
Maison >Périphériques technologiques >IA >Comment la recherche-O1 améliore-t-elle le flux logique dans le raisonnement d'IA?
Comment la recherche-O1 améliore-t-elle le flux logique dans le raisonnement d'IA?

- Jennifer Anistonoriginal
- 2025-03-10 09:34:10746parcourir
Les progrès rapides de l'AI repoussent les limites des capacités de la machine, dépassant les attentes d'il y a quelques années à peine. Les grands modèles de raisonnement (LRMS, illustrés par OpenAI-O1) sont des systèmes sophistiqués s'attaquant aux problèmes complexes grâce à une approche étape par étape. Ces modèles ne résolvent pas seulement les problèmes; Ils raisonnent méthodiquement, employant un renforcement d'apprentissage à affiner leur logique et à produire des solutions détaillées et cohérentes. Ce processus délibéré, souvent appelé «pensée lente», améliore la clarté logique. Cependant, une limitation significative demeure: les lacunes de connaissances. Les LRM peuvent rencontrer des incertitudes qui propagent les erreurs, compromettant la précision finale. Les solutions traditionnelles comme l'augmentation de la taille du modèle et les ensembles de données en expansion, bien que utiles, ont des limitations, et même les méthodes de génération (RAG) de la récupération (RAG) luttent avec un raisonnement très complexe.
Search-O1, un cadre développé par des chercheurs de l'Université Renmin de Chine et de l'Université Tsinghua, aborde ces limites. Il intègre de manière transparente les instructions de tâche, les questions et les connaissances récupérées dynamiquement dans une chaîne de raisonnement cohérente, facilitant les solutions logiques. Search-O1 augmente les LRM avec un mécanisme de chiffon agentique et un module de moments de moments pour affiner les informations récupérées.
Table des matières
- Qu'est-ce que la recherche-o1?
- raisonnement traditionnel
- Rag agentique
- Le framework Search-O1
- Recherche-O1 Performance à travers les repères
- Science QA (gpoqa)
- Problèmes mathématiques
- livecodebench (raisonnement de code)
- Étude de cas de chimie à partir de l'ensemble de données GPQA
- le problème
- La stratégie du modèle
- raisonnement et solution
- Insignes clés
- Conclusion
Qu'est-ce que la recherche-o1?
Contrairement aux modèles traditionnels qui luttent avec des connaissances incomplètes ou des méthodes de chiffon de base qui récupèrent souvent des informations excessives et non pertinentes, Search-O1 introduit un module crucial module de moments dans les documents . Ce module distille les données étendues en étapes concises et logiques, assurant la précision et la cohérence.
Le cadre fonctionne de manière itérative, de recherche dynamiquement et d'extraction de documents pertinents, de les transformer en étapes de raisonnement précises et de affiner le processus jusqu'à ce qu'une solution complète soit obtenue. Il dépasse le raisonnement traditionnel (entravé par les lacunes de connaissances) et les méthodes de chiffon de base (qui perturbent le flux de raisonnement). Grâce à un Mécanisme agentique Pour l'intégration des connaissances et le maintien de la cohérence, Search-O1 assure un raisonnement fiable et précis, établissant une nouvelle norme pour la résolution de problèmes complexes en IA.
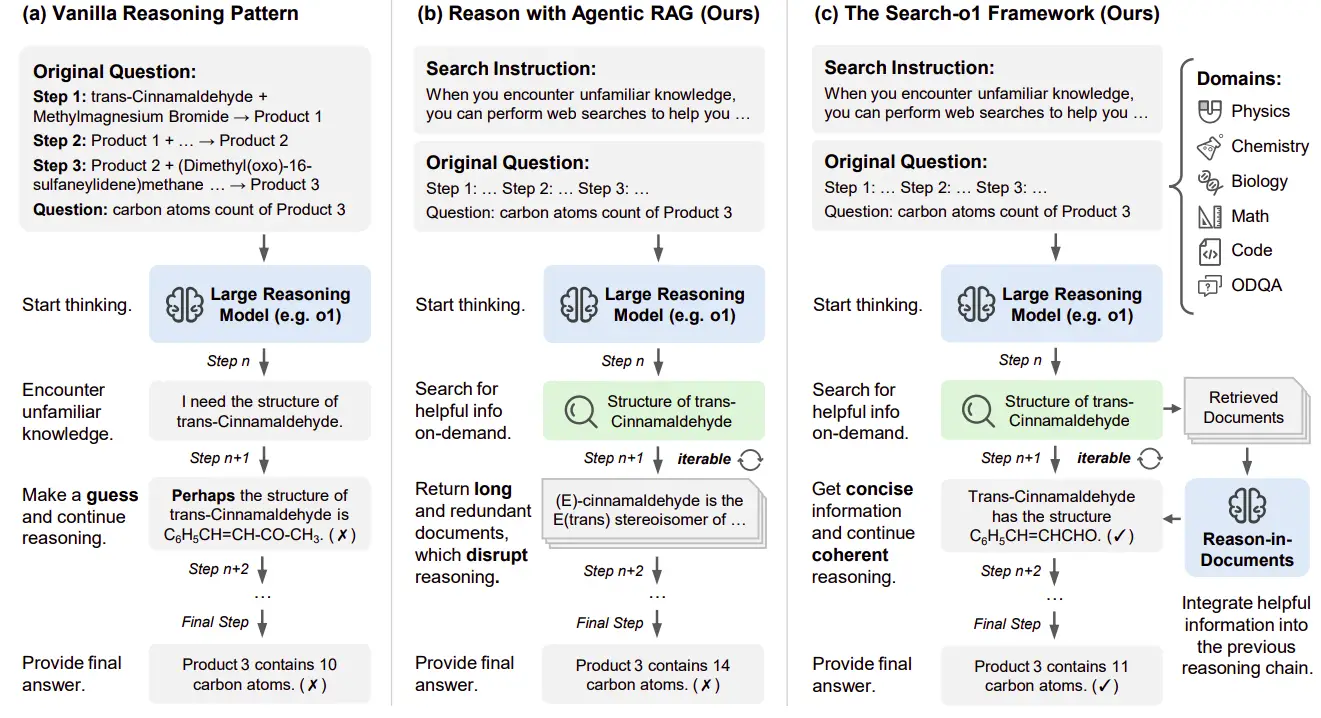
Search-O1 comble les lacunes de connaissances dans les LRM en intégrant de manière transparente la récupération des connaissances externes sans perturber le flux logique. La recherche a comparé trois approches: le raisonnement traditionnel, le chiffon agentique et le framework Search-O1.
1. Raisonnement traditionnel
déterminer le nombre d'atomes de carbone dans le produit final d'une réaction chimique en trois étapes en sert d'exemple. Les méthodes traditionnelles luttent lors de la rencontre des lacunes de connaissances, comme le manque de structure de trans-Cinnamaldéhyde . Sans informations précises, le modèle repose sur des hypothèses, ce qui entraîne potentiellement des erreurs.
2. Rag d'agence
Le chiffon agentique permet une récupération autonome des connaissances. S'il est incertain quant à la structure d'un composé, il génère des requêtes spécifiques (par exemple, "Structure de trans-Cinnamaldéhyde "). Cependant, l'incorporation directe des documents récupérés longs, souvent non pertinents, perturbe le processus de raisonnement et réduit la cohérence due à des informations verbales et tangentielles.
3. Search-O1
Search-O1 améliore le chiffon agentique avec le module de raisons de documents. Ce module affine des documents récupérés en étapes de raisonnement concises, intégrant de manière transparente les connaissances externes tout en préservant le flux logique. Compte tenu de la requête actuelle, des documents récupérés et de la chaîne de raisonnement en évolution, il génère des étapes cohérentes et interconnectées de manière itérative jusqu'à ce qu'une réponse concluante soit atteinte.
Recherche-O1 Performance à travers les repères
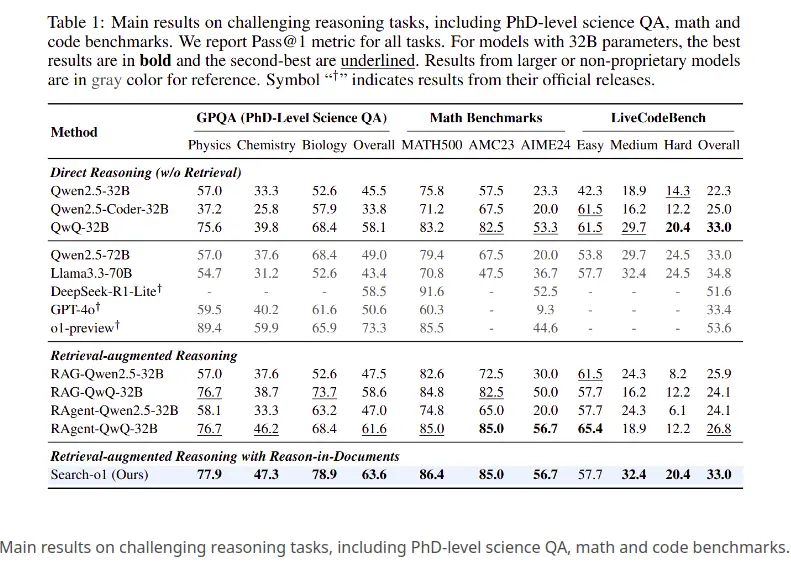
Trois tâches de raisonnement difficiles ont été évaluées:
- Advanced Science QA (Questions au niveau du doctorat en physique, chimie, biologie),
- Problèmes mathématiques complexes (problèmes difficiles de Math500 et AMC23),
- Défis de codage en direct (tâches de codage réel classées par difficulté).
1. Science QA (GPOQA)
- Raisonnement direct (pas de récupération): Des modèles comme QWEN2.5-32B (57,0%) et QWQ-32B (68,4%) sont à la traîne Search-O1 (77,9%).
- RÉSERVATION AUGMENTÉE DE RETRAITE: RAG-QWQ-32B (76,7%) a bien fonctionné, mais a toujours échoué à la précision de la recherche de recherche-O1 . Search-O1 a démontré des performances supérieures en physique (78,9%) et en chimie (47,3%).
- Raisonnement direct: QWQ-32B (83,2%) a obtenu le mieux parmi les méthodes directes, mais Search-O1 (86,4%) l'a dépassé.
- Responsable du raisonnement augmenté: RAG-QWQ-32B (85,0%) était proche, mais Search-O1 a maintenu une piste, mettant en évidence le bénéfice de son raisonnement structuré.
- Raisonnement direct: qwen2.5-coder-32b (22,5%) et QWQ-32B (33,0%) ont été surpassés par Search-O1 (33,0%).
- RÉSERVAUX DE RECOURALLE-RETRAITE: Méthodes de chiffon significativement sous-performé par rapport à Search-O1 .
Résultats de clés :
- Performance supérieure: Search-O1 a systématiquement surpassé d'autres méthodes en raison de son approche de raisonnement itérative.
- Module du module de raisons de raison: Ce module a assuré le raisonnement concentré, offrant un avantage sur les approches directes et de chiffon.
- robustesse: Alors que certaines méthodes excelaient dans des tâches spécifiques, Search-O1 a démontré des performances équilibrées dans toutes les catégories.
Étude de cas de chimie à partir de l'ensemble de données GPQA
Cette étude de cas illustre comment la recherche-O1 répond à une question de chimie de l'ensemble de données GPQA à l'aide du raisonnement auprès de la récupération.
Le problème
Déterminez le nombre d'atomes de carbone dans le produit final d'une réaction en plusieurs étapes impliquant le trans-Cinnamaldéhyde.La stratégie du modèle
- Décomposition du problème: Le modèle a analysé la réaction étape par étape, identifiant les composants clés et comment les atomes de carbone sont ajoutés.
- RECOURATION DE LES CONNAISSANCES EXTÉRIEURS: Le modèle a interrogé des informations sur les mécanismes de réaction, la récupération des données sur les réactions des réactifs de Grignard avec les aldéhydes et la structure du trans-Cinnamaldéhyde.
- Analyse de réaction ultérieure: L'atome de carbone suivi du modèle change tout au long de chaque étape de réaction.
- Vérification de la structure initiale: Le modèle a vérifié le nombre initial d'atomes de carbone dans le trans-Cinnamaldéhyde.
- Analyse de réaction finale: Le modèle a analysé la réaction finale, déterminant les atomes de carbone totaux dans le produit final.
Raisonnement et solution
Le modèle a conclu que le produit final contient 11 atomes de carbone (en commençant par 9, en ajoutant un de la réaction de Grignard, et un autre à l'étape finale). La réponse est 11.
Insignes clés
- Utilisation efficace des connaissances: Recherches ciblées ETTES DE CONNUTAIRES REMPLÉES.
- Raisonnement itératif: L'analyse étape par étape méthodique a assuré la précision.
- Vérification des erreurs: Le modèle a réévalué les hypothèses, assurant la précision.
Conclusion
Search-O1 représente une progression significative dans les LRM, abordant l'insuffisance des connaissances. En intégrant le chiffon agentique et le module de raisons en matière de documents, il permet un raisonnement itératif transparent qui intègre des connaissances externes tout en maintenant une cohérence logique. Ses performances supérieures dans divers domaines établissent une nouvelle norme pour la résolution complexe de problèmes dans l'IA. Cette innovation améliore la précision du raisonnement et ouvre des voies pour la recherche dans les systèmes de récupération, l'analyse des documents et la résolution intelligente de problèmes, combler l'écart entre la recherche de connaissances et le raisonnement logique. Search-O1 établit une base robuste pour l'avenir de l'IA, permettant des solutions plus efficaces à des défis complexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI