



Jina Embeddings V2: révolutionner l'intégration de texte à long document
Les modèles d'intégration de texte actuels, tels que Bert, sont limités par une limite de traitement de 512-token, entravant leurs performances avec de longs documents. Cette limitation entraîne souvent une perte de contexte et une compréhension inexacte. Jina incorpore V2 dépasse cette restriction en soutenant des séquences jusqu'à 8192 jetons, en préservant un contexte crucial et en améliorant considérablement la précision et la pertinence des informations traitées dans des textes étendus. Cela représente une progression majeure dans la gestion des données textuelles complexes.
Points d'apprentissage clés
- Comprendre les limites des modèles traditionnels comme Bert lors du traitement des documents longs.
- Apprendre comment Jina Embeddings V2 surmonte ces limites à travers sa capacité 8192 et son architecture avancée.
- Exploration des caractéristiques innovantes de Jina Embeddings V2, y compris Alibi, Glu, et sa méthodologie de formation en trois étapes.
- Découvrir les applications du monde réel dans la recherche juridique, la gestion du contenu et l'IA générative.
- acquérir une expérience pratique dans l'intégration de Jina Embeddings V2 dans des projets utilisant des bibliothèques de visage étreintes.
Cet article fait partie du blogathon de la science des données.
Table des matières
- Les défis de l'intégration de documents longs
- Innovations architecturales et méthodologie de formation
- Évaluation des performances
- Applications du monde réel
- Comparaison du modèle
- Utilisation de Jina Embeddings V2 avec un visage étreint
- Conclusion
- Les questions fréquemment posées
Les défis de l'intégration de documents longs
Traitement Les documents longs présentent des défis importants dans le traitement du langage naturel (NLP). Les méthodes traditionnelles traitent le texte dans les segments, conduisant à une troncature de contexte et à des intégres fragmentés qui dénaturent le document original. Il en résulte:
- augmentation des demandes de calcul
- Consommation de mémoire plus élevée
- Réduction des performances des tâches nécessitant une compréhension complète du texte
Jina Embeddings V2 aborde directement ces problèmes en augmentant la limite de jeton à 8192 , en éliminant le besoin d'une segmentation excessive et en maintenant l'intégrité sémantique du document.
Innovations architecturales et méthodologie de formation
Jina Embeddings V2 améliore les capacités de Bert avec des innovations de pointe:
- Attention avec les biais linéaires (Alibi): Alibi remplace les intérêts de position traditionnels avec un biais linéaire appliqué aux scores d'attention. Cela permet au modèle d'extrapoler efficacement les séquences beaucoup plus longtemps que celles rencontrées pendant l'entraînement. Contrairement aux implémentations unidirectionnelles précédentes, Jina Embeddings V2 utilise une variante bidirectionnelle, assurant la compatibilité avec les tâches de codage.
- Unités linéaires fermées (GLU): GLU, connue pour améliorer l'efficacité du transformateur, est utilisée dans les couches à action directe. Des variantes comme Geglu et Reglu sont utilisées pour optimiser les performances en fonction de la taille du modèle.
- Formation optimisée: Jina Embeddings V2 utilise un processus de formation en trois étapes:
- pré-entraînement: formé sur le corpus Colossal Clean Crawled (C4) en utilisant la modélisation du langage masqué (MLM).
- Fonction avec des paires de texte: Aligne des intégres pour des paires de texte sémantiquement similaires.
- Fonction d'adaptation négative dure: Améliore le classement et la récupération en incorporant des exemples de distracteur difficiles.
- Formation économe en mémoire: Techniques comme la formation de précision mixte et le point de contrôle d'activation Assurent l'évolutivité des plus grandes tailles de lots, cruciale pour l'apprentissage contrastif.

L'attention Alibi incorpore un biais linéaire dans chaque score d'attention avant l'opération Softmax. Chaque tête d'attention utilise un scalaire constant unique, m , diversifiant son calcul. Le modèle utilise la variante du codeur où tous les jetons s'occupent les uns des autres, contrairement à la variante causale utilisée dans la modélisation du langage.
Évaluation des performances
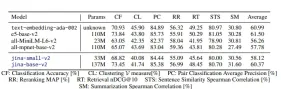
Jina Embeddings V2 atteint des performances de pointe dans diverses références, y compris le texte de référence en texte massif (MTEB) et de nouveaux ensembles de données à long terme. Les résultats clés incluent:
- Classification: Top précision dans les tâches comme Amazon Polarity et Toxic Conversations Classification.
- Clustering: surpasse les concurrents dans le regroupement des textes connexes (patentcluster et wikicities Clustering).
- Retrievale: Excelle dans des tâches comme narrativeqa, où le contexte complet du document est crucial.
- Gestion des documents longs: maintient la précision MLM même avec des séquences de 8192.
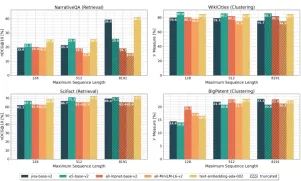
Ce graphique compare les performances du modèle d'intégration à travers les tâches de récupération et de clustering avec des longueurs de séquences variables.
Applications du monde réel
- Recherche juridique et académique: Idéal pour la recherche et l'analyse des documents juridiques et des articles académiques.
- Systèmes de gestion de contenu: Tagging, regroupement et récupération efficaces des grands référentiels de documents.
- AI génératif: Améliore les résumés générés par l'AI et les modèles basés sur l'invite.
- e-commerce: Améliore les systèmes de recherche et de recommandation de produits.
Comparaison du modèle
Jina Embeddings V2 excelle non seulement dans la manipulation de longues séquences, mais aussi en rivalisant avec des modèles propriétaires comme le texte-emballage d'Openai-ADA-002. Sa nature open source assure l'accessibilité.
Utilisation de Jina Embeddings V2 avec un visage étreint
Étape 1: Installation
!pip install transformers !pip install -U sentence-transformers
Étape 2: Utilisation des incorporations de jina avec des transformateurs
import torch
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a, b: (a @ b.T) / (norm(a) * norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
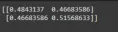
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
print(cos_sim(embeddings, embeddings))
Sortie:
Gestion des séquences longues:
embeddings = model.encode(['Very long ... document'], max_length=2048)
Étape 3: Utilisation des incorporations de jina avec des transformateurs de phrase
(Code similaire à l'aide de la bibliothèque sentence_transformers est fourni, ainsi que des instructions pour le réglage max_seq_length.)
Conclusion
Jina Embeddings V2 est une progression significative dans la PNL, abordant efficacement les limites du traitement des documents longs. Ses capacités améliorent les flux de travail existants et débloquent de nouvelles possibilités pour travailler avec du texte long.
Les plats clés à retenir (points clés résumés de la conclusion d'origine)
Questions fréquemment posées (Réponses résumées aux FAQ)
Remarque: Les images sont conservées dans leur format et leur emplacement d'origine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

![[GRATUIT] Qu'est-ce que Openai O3-MinI (Chatgpt O3mini High)? Expliquer les principales caractéristiques et l'utilisation!](https://img.php.cn/upload/article/001/242/473/174704017489264.jpg?x-oss-process=image/resize,p_40) [GRATUIT] Qu'est-ce que Openai O3-MinI (Chatgpt O3mini High)? Expliquer les principales caractéristiques et l'utilisation!May 12, 2025 pm 04:56 PM
[GRATUIT] Qu'est-ce que Openai O3-MinI (Chatgpt O3mini High)? Expliquer les principales caractéristiques et l'utilisation!May 12, 2025 pm 04:56 PMOpenai O3-Mini: un modèle d'inférence rentable et rentable Ces dernières années, OpenAI publie des modèles innovants, y compris la série GPT, en particulier, pour ses modèles de langage à grande échelle (LLM). OpenAI a publié le modèle dernier et rentable, l'Openai O3-Mini, spécialisé dans l'inférence. Ce modèle rapide et puissant offre des performances élevées dans des domaines tels que la science, les mathématiques et le codage, élargissant considérablement les possibilités des modèles à petite échelle. Dans cet article, nous présenterons Openai O3-Mini
 Quel est le mot ng dans le chatppt? Une explication approfondie de la liste et des mots interditsMay 12, 2025 pm 04:54 PM
Quel est le mot ng dans le chatppt? Une explication approfondie de la liste et des mots interditsMay 12, 2025 pm 04:54 PMMots tabous de Chatgpt: analyse complète et son impact Avec le développement rapide de la technologie de l'IA, Chatgpt, un robot de chat basé sur le traitement du langage naturel, a attiré beaucoup d'attention. Cependant, il existe des "mots tabous" qui nécessitent une attention dans l'utilisation de Chatgpt, qui limitent le contenu qu'ils génèrent. Cet article explorera en profondeur quels mots sont des mots tabous, pourquoi les mots tabous sont définis et comment ces mots affectent l'utilisation de Chatgpt. De plus, nous explorerons comment éviter les mots tabous et utiliser plus efficacement le chatppt. J'espère que cet article peut vous aider à gérer efficacement les risques éthiques et juridiques tout en tirant parti de votre plein potentiel. Le dernier agent d'IA d'Openai "Openai Deep Re"
 Une explication facile à comprendre sur la façon de se connecter à Chatgpt et comment démarrer en japonais!May 12, 2025 pm 04:45 PM
Une explication facile à comprendre sur la façon de se connecter à Chatgpt et comment démarrer en japonais!May 12, 2025 pm 04:45 PMChatgpt: un guide approfondi de l'inscription à la connexion et à l'utilisation de l'application! Ces dernières années, l'IA, y compris Chatgpt, a eu un impact majeur sur nos vies. Chatgpt attire l'attention en tant qu'IA qui permet des conversations naturelles, mais vous devez enregistrer un compte et vous connecter pour l'utiliser. Dans cet article, nous expliquerons de manière facile à comprendre pour les débutants, comment s'inscrire et se connecter à Chatgpt, comment démarrer la version de l'application et le dépannage. Veuillez vous référer à cela si vous songez à commencer à utiliser le chatppt ou avez du mal à vous inscrire. table des matières Journaux à Chatgpt
![[Openai] Qu'est-ce que O4-Mini? Expliquer les principales caractéristiques, l'utilisation et la structure des frais](https://img.php.cn/upload/article/001/242/473/174703939398912.jpg?x-oss-process=image/resize,p_40) [Openai] Qu'est-ce que O4-Mini? Expliquer les principales caractéristiques, l'utilisation et la structure des fraisMay 12, 2025 pm 04:43 PM
[Openai] Qu'est-ce que O4-Mini? Expliquer les principales caractéristiques, l'utilisation et la structure des fraisMay 12, 2025 pm 04:43 PMUne explication approfondie du dernier petit modèle d'IA, l'O4-MINI: à grande vitesse, à bas prix, haute performance! OpenAI a publié un nouveau petit modèle d'IA, l'O4-MinI. Contrairement au modèle phare "O3", son attrait est sa vitesse élevée et son prix bas. Dans cet article, nous expliquerons en détail les caractéristiques de l'O4-MinI, ses différences par rapport à l'O3, sa situation d'utilisation, sa sécurité et comment l'utiliser. table des matières Aperçu de O4-MinI Caractéristiques clés Environ O4-Mini-High Comment utiliser et structure des frais Utilisation et frais de l'API Utiliser avec Azure et Github Copilot
 La différence entre la version gratuite et la version payante de Chatgpt! Nous expliquons chacune de ces fonctionnalités et exemples d'utilisation!May 12, 2025 pm 04:41 PM
La différence entre la version gratuite et la version payante de Chatgpt! Nous expliquons chacune de ces fonctionnalités et exemples d'utilisation!May 12, 2025 pm 04:41 PMChatgpt: une comparaison approfondie entre la version gratuite et la version payante (Chatgpt Plus) peut vous aider à choisir la meilleure solution! Beaucoup de gens sont intéressés par les puissantes capacités de dialogue de Chatgpt et commencent à explorer ses applications dans la vie quotidienne et les affaires. Cependant, même s'ils sont attirés par Chatgpt, de nombreuses personnes n'ont toujours pas une compréhension suffisante de la différence entre la version gratuite et la version payante (Chatgpt Plus). Cet article comparera les fonctionnalités des versions gratuites et payantes de ChatGPT (ChatGpt Plus) pour expliquer en détail leurs avantages et la meilleure façon de choisir en fonction de leur objectif. La version payante offre de nombreux avantages supplémentaires tels que les vitesses de réponse plus rapides, l'accès prioritaire pendant les heures de pointe et l'accès précoce aux nouvelles fonctionnalités.
 Nous expliquons les frais, les méthodes de paiement pour ChatGPT4 et GPT4-O, et comment l'utiliser gratuitement!May 12, 2025 pm 04:40 PM
Nous expliquons les frais, les méthodes de paiement pour ChatGPT4 et GPT4-O, et comment l'utiliser gratuitement!May 12, 2025 pm 04:40 PMUne explication approfondie des plans de tarification de ChatGPT-4 et comment l'utiliser gratuitement! Choisir le meilleur plan et l'utiliser Nous expliquerons de manière facile à comprendre la structure de tarification pour le chatpt-4 d'Openai (et GPT-4O / GPT-4 Omni). Nous fournirons un aperçu complet des différences entre les plans gratuits et payants, les fonctionnalités du plan de 20 $ par mois, et comment utiliser le chatppt-4 gratuitement. De la sélection d'un plan de prix à l'utiliser gratuitement, au téléchargement des applications officielles, nous fournissons des informations sur la façon d'utiliser efficacement le chatppt-4. Prix de chatppt-4o (omni) Chatppt-
 12 exemples d'utilisation de chatppt dans les entreprises! Nous expliquons également les avantages et les points à noterMay 12, 2025 pm 04:37 PM
12 exemples d'utilisation de chatppt dans les entreprises! Nous expliquons également les avantages et les points à noterMay 12, 2025 pm 04:37 PMChatgpt: Exemples de directives d'utilisation et de mise en œuvre pour les entreprises Ces dernières années, l'évolution de la technologie de l'IA a été remarquable, et Chatgpt a attiré beaucoup d'attention dans les domaines des chatbots et du traitement du langage naturel. Cet article présente des exemples spécifiques d'utilisation de Chatgpt dans les entreprises et explique les avantages de la mise en œuvre, des risques et des directives efficaces pour l'élaboration. Explorez les possibilités de Chatgpt à travers des exemples dans une variété d'industries, notamment la fabrication, l'alimentation, la finance, la vente au détail et l'éducation. Pour plus d'informations sur le dernier agent d'IA d'OpenAI, "Openai Deep Research", cliquez ici.
 Qu'est-ce que le chatppt 4.5 (GPT-4.5)? Nous expliquons comment l'utiliser, les frais et les comparaisons avec 4O! !May 12, 2025 pm 04:35 PM
Qu'est-ce que le chatppt 4.5 (GPT-4.5)? Nous expliquons comment l'utiliser, les frais et les comparaisons avec 4O! !May 12, 2025 pm 04:35 PMLe dernier modèle AI Chatgpt 4.5 (GPT-4.5) publié par OpenAI a des améliorations complètes des performances, avec des capacités de dialogue plus naturelles et lisses, des capacités de raisonnement plus fortes et une intelligence émotionnelle plus élevée (EQ). Cet article explorera GPT-4.5 en profondeur et analysera ses caractéristiques de manière complète. Nous couvrirons ses principales caractéristiques, la comparaison avec GPT-4 et GPT-4O, des caractéristiques spécifiques, des stratégies de tarification, des mesures de sécurité et divers cas d'application. Table des matières Chatgpt 4.5 (GPT-4.5) Introduction Chatgpt 4.5 (GPT-4.5) Performance détaillée Extension de l'apprentissage non supervisé Dialogue plus naturel EQ supérieur (empathie) Amélioration factuelle (réduire les hallucinations) base de connaissances pousser


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

mPDF
mPDF est une bibliothèque PHP qui peut générer des fichiers PDF à partir de HTML encodé en UTF-8. L'auteur original, Ian Back, a écrit mPDF pour générer des fichiers PDF « à la volée » depuis son site Web et gérer différentes langues. Il est plus lent et produit des fichiers plus volumineux lors de l'utilisation de polices Unicode que les scripts originaux comme HTML2FPDF, mais prend en charge les styles CSS, etc. et présente de nombreuses améliorations. Prend en charge presque toutes les langues, y compris RTL (arabe et hébreu) et CJK (chinois, japonais et coréen). Prend en charge les éléments imbriqués au niveau du bloc (tels que P, DIV),

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

