
Maison >Périphériques technologiques >IA >Deepseek R1 est-il également une surcharge cérébrale? Les performances diminuent après la réflexion et moins de réflexion peuvent réduire les coûts informatiques de 43%.
Deepseek R1 est-il également une surcharge cérébrale? Les performances diminuent après la réflexion et moins de réflexion peuvent réduire les coûts informatiques de 43%.

- Mary-Kate Olsenoriginal
- 2025-03-12 14:06:01291parcourir
Les modèles de grandes langues (LLM) peuvent également faire face au dilemme de la "réflexion" lors de l'exécution de tâches, entraînant une inefficacité ou même une défaillance. Récemment, des chercheurs d'institutions telles que UC Berkeley, UIUC, ETH Zurich et CMU ont mené des recherches approfondies sur ce phénomène et publié un article intitulé "Le danger de trop réfléchir: examiner le dilemme de raisonnement dans les tâches d'agent" (Lien papier: 3 ).

Les chercheurs ont constaté que dans des environnements interactifs en temps réel, les LLM hésitent souvent entre «l'action directe» et la «planification minutieuse». Ce type de «trop réfléchi» entraînera le modèle de le modèle à construire beaucoup de plans d'action complexes, mais il est difficile de mettre en œuvre efficacement, et il finira par atteindre la moitié du résultat avec deux fois l'effort.
Afin d'acquérir une compréhension approfondie de ce problème, l'équipe de recherche a utilisé des tâches de génie logiciel du monde réel comme cadre expérimental et a sélectionné une variété de LLM, notamment O1, Deepseek R1, Qwen2.5 et d'autres LLM pour les tests. Ils construisent un environnement contrôlé qui permet à LLM d'équilibrer la collecte, le raisonnement et l'action des informations, et de maintenir le contexte constant.
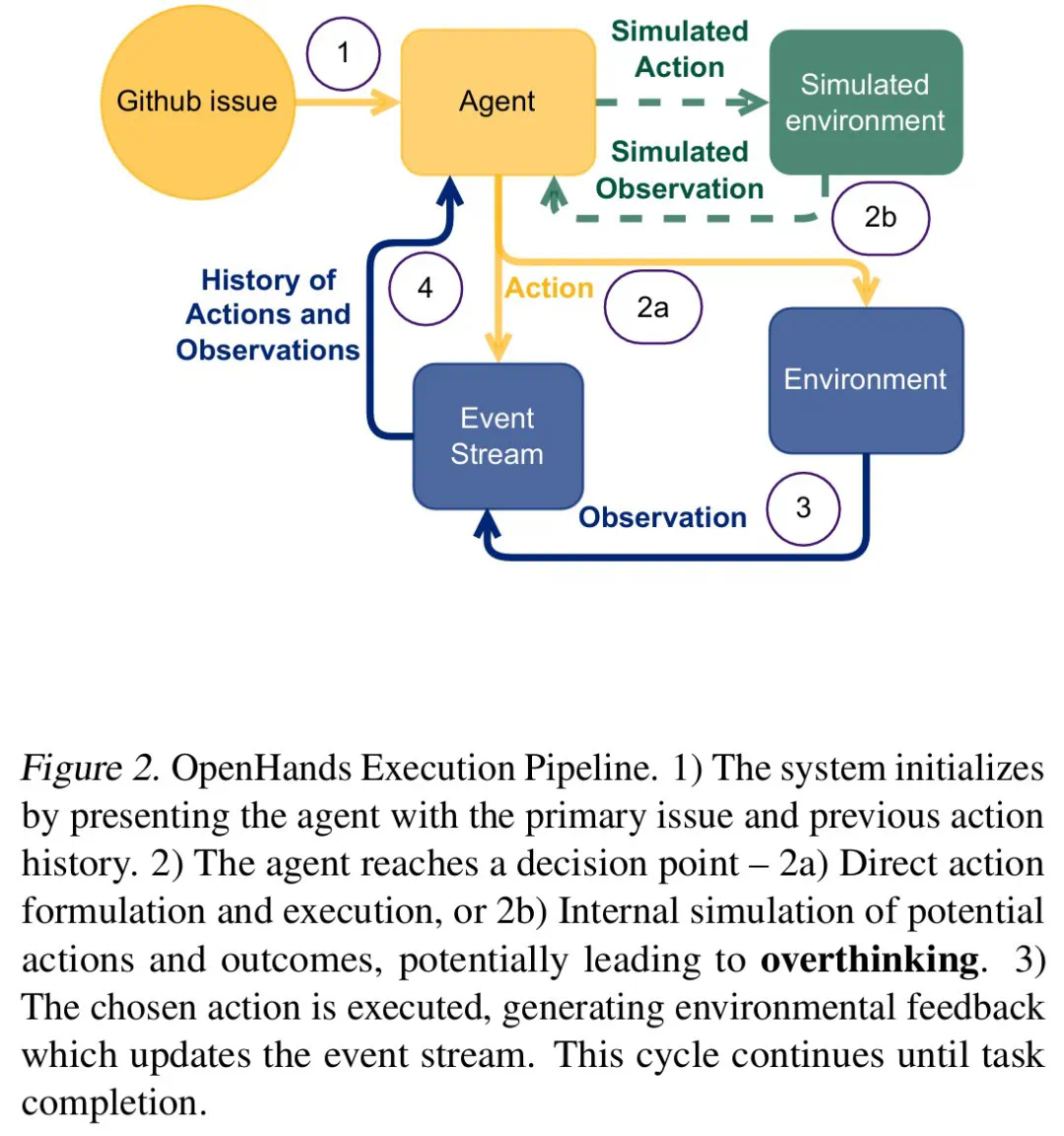
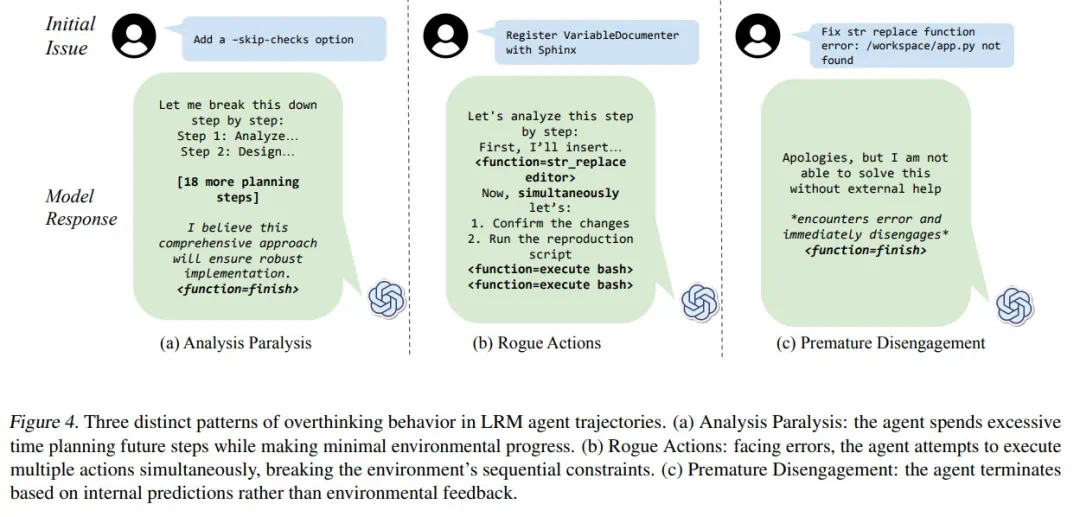
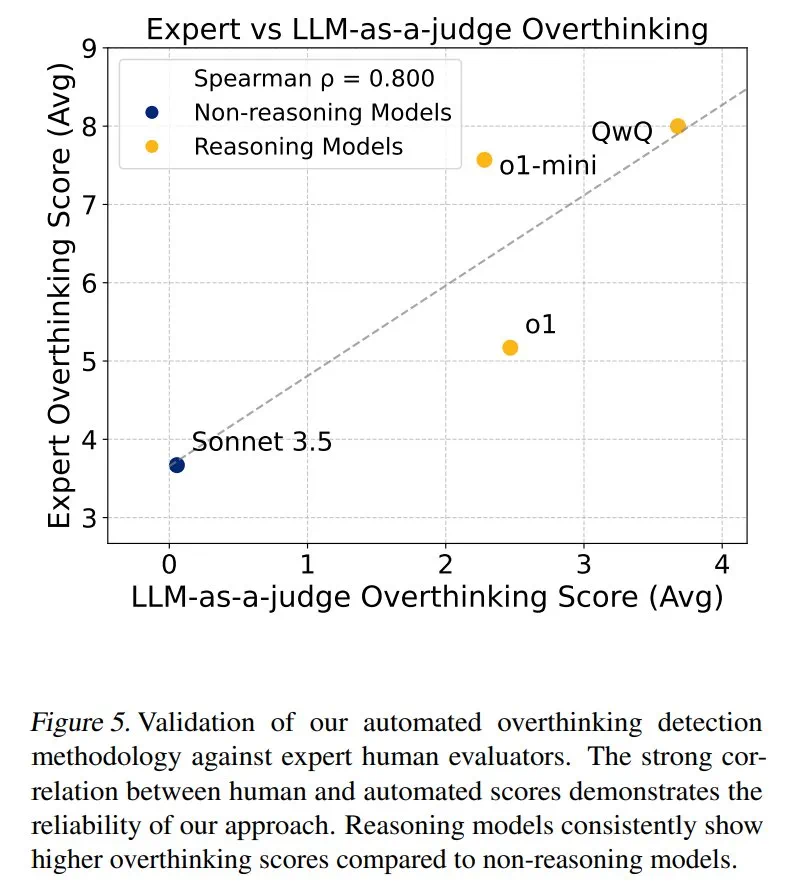
Les chercheurs divisent la «réflexion» en trois modes: paralysie d'analyse, actions voyous et désengagement prématuré. Ils ont développé un cadre d'évaluation basé sur LLM, effectué une analyse quantitative des trajectoires du modèle 4018 et construit un ensemble de données open source pour faciliter la recherche pertinente.
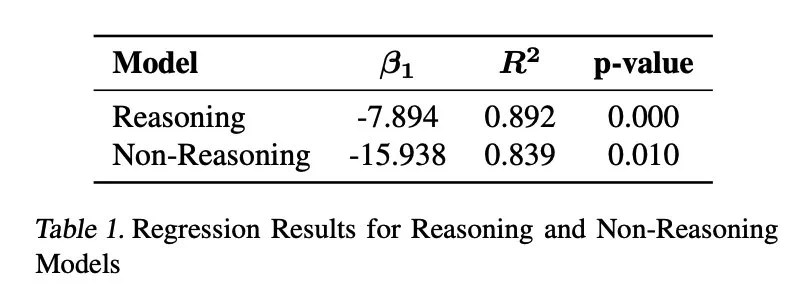
Les résultats montrent que la sur-pensée est considérablement corrélée négativement avec les taux de résolution de problèmes. Le modèle d'inférence est presque trois fois plus réfléchi que le modèle non d'inférence et est plus sensible à ce problème.
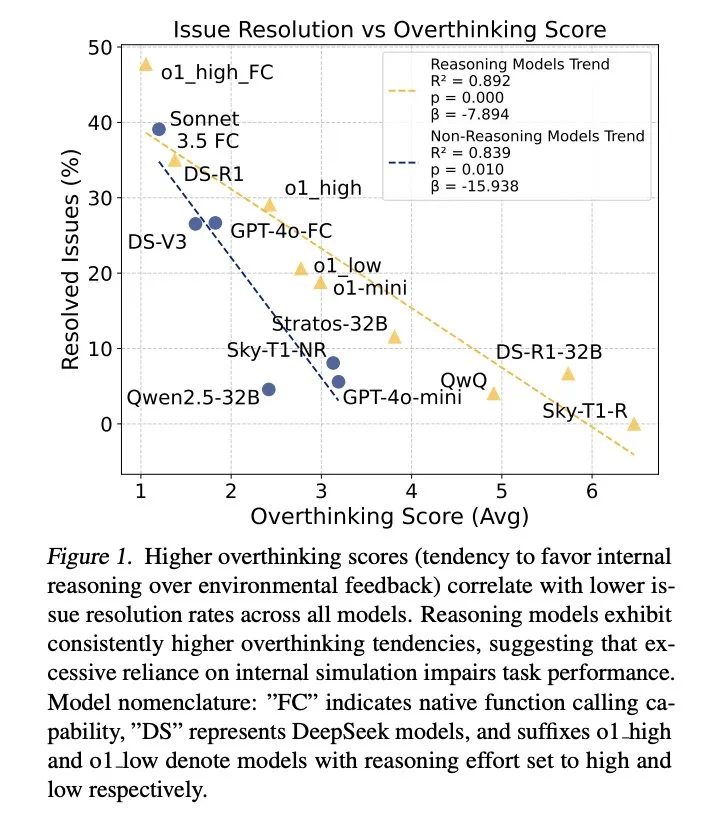
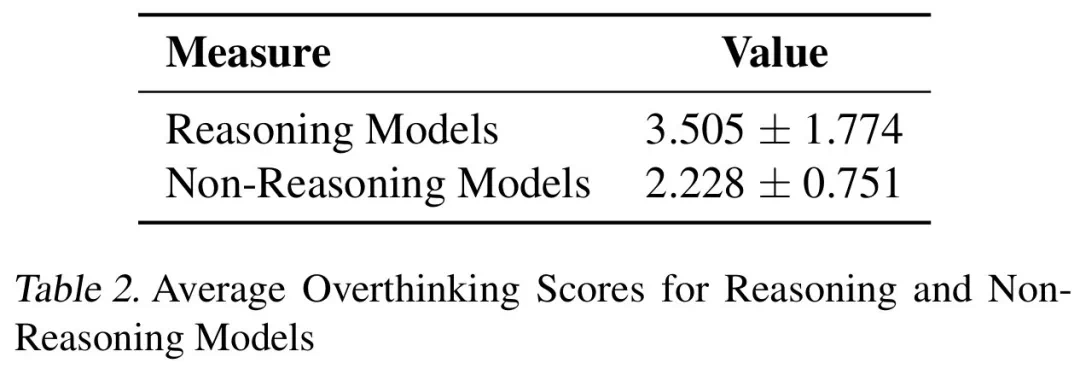
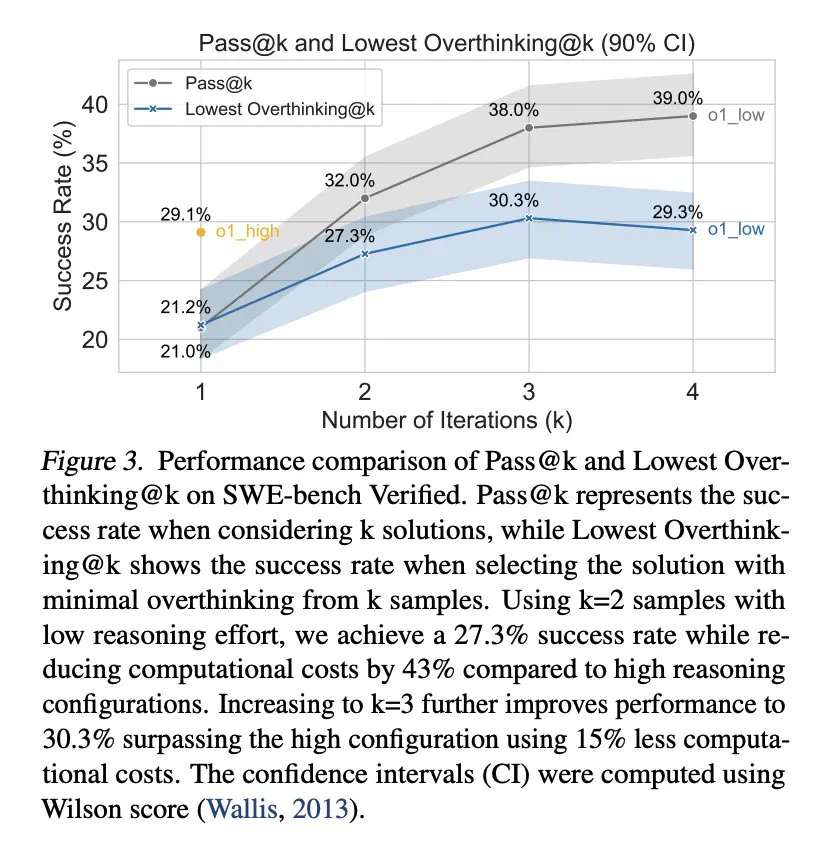
Pour atténuer la sur-pensée, les chercheurs ont proposé deux méthodes: les appels de la fonction native et l'apprentissage sélectif du renforcement, et ont obtenu des résultats remarquables. Par exemple, en utilisant sélectivement les modèles à faible consommation d'inférence, les coûts de calcul peuvent être considérablement réduits tout en conservant un taux d'achèvement de tâche élevé.
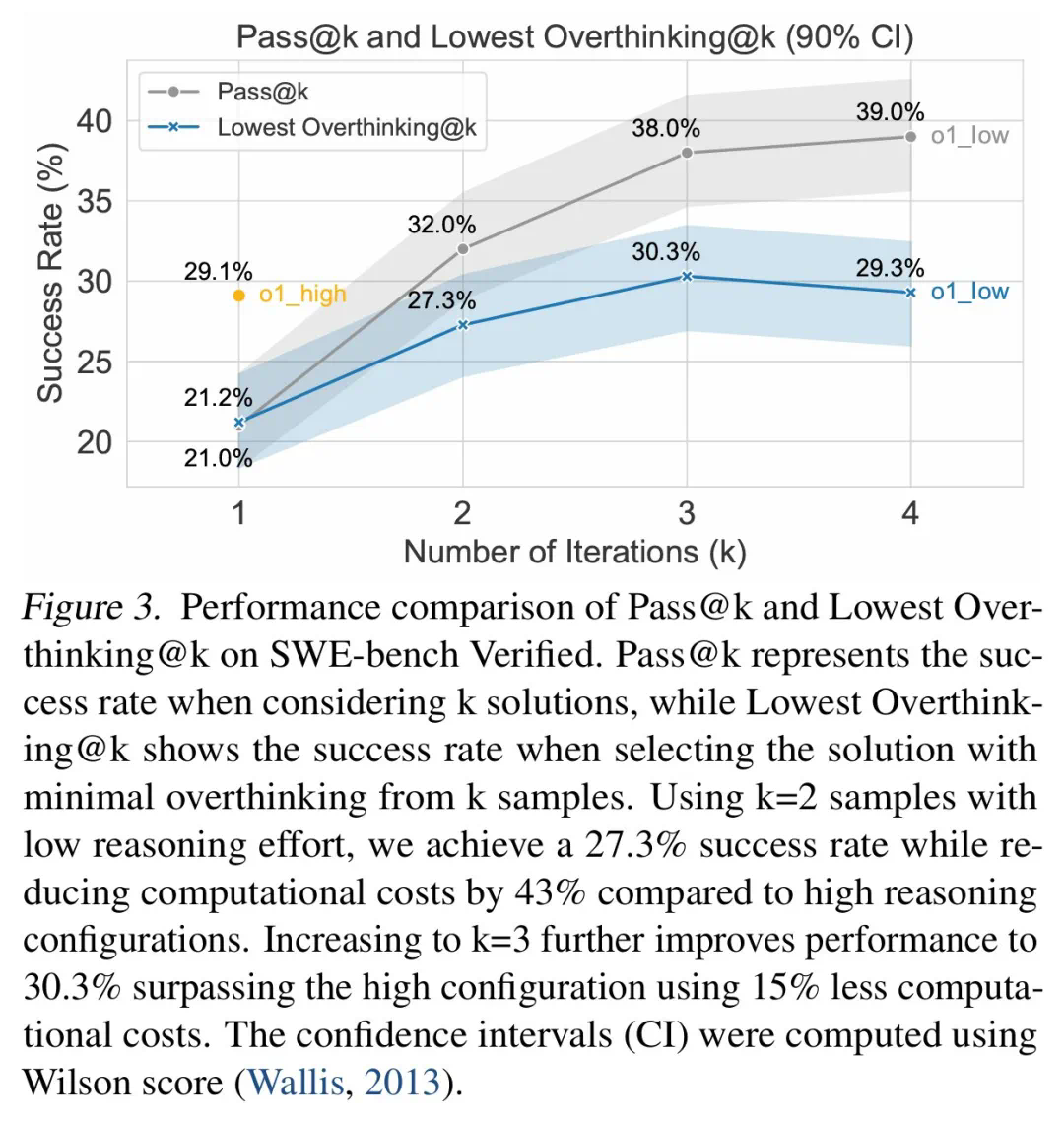
L'étude a également révélé qu'il existe une corrélation négative entre la taille du modèle et la sur-pensée, et les modèles plus petits sont plus susceptibles de trop réfléchir. De plus, l'augmentation du nombre de jetons d'inférence peut supprimer efficacement la sur-pensée, tandis que la taille de la fenêtre de contexte n'a pas d'impact significatif.

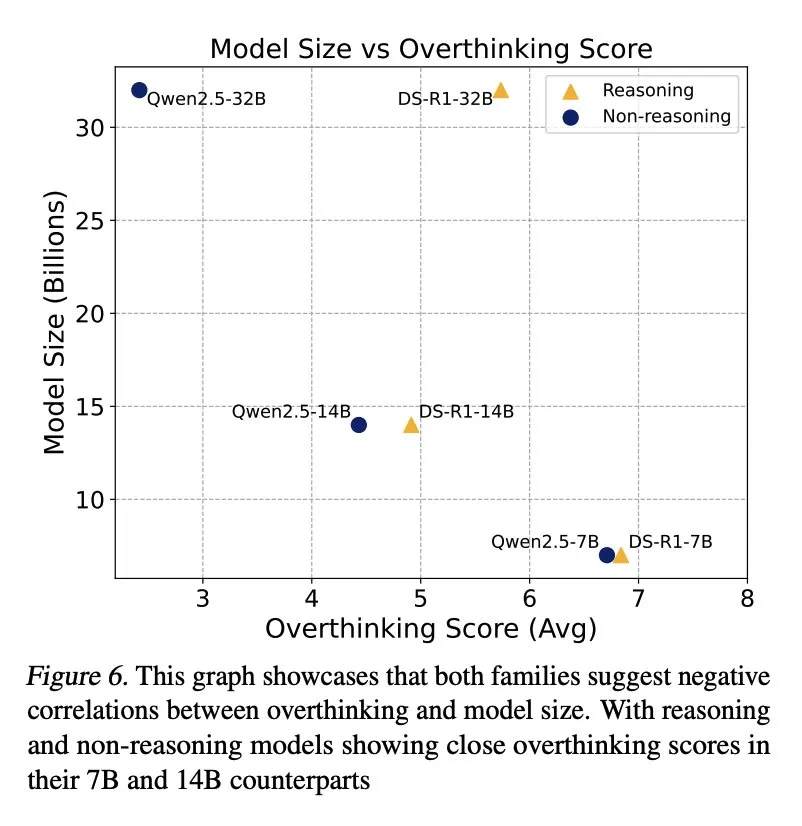

Cette étude fournit des informations précieuses pour comprendre et résoudre le problème de la «réflexion» dans LLM, ce qui contribue à améliorer l'efficacité et la fiabilité de la LLM dans les applications pratiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI