
Maison >Périphériques technologiques >IA >Rag correctif (rocher) en action
Rag correctif (rocher) en action

- 尊渡假赌尊渡假赌尊渡假赌original
- 2025-03-13 10:37:08402parcourir
La génération (RAG) de la récupération (RAG) permet de modèles de grande langue (LLM) en incorporant la récupération d'informations. Cela permet aux LLMS d'accéder à des bases de connaissances externes, ce qui entraîne des réponses plus précises, actuelles et contextuellement appropriées. Le chiffon correctif (Crag), une technique de chiffon avancé, améliore encore la précision en introduisant des mécanismes d'auto-réflexion et d'auto-évaluation pour les documents récupérés.
Objectifs d'apprentissage clés
Cet article couvre:
- Le mécanisme de base de Crag et son intégration à la recherche Web.
- L'évaluation de la pertinence du document de Crag à l'aide de la notation binaire et de la réécriture de requête.
- Distinctions clés entre le ragot traditionnel et le chiffon traditionnel.
- Implémentation pratique de la randonnée à l'aide de Python, Langchain et Tavily.
- Compétences pratiques pour configurer les évaluateurs, les réécriteurs de requête et les outils de recherche Web pour optimiser la récupération et la précision de la réponse.
Publié dans le cadre du Blogathon de la science des données.
Table des matières
- Mécanisme sous-jacent de Crag
- Cague vs chiffon traditionnel
- Mise en œuvre pratique des rochers
- Les défis de Crag
- Conclusion
- Questions fréquemment posées
Mécanisme sous-jacent de Crag
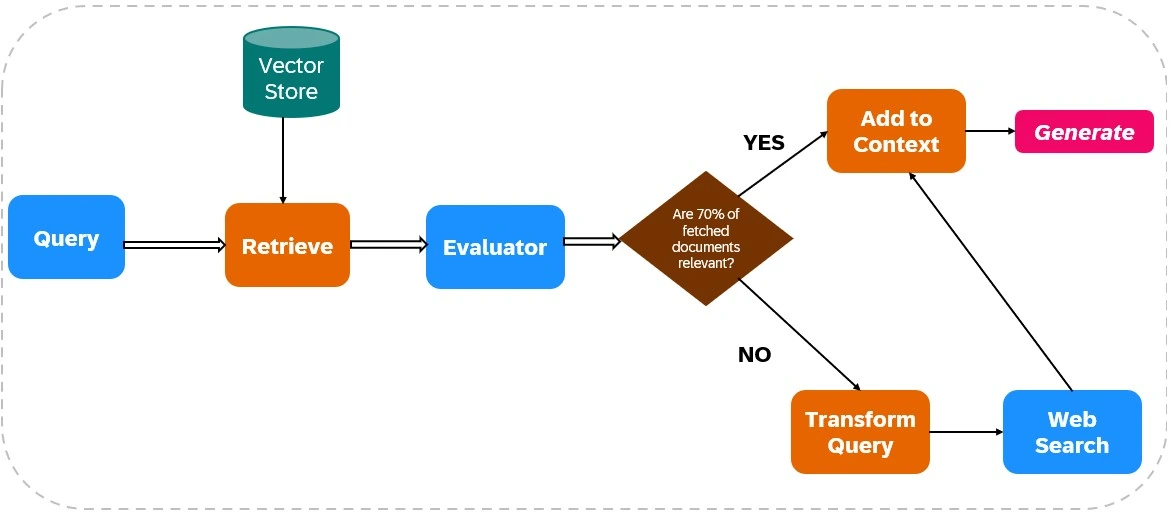
Crag améliore la fiabilité des sorties LLM en intégrant la recherche Web dans ses processus de récupération et de génération (voir figure 1).
Récupération de documents:
- Ingestion de données: les données pertinentes sont indexées et les outils de recherche Web (comme Tavily AI) sont configurés pour la récupération des données en temps réel.
- Récupération initiale: les documents sont récupérés à partir d'une base de connaissances statique basée sur la requête de l'utilisateur.
Évaluation de la pertinence:
Un évaluateur évalue la pertinence du document récupéré. Si plus de 70% des documents sont jugés non pertinents, des actions correctives sont initiées; Sinon, la génération de réponse se déroule.
Intégration de recherche sur le Web:
Si la pertinence du document est insuffisante, Crag utilise la recherche Web:
- Raffinement de requête: la requête d'origine est modifiée pour optimiser les résultats de recherche Web.
- Exécution de la recherche sur le Web: des outils tels que Tavily AI récupèrent des données supplémentaires, garantissant l'accès à des informations actuelles et diverses.
Génération de réponse:
Crag synthétise les données de la récupération initiale et des recherches Web pour créer une réponse cohérente et précise.
Cague vs chiffon traditionnel
Crag vérifie et affine activement les informations récupérées, contrairement à la RAG traditionnelle, qui repose sur des documents récupérés sans vérification. Crag intègre souvent la recherche sur le Web en temps réel, donnant accès aux informations les plus à jour, contrairement à la dépendance de la Rag traditionnelle aux bases de connaissances statiques. Cela rend Crag idéal pour les applications nécessitant une précision élevée et une intégration de données en temps réel.
Mise en œuvre pratique des rochers
Cette section détaille une implémentation de Crag à l'aide de Python, Langchain et Tavily.
Étape 1: installation de la bibliothèque
Installez les bibliothèques nécessaires:
! pip installer tiktoken langchain-openai Langchainhub chromadb langchain langgraph tavily-python ! pip install -qu pypdf Langchain_community
Étape 2: configuration de la clé API
Définissez vos clés API:
Importer un système d'exploitation os.environ ["tavily_api_key"] = "" os.environ ["openai_api_key"] = ""
Étape 3: Imports de bibliothèque
Importer des bibliothèques requises (code omis pour la concision, mais similaire à l'exemple d'origine).
Étape 4: Document Chunking and Retriever Création
(Code omis pour Brevity, mais similaire à l'exemple d'origine, en utilisant PYPDFLoader, RecursiVECHarAtteTextStSplitter, Openaiembedddings et ChroMA).
Étape 5: Configuration de la chaîne de chiffon
(Code omis pour Brevity, mais similaire à l'exemple d'origine, en utilisant hub.pull("rlm/rag-prompt") et ChatOpenAI ).
Étape 6: Configuration de l'évaluateur
(Code omis pour la concision, mais similaire à l'exemple d'origine, définissant la classe Evaluator et utilisant ChatOpenAI pour l'évaluation).
Étape 7: Configuration du réécriture de requête
(Code omis pour Brevity, mais similaire à l'exemple d'origine, en utilisant ChatOpenAI pour la réécriture de la requête).
Étape 8: Configuration de la recherche sur le Web
De Langchain_community.tools.tavily_search Import TavilySearchResults web_search_tool = TavilySearchResults (k = 3)
Étape 9-12: Configuration et exécution du flux de travail Langgraph
(Code omis pour la concision, mais conceptuellement similaire à l'exemple d'origine, en définissant les nœuds GraphState , des nœuds de fonction ( retrieve , generate , evaluate_documents , transform_query , web_search ) et les connecter à l'aide de StateGraph .) La sortie finale et la comparaison avec le chiffon traditionnel sont également conceptuellement similaires.
Les défis de Crag
L'efficacité de Crag dépend fortement de la précision de l'évaluateur. Un évaluateur faible peut introduire des erreurs. L'évolutivité et l'adaptabilité sont également des préoccupations, nécessitant des mises à jour et une formation continues. L'intégration de la recherche sur le Web présente le risque d'informations biaisées ou peu fiables, nécessitant des mécanismes de filtrage robustes.
Conclusion
Crag améliore considérablement la précision et la fiabilité de la sortie LLM. Sa capacité à évaluer et à compléter les informations récupérées avec des données Web en temps réel les rend précieuses pour les applications exigeant des informations de haute précision et à jour. Cependant, le raffinement continu est crucial pour relever les défis liés à la précision de l'évaluateur et à la fiabilité des données Web.
Les principaux plats à retenir (similaires à l'original, mais reformulé pour la concision)
- Crag améliore les réponses LLM à l'aide de la recherche Web pour les informations actuelles et pertinentes.
- Son évaluateur assure des informations de haute qualité pour la génération de réponse.
- La transformation de la requête optimise les résultats de recherche Web.
- Crag intègre dynamiquement les données Web en temps réel, contrairement à RAG traditionnel.
- Crag vérifie activement les informations, réduisant les erreurs.
- Crag est bénéfique pour les applications nécessitant une grande précision et des données en temps réel.
Des questions fréquemment posées (similaires à l'original, mais reformulé pour la concision)
- Q1: Qu'est-ce que Crag? R: Un cadre de chiffon avancé intégrant la recherche Web pour une précision et une fiabilité améliorées.
- Q2: Crag vs chiffon traditionnel? R: Crag vérifie et affine activement les informations récupérées.
- Q3: Le rôle de l'évaluateur? R: Évaluer la pertinence des documents et déclencher des corrections.
- Q4: Documents insuffisants? R: Crag Suppléments avec la recherche Web.
- Q5: Gérer le contenu Web peu fiable? R: Des méthodes de filtrage avancées sont nécessaires.
(Remarque: l'image reste inchangée et est incluse comme dans l'entrée d'origine.)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI