseau neuronal distinct (réseau de déclenchement) décide quel (s) expert utiliser pour chaque entrée, en attribuant des poids pour indiquer la contribution de chaque expert à la sortie finale.
- Routage dynamique: le réseau de déclenchement sélectionne dynamiquement les experts les plus pertinents pour chaque entrée, optimisant l'efficacité.
- Combinaison de sorties: les sorties des experts sélectionnées sont combinées en fonction des poids attribués du réseau de déclenchement, produisant la prédiction finale.
- Efficacité et évolutivité: les modèles MOE sont efficaces car seuls quelques experts sont activés pour chaque entrée, réduisant le coût de calcul. L'évolutivité est réalisée en ajoutant plus d'experts pour gérer des tâches plus complexes sans augmenter de manière significative le calcul par entrée.
Modèles basés sur le MOE
Les modèles MOE sont de plus en plus importants dans l'IA en raison de leur mise à l'échelle efficace des LLM tout en maintenant les performances. Mixtral 8x7b, un exemple notable, utilise une architecture MOE clairsemée, activant uniquement un sous-ensemble d'experts pour chaque entrée, conduisant à des gains d'efficacité significatifs.
Mixtral 8x7b
Mixtral 8x7b est un transformateur uniquement au décodeur. Les jetons d'entrée sont intégrés dans des vecteurs et traités via des couches de décodeur. La sortie est la probabilité que chaque emplacement soit occupé par un mot, permettant de remplir le texte et de prédiction. Chaque couche de décodeur a un mécanisme d'attention (pour des informations contextuelles) et une section de mélange clairsemé d'experts (SMOE) (traitement individuellement chaque vecteur de mot). Les couches SMOE utilisent plusieurs couches ("experts") et, pour chaque entrée, une somme pondérée des sorties des experts les plus pertinentes est prise.
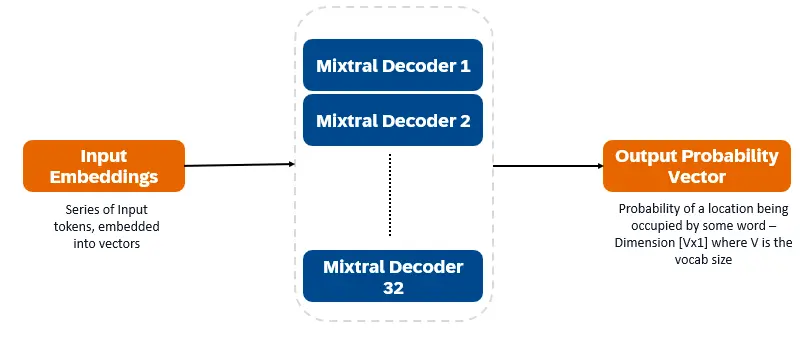
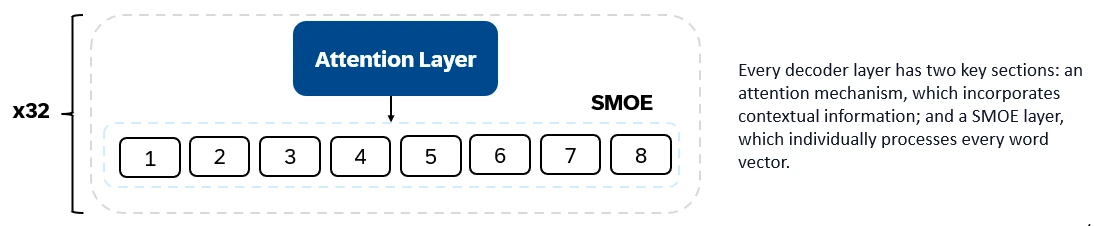
Caractéristiques clés de Mixtral 8x7b:
- Total des experts: 8
- Experts actifs: 2
- Couches de décodeur: 32
- Taille du vocabulaire: 32000
- Taille d'intégration: 4096
- Taille de l'expert: 5,6 milliards de paramètres chacun (total 7 milliards avec des composants partagés)
- Paramètres actifs: 12,8 milliards
- Longueur du contexte: jetons 32K
Mixtral 8x7b excelle dans la génération de texte, la compréhension, la traduction, la résumé, etc.
Dbrx
DBRX (Databricks) est un LLM de décodeur basé sur un transformateur formé uniquement à l'aide de prédiction à tarker suivant. Il utilise une architecture MOE à grains fins (paramètres totaux 132b, 36B actif). Il a été formé sur les jetons 12T de données de texte et de code. DBRX est à grain fin, en utilisant de nombreux petits experts (16 experts, 4 sélectionnés par entrée).
Caractéristiques architecturales clés de DBRX:
- Experts à grain fin: un seul FFN est divisé en segments, chacun agissant en tant qu'expert.
- Autres techniques: Encodages de position rotative (corde), unités linéaires fermées (GLU) et attention groupée de la requête (GQA).
Caractéristiques clés de DBRX:
- Total des experts: 16
- Experts actifs par couche: 4
- Couches de décodeur: 24
- Paramètres actifs: 36 milliards
- Paramètres totaux: 132 milliards
- Longueur du contexte: jetons 32K
DBRX excelle dans la génération de code, la compréhension complexe du langage et le raisonnement mathématique.
Deepseek-V2
Deepseek-V2 utilise des experts à grain fin et des experts partagés (toujours actifs) pour intégrer les connaissances universelles.
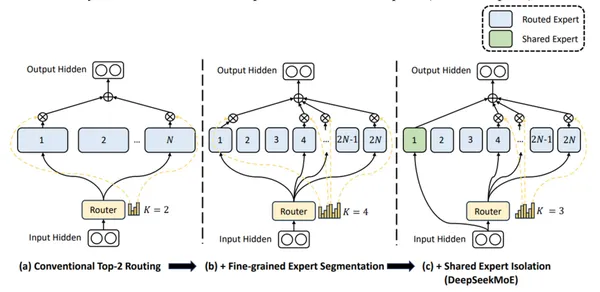
Caractéristiques clés de Deepseek-V2:
- Paramètres totaux: 236 milliards
- Paramètres actifs: 21 milliards
- Experts routés par couche: 160 (2 sélectionnés)
- Experts partagés par couche: 2
- Experts actifs par couche: 8
- Couches de décodeur: 60
- Longueur du contexte: jetons 128K
Deepseek-V2 est apte aux conversations, à la création de contenu et à la génération de code.
(Les sections de comparaison de mise en œuvre et de sortie Python supprimées pour la brièveté, car ce sont de longs exemples de code et des analyses détaillées.)
Questions fréquemment posées
Q1. Que sont les modèles de mélange d'experts (MOE)? A. Les modèles MOE utilisent une architecture clairsemée, activant uniquement les experts les plus pertinents pour chaque tâche, conduisant à une utilisation réduite des ressources informatiques.
Q2. Quel est le compromis avec les modèles MOE? A. Les modèles MOE nécessitent un VRAM important pour stocker tous les experts en mémoire, équilibrant les exigences de puissance de calcul et de mémoire.
Q3. Quel est le nombre de paramètres actifs pour Mixtral 8x7b? A. Mixtral 8x7b a 12,8 milliards de paramètres actifs.
Q4. En quoi DBRX diffère-t-il des autres modèles MOE? A. DBRX utilise une approche MOE à grain fin avec des experts plus petits.
Q5. Qu'est-ce qui distingue Deepseek-V2? A. Deepseek-V2 combine des experts à grain fin et partagé, ainsi qu'un grand ensemble de paramètres et une longue longueur de contexte.
Conclusion
Les modèles MOE offrent une approche très efficace de l'apprentissage en profondeur. Tout en nécessitant un VRAM important, leur activation sélective d'experts en fait des outils puissants pour gérer les tâches complexes dans divers domaines. Mixtral 8x7b, DBRX et Deepseek-V2 représentent des progrès importants dans ce domaine, chacun avec ses propres forces et applications.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI