



Les incorporations de vecteurs
sont fondamentales pour de nombreuses applications AI avancées, y compris la recherche sémantique et la détection d'anomalies. Cet article fournit une compréhension fondamentale des intérêts, en se concentrant sur les incorporations de phrases et les représentations vectorielles. Nous explorerons des techniques pratiques telles que la mise en commun moyen et la similitude des cosinus, approfondirons l'architecture de deux encodeurs à l'aide de Bert, et examiner leur application dans la détection d'anomalies avec un sommet de Vertex pour les tâches telles que la détection de fraude et la modération du contenu.
Objectifs d'apprentissage clés
L'espace.- Comprendre les incorporations de sommets
- Les intérêts des phrases ont été expliqués
- Cosine similitude dans les intérêts des phrases
- Formation Un modèle d'encodeur double
- Dual Encoders for Questionning
- Le processus de formation double d'encodeur li> ENCHEDDDINGS avec un processus de formation en double encodeur li> LEVERIEDS ENCODINGS ENCODINGS ENCORDE TRAPROSE ENCODER DUAL Vertex Ai
- Création de l'ensemble de données à partir de Stack Overflow
- Génération de textes incorporateurs
- Génération par lots
- Identification des anomalies
- Forêt d'isolement pour la détection de la valeur aberrante
Les incorporations vectorielles représentent des mots ou des phrases dans un espace défini. La proximité de ces vecteurs signifie la similitude; Des vecteurs plus proches indiquent une plus grande similitude sémantique. Bien que initialement utilisé principalement dans la PNL, leur application s'étend aux images, vidéos, audio et graphiques. Clip, un modèle d'apprentissage multimodal proéminent, génère à la fois des intégres d'image et de texte.
Les applications clés des intégres vectorielles incluent:
- LLMS les utilisent comme des incorporations de jeton après des réponses les plus pertinentes. (RAG), les incorporations de phrases facilitent la récupération des morceaux d'information pertinents.
- Les systèmes de recommandation les utilisent pour représenter les produits et identifier les articles connexes.
Examinons l'importance des incorporations de phrases dans les pipelines de chiffon.
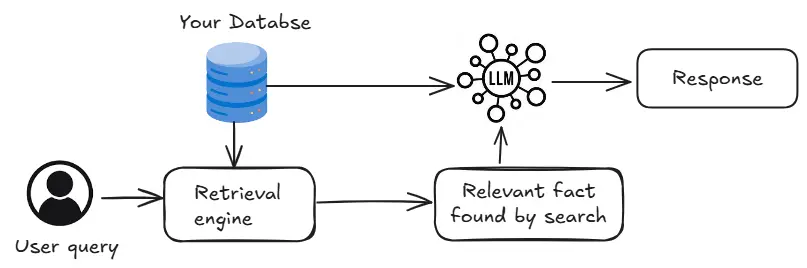 pour les quais de l'utilisateur. Les encodeurs intermédiaires basés sur les transformateurs peuvent comparer les requêtes à toutes les informations, classant la pertinence. Cependant, c'est lent. Les bases de données vectorielles offrent une alternative plus rapide en stockant des incorporations et en utilisant des recherches de similitude, bien que la précision puisse être légèrement plus faible.
pour les quais de l'utilisateur. Les encodeurs intermédiaires basés sur les transformateurs peuvent comparer les requêtes à toutes les informations, classant la pertinence. Cependant, c'est lent. Les bases de données vectorielles offrent une alternative plus rapide en stockant des incorporations et en utilisant des recherches de similitude, bien que la précision puisse être légèrement plus faible.
Comprendre les incorporations de phrases
Les incorporations de phrases sont créées en appliquant des opérations mathématiques à des incorporations de jetons, souvent générées par des modèles pré-formés comme Bert ou GTP. Le code suivant démontre la mise en commun moyen des intégres de jetons générés par Bert pour créer des incorporations de phrases:
Model_Name = "./Models/bert-Base-Ulasled" tokenizer = bertTokenzer.from_pretrained (Model_Name) Model = BertModel.from_pretraind (Model_Name) Def Get_Sentence_embedd = tokenizer (phrase, padding = true, truncation = true, return_tensers = 'pt') Attention_mask = encoded_input ['Attention_mask'] avec torch.no_grad (): Output = Model (** encoded_input) token_embeddings = output.last_hidden_state input_mask_expanded = Attention_mask.unsqueeze (-1) .expand (token_embedings.size ()). float () phrase_embedding = torch.sum (token_embeddings * input_mask_expanded, 1) / torch.clamp (input_mask_expanded.sum (1), min = 1e-9) return pheent <p> Ce code charge un modèle BERT et définit une fonction pour calculer les intégres de phrases en utilisant le regroupement moyen. </p> <p> <strong> La similitude en cosinus des intérêts des phrases </strong> </p> <p> La similitude du cosinus mesure la similitude entre deux vecteurs, ce qui le rend adapté à la comparaison de la phrase. Le code suivant met en œuvre la similitude et la visualisation des cosinus: </p> <pr> def cosine_similarity_matrix (fonctionnalités): normes = np.linalg.norm (fonctionnalités, axe = 1, keepdims = true) normalisé_features = normalized_feary_matrix = np.inner (normalisé_features, normalisé_features) np.round (simility_matrix, 4) RETOUR ROUND_SIMLILITY_MATRIX DEF PLOT_SIMLILITÉ (Étiquettes, fonctionnalités, rotation): sim = cosine_similarity_matrix (fonctionnalités) sns.set_theme (Font_scale = 1.2) g = sns.heatmap (SIMSTICKLABELS = LABELS, YTICKLABEL vmax = 1, cmap = "ylorrd") g.set_xtickLabels (étiquettes, rotation = rotation) g.set_title ("similitude textuelle sémantique") Retour g messages = [# Technology "Je préfère utiliser un macbook pour le travail.", "Est-ce que vous avez un œuvre de humaine?", "My Battery Drains. Un joueur de basket-ball incroyable. "," J'apprécie les marathons de courir le week-end. ", # Travel" Paris est une belle ville à visiter. "," Quels sont les meilleurs endroits pour voyager en été? "," I Love Randing in the Swiss Alps. ", # Entertainment" Le dernier film Marvel était fantastique! "," Écoutez-vous Taylor Swift? " Dans les messages: EMB = get_pentence_embedding (t) embeddings.append (emb) tracé_similarity (messages, intégres, 90) </pr> Ce code définit les phrases, génère des incorporations et trace une carte thermique montrant leur similitude de cosinine. Les résultats pourraient montrer une similitude inattendue, motivant l'exploration de méthodes plus précises comme les doubles encodeurs.
(les sections restantes se poursuivent de manière similaire, paraphrasant et restructurant le texte d'origine tout en maintenant les informations de base et en préservant les emplacements et les formats d'image.)
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Microsoft Work Trend Index 2025 montre une souche de capacité de travailApr 24, 2025 am 11:19 AM
Microsoft Work Trend Index 2025 montre une souche de capacité de travailApr 24, 2025 am 11:19 AMLa crise de la capacité en plein essor sur le lieu de travail, exacerbé par l'intégration rapide de l'IA, exige un changement stratégique au-delà des ajustements progressifs. Ceci est souligné par les conclusions de la WTI: 68% des employés ont du mal avec la charge de travail, ce qui mène à Bur
 L'IA peut-elle comprendre? L'argument de la salle chinoise dit non, mais est-ce vrai?Apr 24, 2025 am 11:18 AM
L'IA peut-elle comprendre? L'argument de la salle chinoise dit non, mais est-ce vrai?Apr 24, 2025 am 11:18 AMArgument de la salle chinoise de John Searle: un défi à la compréhension de l'IA L'expérience de pensée de Searle se demande directement si l'intelligence artificielle peut vraiment comprendre la langue ou posséder une véritable conscience. Imaginez une personne, ignorant des chines
 Les assistants de l'IA «intelligents» de la Chine font écho aux défauts de confidentialité de Microsoft RappelApr 24, 2025 am 11:17 AM
Les assistants de l'IA «intelligents» de la Chine font écho aux défauts de confidentialité de Microsoft RappelApr 24, 2025 am 11:17 AMLes géants de la technologie chinoise tracent un cours différent dans le développement de l'IA par rapport à leurs homologues occidentaux. Au lieu de se concentrer uniquement sur les références techniques et les intégrations API, ils privilégient les assistants de l'IA "Ai-Ai" - AI T
 Docker apporte un flux de travail de conteneur familier aux modèles AI et aux outils MCPApr 24, 2025 am 11:16 AM
Docker apporte un flux de travail de conteneur familier aux modèles AI et aux outils MCPApr 24, 2025 am 11:16 AMMCP: Empower les systèmes AI pour accéder aux outils externes Le protocole de contexte du modèle (MCP) permet aux applications d'IA d'interagir avec des outils externes et des sources de données via des interfaces standardisées. Développé par anthropique et soutenu par les principaux fournisseurs d'IA, MCP permet aux modèles de langue et aux agents de découvrir des outils disponibles et de les appeler avec des paramètres appropriés. Cependant, il existe certains défis dans la mise en œuvre des serveurs MCP, y compris les conflits environnementaux, les vulnérabilités de sécurité et le comportement multiplateforme incohérent. L'article de Forbes "Le protocole de contexte du modèle d'Anthropic est une grande étape dans le développement des agents de l'IA", auteur: Janakiram Msvdocker résout ces problèmes par la conteneurisation. Doc construit sur l'infrastructure Docker Hub
 Utilisation de 6 stratégies intelligentes de rue AI pour construire une startup d'un milliard de dollarsApr 24, 2025 am 11:15 AM
Utilisation de 6 stratégies intelligentes de rue AI pour construire une startup d'un milliard de dollarsApr 24, 2025 am 11:15 AMSix stratégies employées par des entrepreneurs visionnaires qui ont exploité des technologies de pointe et un sens des affaires astucieux pour créer des entreprises très rentables et évolutives tout en gardant le contrôle. Ce guide est destiné aux aspirants entrepreneurs visant à construire un
 Google Photos Update déverrouille Superbe Ultra HDR pour toutes vos photosApr 24, 2025 am 11:14 AM
Google Photos Update déverrouille Superbe Ultra HDR pour toutes vos photosApr 24, 2025 am 11:14 AMLe nouvel outil Ultra HDR de Google Photos: un changeur de jeu pour l'amélioration de l'image Google Photos a introduit un puissant outil de conversion Ultra HDR, transformant des photos standard en images vibrantes et à grande échelle. Cette amélioration profite aux photographes
 Descope construit un cadre d'authentification pour l'intégration des agents AIApr 24, 2025 am 11:13 AM
Descope construit un cadre d'authentification pour l'intégration des agents AIApr 24, 2025 am 11:13 AML'architecture technique résout les défis d'authentification émergents Le centre d'identité agentique aborde un problème que de nombreuses organisations ne découvrent que après avoir commencé à mettre en œuvre l'agent d'IA que les méthodes d'authentification traditionnelles ne sont pas conçues pour la machine.
 Google Cloud prochain 2025 et l'avenir connecté du travail moderneApr 24, 2025 am 11:12 AM
Google Cloud prochain 2025 et l'avenir connecté du travail moderneApr 24, 2025 am 11:12 AM(Remarque: Google est un client consultatif de mon entreprise, Moor Insights & Strategy.) AI: de l'expérience à la fondation d'entreprise Google Cloud Next 2025 a présenté l'évolution de l'IA de la fonctionnalité expérimentale à un composant central de la technologie d'entreprise, Stream


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Version Mac de WebStorm
Outils de développement JavaScript utiles

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

Version crackée d'EditPlus en chinois
Petite taille, coloration syntaxique, ne prend pas en charge la fonction d'invite de code

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

