
Maison >Périphériques technologiques >IA >Coca: les légendes contrastives sont des modèles de fondation de texte d'image expliqués visuellement
Coca: les légendes contrastives sont des modèles de fondation de texte d'image expliqués visuellement

- Jennifer Anistonoriginal
- 2025-03-10 11:17:15244parcourir
Ce didacticiel communautaire DataCamp, édité pour plus de clarté et de précision, explore les modèles de fondation de texte d'image, en se concentrant sur le modèle innovant de souscription contrastive (COCA). Coca combine uniquement les objectifs d'apprentissage contrastives et génératifs, intégrant les forces de modèles comme Clip et SimVlm dans une seule architecture.

Modèles de fondation: une plongée profonde
Les modèles de fondation, pré-formés sur des ensembles de données massifs, sont adaptables à diverses tâches en aval. Alors que la PNL a vu une surtension dans les modèles de fondation (GPT, Bert), les modèles de vision et de vision sont toujours en évolution. La recherche a exploré trois approches primaires: les modèles à encodeur unique, les deux codes à double texte avec une perte contrastive et les modèles de coder avec des objectifs génératifs. Chaque approche a des limites.
Termes clés:
- Modèles de fondation: Modèles pré-formés adaptables pour diverses applications.
- Perte contrastive: Une fonction de perte comparant des paires d'entrée similaires et différentes.
- Interaction intermodale: Interaction entre différents types de données (par exemple, image et texte).
- Architecture d'encodeur-décodeur: Une entrée de traitement du réseau neuronal et générer une sortie.
- Apprentissage zéro-shot: Prédire sur les classes de données invisibles.
- Clip: Un modèle de pré-formation d'image linguistique contrasté.
- simvlm: un modèle de langage visuel simple.
Comparaisons de modèle:
- Modèles d'encodeur uniques: Exceller dans les tâches de vision mais lutter contre les tâches en langue visuelle dues à la dépendance aux annotations humaines.
- Modèles à double encodeur de texte d'image (clip, aligner): Excellent pour la classification zéro et la récupération d'image, mais limité dans les tâches nécessitant des représentations de texte d'image fusionnées (par exemple, réponse à la question visuelle).
- Modèles génératifs (SIMVLM): Utilisez une interaction intermodale pour la représentation de texte d'image conjointe, adaptée à VQA et sous-titrage de l'image.
Coca: combler l'écart
Coca vise à unifier les forces des approches contrastives et génératives. Il utilise une perte contrastive pour aligner les représentations d'image et de texte et un objectif génératif (perte de sous-titrage) pour créer une représentation conjointe.
Architecture Coca:
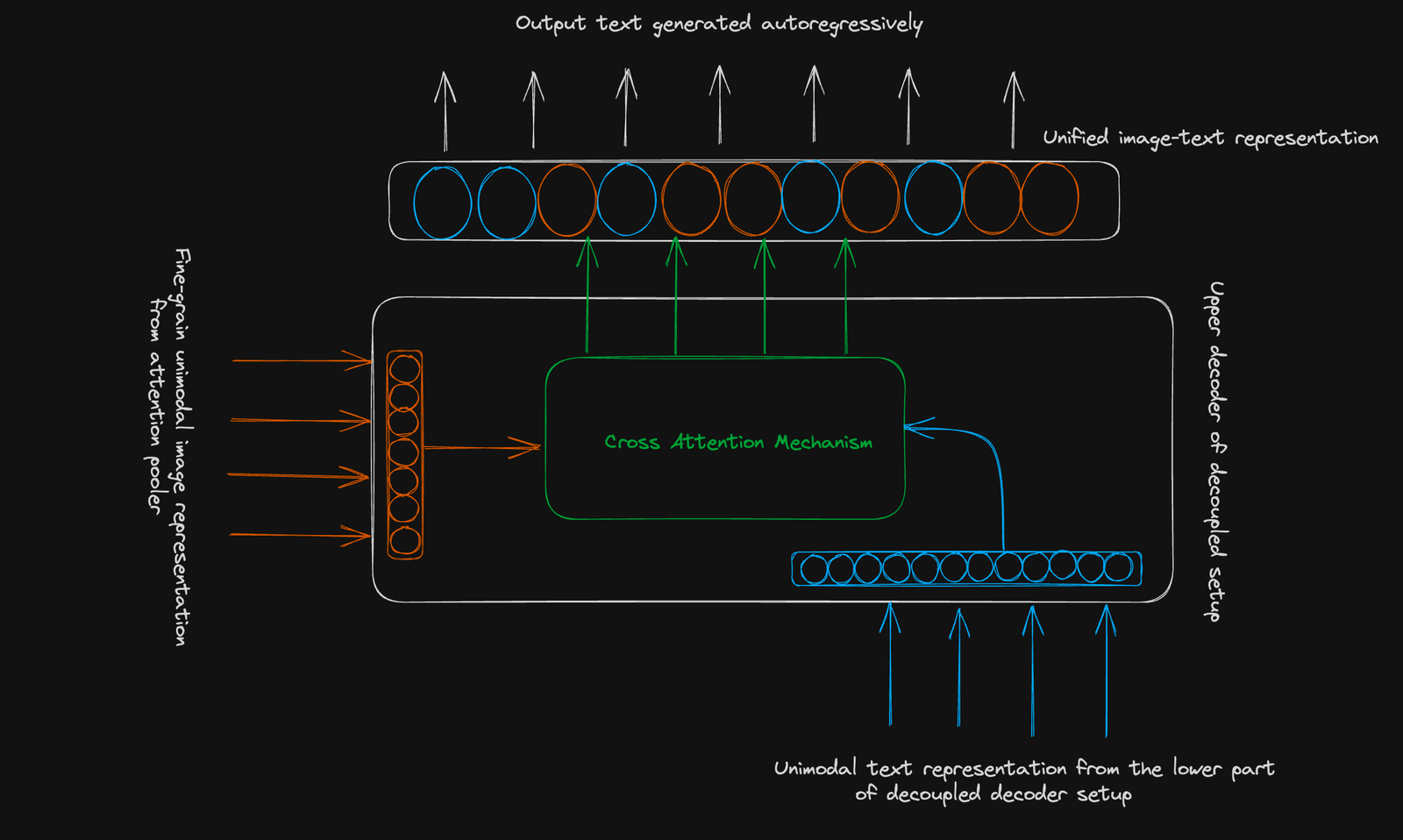
COCA utilise une structure de coder standard. Son innovation réside dans un décodeur découplé :
- Décodeur inférieur: génère une représentation de texte unimodale pour l'apprentissage contrastif (en utilisant un jeton [CLS]).
- Décodeur supérieur: génère une représentation de texte d'image multimodale pour l'apprentissage génératif. Les deux décodeurs utilisent le masquage causal.
Objectif contrastif: apprend à cluster des paires de texte d'image liées et à séparer les paires non liées dans un espace vectoriel partagé. Une seule image regroupée est utilisée.
Objectif génératif: utilise une représentation d'image à grain fin (séquence 256 dimension) et l'attention croisée-modale pour prédire le texte de manière autorégressive.

Conclusion:
COCA représente une progression significative dans les modèles de fondation de texte d'image. Son approche combinée améliore les performances dans diverses tâches, offrant un outil polyvalent pour les applications en aval. Pour approfondir votre compréhension des concepts avancés d'apprentissage en profondeur, considérez le cours avancé de Deep Learning with Keras de DataCamp.
Lire plus approfondie:
- Apprentissage des modèles visuels transférables de la supervision du langage naturel
- Pré-formation de texte d'image avec des légendes contrastives
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI