

 Périphériques technologiquesIADécodage des capacités de raisonnement avancées Deepseek R1 & # 039;
Périphériques technologiquesIADécodage des capacités de raisonnement avancées Deepseek R1 & # 039;
Les capacités de raisonnement avancées de Deepseek-R1 en ont fait le nouveau leader dans le domaine génératif LLM. Cela a provoqué une éloge de l'industrie de l'IA, avec des rapports sur la perte de 600 milliards de dollars de NVIDIA après le lancement. Mais qu'est-ce qui rend Deepseek-R1 si célèbre du jour au lendemain? Dans cet article, nous explorerons pourquoi Deepseek-R1 attire autant d'attention, plongez-vous dans ses capacités révolutionnaires et analyse comment ses pouvoirs de raisonnement remodèlent les applications du monde réel. Restez à l'écoute pendant que nous décomposons les performances du modèle grâce à une analyse détaillée et structurée.
Objectifs d'apprentissage
- Comprendre les capacités de raisonnement avancées de Deepseek-R1 et son impact sur le paysage LLM.
- Apprenez comment l'optimisation des politiques relatives de groupe (GRPO) améliore l'apprentissage du renforcement sans modèle critique.
- Explorez les différences entre Deepseek-R1-Zero et Deepseek-R1 en termes de formation et de performance.
- Analyser les mesures d'évaluation et les repères qui présentent la supériorité de Deepseek-R1 dans les tâches de raisonnement.
- Découvrez comment Deepseek-R1 optimise les tâches de la tige et du codage avec des modèles AI évolutifs et à haut débit.
Cet article a été publié dans le cadre du Data Science Blogathon.
Table des matières
- Qu'est-ce que Deepseek-R1?
- Qu'est-ce que l'optimisation de la politique relative du groupe (GRPO)?
- Processus de formation et optimisation dans Deepseek-R1-Zero
- Comment fonctionne GRPO?
- Deepseek-R1
- Évaluation de Deepseek-R1
- Évaluation des capacités de raisonnement de Deepseek-R1-7B
- Raisonnement avancé et scénario de résolution de problèmes
- CONCLUSION
- Questions fréquemment posées
Qu'est-ce que Deepseek-R1?
En mots simples, Deepseek-R1 est une série de modèles de langage de pointe développée par Deepseek, établie en 2023 par Liang Wenfeng. Il a atteint des capacités de raisonnement avancées dans les LLM par l'apprentissage par renforcement (RL). Il y a deux variantes:
Deepseek-R1-Zero
Il est formé uniquement via RL sur le modèle de base sans réglage fin supervisé (SFT), et il développe de manière autonome un comportement de raisonnement avancé comme l'auto-vérification et la réflexion en plusieurs étapes, atteignant une précision de 71% sur la référence AIME 2024
deepseek-r1
Il a été amélioré avec les données de démarrage à froid et la formation en plusieurs étapes (RL SFT), il aborde les problèmes de lisibilité et surpasse O1 d'Openai sur des tâches telles que Math-500 (97,3% de précision) et les défis de codage (codés de codes 2029)
Deepseek utilise l'optimisation des politiques relatives du groupe (GRPO), une technique RL qui n'utilise pas le modèle de critique et économise les coûts de formation de RL. GRPO optimise les politiques en regroupant les sorties et en normalisant les récompenses, éliminant le besoin des modèles de critique.
Le projet distille également ses modèles de raisonnement en modèles plus petits (1,5b-70b), permettant un déploiement efficace. Selon la référence, c'est le modèle 7B dépasse GPT-4O.
Papier Deepseek-R1 ici.
Tableau de comparaison
| Model | GPQA | LiveCode | Diamond Bench | CodeForces pass@1 cons@64 | CodeForces pass@1 | Rating |
|---|---|---|---|---|---|---|
| OpenAI-01-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| OpenAI-01-0912 | 74.4 | 83.3 | 94.8 | 77.3 | 63.4 | 1843 |
| DeepSeek-R1-Zero | 71.0 | 86.7 | 95.9 | 73.3 | 50.0 | 1444 |
PROCACTION DE PRÉSURCTION de Deepseek-R1-Zero sur l'ensemble de données AIME
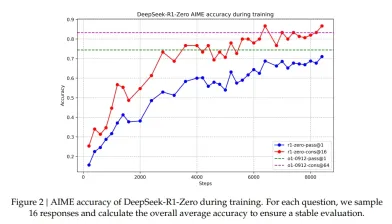
Deepseek open d'open source, les modèles, les pipelines de formation et les références visent à démocratiser les recherches de raisonnement axées sur la RL, offrant des solutions évolutives pour les TEM, le codage et les tâches à forte intensité de connaissances. Deepseek-R1 dirige un chemin vers la nouvelle ère des SLM et LLMS à faible coût et à haut débit.
Qu'est-ce que l'optimisation de la politique relative du groupe (GRPO)?
Avant d'entrer dans le GRPO de pointe, surfons sur certaines bases de l'apprentissage du renforcement (RL).
L'apprentissage du renforcement est l'interaction entre l'agent et l'environnement. Pendant la formation, l'agent prend des mesures afin qu'elle maximise les récompenses cumulatives. Pensez à un bot jouant des échecs ou un robot sur un plancher d'usine essayant de faire des tâches avec des articles réels.
L'agent apprend en faisant. Il obtient une récompense quand il fait les choses correctement; Sinon, cela devient négatif. En faisant ces essais répétitifs, ce sera en voyage pour trouver la stratégie optimale pour s'adapter à l'environnement inconnu.
Voici le schéma simple de l'apprentissage du renforcement, il a 3 composants:
Core RL LOOP
- Agent qui prend des mesures en fonction de la politique apprise.
- L'action est la décision prise par l'agent à un état donné.
- L'environnement est le système externe (jeu, plancher d'atelier, drone volant, etc.) où l'agent fonctionne et apprend en interagissant.
- L'environnement fournit des commentaires à l'agent sous la forme d'un nouvel état et des récompenses.
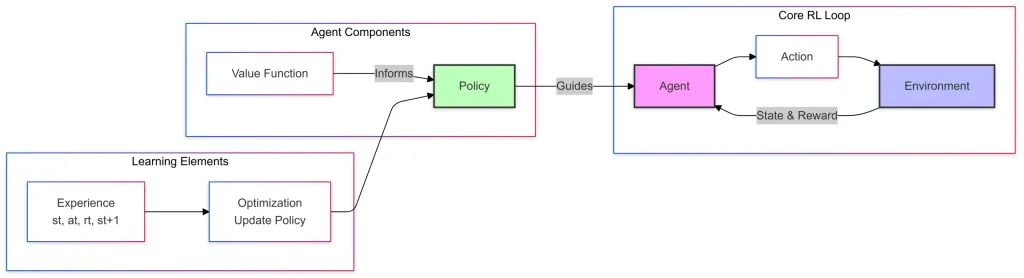
Composants de l'agent
- La fonction de valeur estime à quel point un état ou une action particulière est bon en termes de récompenses à long terme
- La politique est une stratégie qui définit la sélection d'action de l'agent.
- La fonction de valeur informe la politique en l'aidant à améliorer la prise de décision
- La politique guide (Guides Relation) L'agent dans le choix des actions dans les boucles RL
Éléments d'apprentissage
- Expérience, ici l'agent collecte les transactions tout en interagissant avec l'environnement.
- Les mises à jour d'optimisation ou de stratégie utilisent l'expérience pour affiner la politique et la prise de décision importante.
Processus de formation et optimisation dans Deepseek-R1-Zero
L'expérience recueillie est utilisée pour mettre à jour la politique par optimisation. La fonction de valeur fournit des informations pour affiner la politique. La politique guide l'agent, qui interagit avec l'environnement pour collecter de nouvelles expériences et que le cycle continue jusqu'à ce que l'agent apprenne la stratégie optimale ou s'améliore pour s'adapter à l'environnement.
Dans la formation de Deepseek-R1-Zero, ils utilisent l'optimisation relative de la politique relative du groupe ou GRPO, il élimine le modèle de critique et réduit le coût de formation.
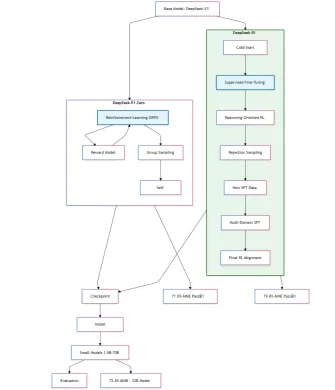
Quant à ma compréhension du document de recherche Deepseek-R1, voici le processus de formation schématique des modèles Deepseek-R1-Zero et Deepseek-R1.
Schéma de formation Deepseek-R1-Zero et R1 provisoire
Comment fonctionne le GRPO?
Pour chaque question Q, GRPO échantillonne un groupe de sortie {O1, O2, O2 ..} de l'ancienne politique et optimise le modèle de politique en maximisant l'objectif ci-dessous:

Ici Epsilon et Beta sont des hyper-paramètres, et A_I est l'avantage calculé en utilisant un groupe de récompenses {R1, R2, R3… RG} correspondant à la sortie de chaque groupe.
Calcul de l'avantage
Dans le calcul de l'avantage, normaliser les récompenses dans les sorties de groupe, r_i est la récompense de la sortie I et R_Group est les récompenses de toutes les sorties du groupe.
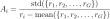
pour maximiser les mises à jour des politiques coupées avec la pénalité KL,
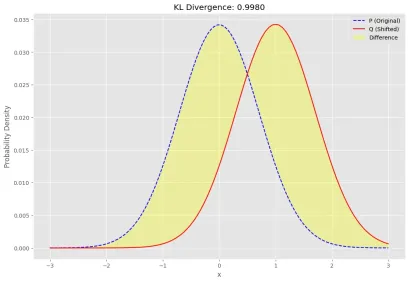
Kullback-lebler Divergence
La divergence KL également connue sous le nom d'entropie relative est une fonction de distance statistique, qui mesure la différence entre la distribution de probabilité du modèle (Q) et la distribution de probabilité réelle (P).
pour plus de kl-divergence
L'équation ci-dessous est la forme mathématique de la divergence Kl:

L'entropie relative ou la distance KL est toujours un nombre réel non négatif. Il a la valeur la plus basse de 0 si et seulement si les Q et P sont identiques. Cela signifie à la fois la distribution de probabilité du modèle (Q) et la distribution de probabilité réelle (p) chevauchent ou un système parfait.
Exemple de divergence kl
Voici des exemples simples pour présenter la divergence KL,
Nous utiliserons la fonction d'entropie à partir du package statistique Scipy, il calculera l'entropie relative entre deux distributions.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
notre P et Q comme une distribution gaussienne de type gaussien et décalé respectivement.
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()
La partie jaune est la différence KL entre P et Q.
Dans l'équation GRPO, GRPO échantillonne un groupe de sorties pour chaque requête et calcule les avantages par rapport à la moyenne et à l'écart type du groupe. Cela évite de former un modèle de critique distinct. L'objectif comprend un ratio coupé et une pénalité KL pour rester près de la politique de référence.
La partie du rapport est le rapport de probabilité de la nouvelle et ancienne politique. CLIP (rapport) est liée entre le 1-EPSilon et le 1 Epsilon.
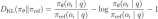
Le processus de conversation entre l'utilisateur et l'assistant
L'utilisateur pose une question, et le modèle ou l'assistant le résout en réfléchissant d'abord au processus de raisonnement, puis en répondant à l'utilisateur.
Le raisonnement et la réponse sont enfermés dans le diagramme ci-dessous.

import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
Le processus d'auto-évolution de Deepseek-R1-Zero montre comment l'apprentissage du renforcement peut améliorer de manière autonome les capacités de raisonnement du modèle. Le graphique montre comment les capacités de raisonnement du modèle pour gérer les tâches de raisonnement complexes évoluent.
Améliorer le raisonnement et les capacités générales dans Deepseek-R1
Deepseek-R1, répond à deux questions significatives qui se posent après les résultats prometteurs du modèle zéro.
- Les performances du raisonnement peuvent-elles être encore améliorées?
- Comment pouvons-nous former un modèle convivial qui produit non seulement une chaîne de pensée claire et cohérente (COT) mais démontre également de fortes capacités générales?
Le Deepseek-R1 utilise des données de démarrage à froid dans un format où le développeur recueille des milliers de données de démarrage à froid pour affiner la base Deepseek-V3 comme point de départ de Rl.

Ces données présentent deux avantages importants par rapport à Deepseek-R1-Zero.
- lisibilité : Une limitation clé du modèle zéro est que son contenu ne convient pas à la lecture. Les réponses sont mélangées avec de nombreuses langues, et pas bien formatées pour mettre en évidence les réponses pour les utilisateurs.
- Potentiel : Lead Expert concevant le modèle de données de démarrage à froid pour aider à de meilleures performances contre Deepseek-R1-Zero.
Évaluation de Deepseek-R1
Selon le papier Deepseek-R1, ils (le développeur) ont réglé la longueur de génération maximale sur 32768 jetons pour les modèles. Ils ont trouvé que le modèle de raisonnement à long terme entraîne des taux de répétition plus élevés avec un décodage gourmand et une variabilité significative. Par conséquent, ils utilisent l'évaluation PASS @ k, il utilise une température d'échantillonnage de 0,6 et une valeur Top-P de 0,95 pour générer une réponse des nombres k pour chaque question.
passer @ 1 est ensuite calculé comme:

Ici, P_i désigne l'exactitude de la i-thème réponse, selon le document de recherche, cette méthode garantit des estimations de performance plus fiables.

Nous pouvons voir que les repères de connaissances axés sur l'éducation tels que MMLU, MMLU-PRO, GPQA Diamond et Deepseek-R1 fonctionnent mieux par rapport à Deepseek-V3. Il a principalement une précision améliorée dans les questions liées aux STEM. Deepseek-R1 fournit également d'excellents résultats sur IF-Eval, des données de référence conçues pour évaluer la capacité du modèle à suivre les instructions de format.
suffisamment de mathématiques et une compréhension théorique ont été effectuées, ce qui souhaite augmenter considérablement vos connaissances globales de l'apprentissage du renforcement et son application de pointe sur le développement du modèle Deepseek-R1. Maintenant, nous allons mettre la main sur Deepseek-R1 en utilisant Olllama et goûterons le LLM nouvellement créé
Évaluation des capacités de raisonnement de Deepseek-R1-7B
L'évaluation de Deepseek-R1-7B se concentre sur ses capacités de raisonnement améliorées, en particulier ses performances dans des scénarios complexes de résolution de problèmes. En analysant les références clés, cette évaluation donne un aperçu de l'efficacité du modèle gère les tâches de raisonnement complexe par rapport à ses prédécesseurs.
ce que nous voulons réaliser
- Évaluer les capacités de raisonnement de Deepseek-R1 dans différents domaines cognitifs
- Identifier les forces et les limitations dans des tâches de raisonnement spécifiques
- Comprendre les applications potentielles du monde réel du modèle
Configurer l'environnement
- Installer Olllama depuis
- Après l'avoir installé sur votre système, ouvrez votre terminal et tapez la commande ci-dessous, il téléchargera et démarrera le modèle Deepseek-R1 7B.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
Maintenant, je pose une question d'inégalité linéaire de NCERT
Q.Solve 4x 3 & lt; 6x 7
et la réponse est:

qui est exact selon le livre.
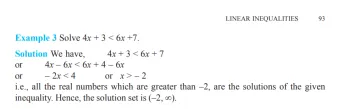
incroyable !!
va maintenant mettre en place un environnement de test à l'aide de Llamaindex qui sera un moyen plus important de le faire.
Environnement de test de configuration
# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
Maintenant, nous installons les packages nécessaires
Installer les packages
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()
ouvrir maintenant vscode et créer un nom de note de jupyter invite_analysis.ipynb racine du dossier du projet.
Importer les bibliothèques
<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Vous devez rester à courir Olllama Deepseek-R1: 7b sur votre terminal.
Maintenant, commencez par le problème mathématique
Imporant: La sortie sera très longue, donc la sortie de ce blog sera abrégée, pour une sortie complète, vous devez voir le référentiel de code du blog ici.
Scénario de raisonnement avancé et de résolution de problèmes
Cette section explore des tâches complexes de résolution de problèmes qui nécessitent une compréhension approfondie de diverses techniques de raisonnement, des calculs mathématiques aux dilemmes éthiques. En vous engageant avec ces scénarios, vous améliorerez votre capacité à penser de manière critique, à analyser les données et à tirer des conclusions logiques dans divers contextes.
Problème mathématique: Discount et calcul de la carte de fidélité
Un magasin offre une remise de 20% sur tous les articles. Après avoir appliqué la remise, il y a 10% de réduction supplémentaire pour les membres de la carte de fidélité. Si un article coûte à l'origine 150 $, quel est le prix final pour un membre de la carte de fidélité? Montrez votre calcul étape par étape et expliquez votre raisonnement.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
Sortie:

L'aspect clé de cette invite est:
- Capacité de calcul séquentielle
- compréhension des concepts en pourcentage
- raisonnement étape par étape
- Clarité de l'explication.
Raisonnement logique: identifier les contradictions dans les déclarations
Considérez ces déclarations: tous les oiseaux peuvent les flypeguins sont les oiseaux des oiseaux ne peuvent pas identifier aucune contradiction dans ces déclarations. S'il y a des contradictions, expliquez comment les résoudre en utilisant le raisonnement logique.
# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
Sortie:

Cela montrera la cohérence logique, proposera des solutions logiques, comprendra les relations de classe et le raisonnement syllogiste.
Analyse de la chaîne causale: impact de l'écosystème d'une maladie sur les loups
Dans un écosystème forestier, une maladie tue 80% de la population de loups. Décrivez la chaîne potentielle des effets que cela pourrait avoir sur l'écosystème au cours des 5 prochaines années. Incluez au moins trois niveaux de cause à effet et expliquez votre raisonnement pour chaque étape.
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()
Sortie:

Ce modèle rapide montre la compréhension des systèmes complexes, suit plusieurs chaînes décontractées, considère les effets indirects et applique les connaissances du domaine.
Reconnaissance du modèle: identifier et expliquer les séquences de nombres
Considérez cette séquence: 2, 6, 12, 20, 30, __ quel est le numéro suivant?
- Expliquez le motif
- Créez une formule pour le nième terme.
- Vérifiez que votre formule fonctionne pour tous les numéros donnés
<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Sortie:

Le modèle excelle à identifier les modèles numériques, à générer des formules mathématiques, à expliquer le processus de raisonnement et à vérifier la solution.
Problème de probabilité: calculer les probabilités avec des billes
Un sac contient 3 billes rouges, 4 billes bleues et 5 billes vertes. Si vous dessinez deux billes sans remplacement:
- Quelle est la probabilité de dessiner deux billes bleues?
- Quelle est la probabilité de dessiner des billes de différentes couleurs?
Afficher tous les calculs et expliquez votre approche.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
Sortie:

Le modèle peut calculer les probabilités, gérer les problèmes conditionnels et expliquer le raisonnement probabiliste.
Débogage: erreurs logiques dans le code et leurs solutions
Ce code a des erreurs logiques qui l'empêchent d'exécuter correctement.
# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
- Identifier tous les problèmes potentiels
- Expliquez pourquoi chacun est un problème
- Fournir une version corrigée
- Expliquez pourquoi votre solution est meilleure
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()
Sortie:


Deepseek-R1 trouve des cas Edge, comprend les conditions d'erreur, applique la correction et explique la solution technique.
Analyse comparative: voitures électriques vs à essence
Comparez les voitures électriques et les voitures d'essence traditionnelles en termes de:
- Impact environnemental
- coût à long terme
- commodité
- Performance
Pour chaque facteur, fournissez des exemples et des points de données spécifiques. Ensuite, expliquez quel type de voiture serait mieux pour:
- un habitant de la ville avec un court trajet
- un vendeur itinérant qui conduit 30 000 miles par an
justifier vos recommandations.
<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Sortie:
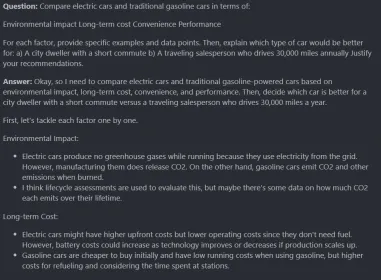
C'est une énorme réponse, j'ai adoré le processus de raisonnement. Il analyse plusieurs facteurs, considère le contexte, fait de belles recommandations et équilibre les priorités concurrentes.
Dilemme éthique: la prise de décision dans les voitures autonomes
Une voiture autonome doit prendre une décision de fraction de seconde:
- Swerve à gauche: frappez deux piétons
- Swerve à droite: frappez un mur, blessant gravement le passager
- Swerve à droite: frappez un mur, blessant gravement le passager
Que devrait faire la voiture? Fournissez votre raisonnement, considérant:
- Frameworks éthiques utilisés
- Hypothèses faites
- Hiérarchie prioritaire
- Implications à long terme
$ollama run deepseek-r1:7b
Sortie:

Ces types de problèmes sont les plus problématiques pour les modèles d'IA génératifs. Il teste le raisonnement éthique, les perspectives multiples, les dilemmes moraux et les jugements de valeur. Dans l'ensemble, c'était un puits. Je pense que plus le réglage fin spécifique au domaine éthique produira une réponse plus profonde.
Analyse statistique: évaluation des revendications de l'étude sur la consommation de café
Une étude prétend que les buveurs de café vivent plus longtemps que les buveurs non coffee. L'étude a observé 1000 personnes âgées de 40 à 50 ans pendant 5 ans.
Identifier:
- Variables de confusion potentielles
- biais d'échantillonnage
- Explications alternatives
- Quelles données supplémentaires renforceraient ou affaibliraient la conclusion?
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
Sortie:

Il comprend assez bien les concepts statistiques, identifie les limites de recherche et la pensée critique sur les données et propose des améliorations méthodologiques.
Analyse des séries chronologiques
# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
Sortie:

Deepseek aime les problèmes mathématiques, gère la désintégration exponentielle, fournit de bons modèles mathématiques et fournit des calculs.
Tâche de planification
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()
Sortie:

Il peut gérer plusieurs contraintes, produire des horaires optimisés et fournir le processus de résolution de problèmes.
Analyse du domaine croisé
<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Sortie:

Il a bien fait le travail de comparer différents types de domaines, ce qui est très impressionnant. Ce type de raisonnement aide différents types de domaines enchevêtrés afin que les problèmes d'un domaine puissent être résolus par les solutions d'autres domaines. Il aide à la recherche sur la compréhension du domaine croisé.
Bien que vous puissiez expérimenter de nombreuses invites d'exemples avec le modèle sur vos systèmes locaux sans dépenser de centime. J'utiliserai Deepseek-R1 pour plus de recherches et j'apprendrai différents domaines. Tout ce dont vous avez besoin est un ordinateur portable, votre temps et un bel endroit.
tout le code utilisé dans cet article ici.
Conclusion
Deepseek-R1 montre des capacités prometteuses à travers diverses tâches de raisonnement, présentant ses capacités de raisonnement avancées dans l'analyse logique structurée, la résolution de problèmes étape par étape, la compréhension multi-contexte et l'accumulation de connaissances à partir de différents sujets. Cependant, il existe des domaines d'amélioration, tels que le raisonnement temporel complexe, la gestion de l'ambiguïté profonde et la génération de solutions créatives. Plus important encore, cela montre comment un modèle comme Deepseek-R1 peut être développé sans le fardeau des énormes coûts de formation des GPU.
Son modèle open source pousse l'IA vers des royaumes plus démocratiques. De nouvelles recherches seront bientôt menées sur cette méthode de formation, conduisant à des modèles d'IA plus puissants et plus puissants avec des capacités de raisonnement encore meilleures. Alors que AGI peut encore être dans un avenir lointain, les avancées de Deepseek-R1 pointent vers un avenir où AGI émergera main dans la main avec les gens. Deepseek-R1 est sans aucun doute une étape clé pour réaliser des systèmes de raisonnement IA plus avancés.
Les plats clés
- Les capacités de raisonnement avancées de Deepseek R1 brillent à travers sa capacité à effectuer une analyse logique structurée, à résoudre des problèmes étape par étape et à comprendre des contextes complexes dans différents domaines.
- Le modèle repousse les limites du raisonnement en accumulant les connaissances à partir de divers sujets, démontrant une impressionnante compréhension multi-contextuelle qui la distingue des autres LLMS génératifs.
- Malgré ses forces, les capacités de raisonnement avancées de Deepseek R1 sont toujours confrontées à des défis dans des domaines tels que le raisonnement temporel complexe et la manipulation de l'ambiguïté, ce qui ouvre la porte à des améliorations futures.
- En créant le modèle open-source, Deepseek R1 fait non seulement un raisonnement, mais rend également l'IA de pointe plus accessible, offrant une approche plus démocratique du développement de l'IA.
- Les capacités de raisonnement avancées de Deepseek R1 ouvrent la voie à de futures percées dans les modèles d'IA, avec le potentiel pour AGI d'émerger par la recherche et l'innovation continues.
Les questions fréquemment posées
q 1. Comment Deepseek-R1-7B se compare-t-il aux grands modèles dans les tâches de raisonnement?a. Bien qu'il ne corresponde pas à la puissance des modèles 32b ou 70b plus grands, il montre des performances comparables dans les tâches de raisonnement de structure, en particulier dans l'analyse mathématique et logique.
Q 2. Quelles sont les meilleures pratiques pour la conception rapide lors du test du raisonnement?a. Écrivez des exigences étape par étape, concentrez-vous sur des instructions claires et des critères d'évaluation explicites. Les questions en multiparage donnent souvent une meilleure perspicacité que les questions uniques.
q 3. Dans quelle mesure ces méthodes d'évaluation sont-elles fiables? a. Nous sommes humains, nous devons utiliser notre cerveau pour évaluer la réponse. Il doit être utilisé dans le cadre d'une stratégie d'évaluation plus large qui comprend des mesures quantitatives et des tests du monde réel. Suivre ce principe aidera une meilleure évaluation.
Human-> invite-> Ai-> Réponse-> humain -> Réponse réelle
Le média présenté dans cet article ne appartient pas à l'analyse vidhya et est utilisé à la discrétion de l'auteur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Vous devez construire un lieu de travail dans un voile d'ignoranceApr 29, 2025 am 11:15 AM
Vous devez construire un lieu de travail dans un voile d'ignoranceApr 29, 2025 am 11:15 AMDans le livre de 1971 de John Rawls, The Theory of Justice, il a proposé une expérience de pensée que nous devrions prendre en tant que noyau de la conception de l'IA d'aujourd'hui et utilise la prise de décision: le voile de l'ignorance. Cette philosophie fournit un outil simple pour comprendre l'équité et fournit également un plan pour les dirigeants afin d'utiliser cette compréhension pour concevoir et mettre en œuvre l'IA de manière équitable. Imaginez que vous établissez des règles pour une nouvelle société. Mais il y a une prémisse: vous ne savez pas à l'avance quel rôle vous allez jouer dans cette société. Vous pouvez finir par être riche ou pauvre, sain ou handicapé, appartenant à une minorité majoritaire ou marginale. Opérant dans le cadre de ce «voile d'ignorance» empêche les décideurs de prendre des décisions qui bénéficient elles-mêmes. Au contraire, les gens seront plus motivés pour formuler le public
 Décisions, décisions… les prochaines étapes pour une IA appliquée pratiqueApr 29, 2025 am 11:14 AM
Décisions, décisions… les prochaines étapes pour une IA appliquée pratiqueApr 29, 2025 am 11:14 AMDe nombreuses entreprises se spécialisent dans l'automatisation des processus robotiques (RPA), offrant des robots pour automatiser les tâches répétitives - UIPATH, l'automatisation n'importe où, le prisme bleu et autres. Pendant ce temps, l'exploitation de processus, l'orchestration et le traitement des documents intelligents spécialis
 Les agents arrivent - plus sur ce que nous ferons à côté des partenaires de l'IAApr 29, 2025 am 11:13 AM
Les agents arrivent - plus sur ce que nous ferons à côté des partenaires de l'IAApr 29, 2025 am 11:13 AML'avenir de l'IA va au-delà de la simple prédiction des mots et de la simulation conversationnelle; Les agents de l'IA émergent, capables d'action indépendante et d'achèvement des tâches. Ce changement est déjà évident dans des outils comme le claude d'Anthropic. Agents de l'IA: recherche un
 Pourquoi l'empathie est plus importante que le contrôle des dirigeants dans un avenir dirigé par l'IAApr 29, 2025 am 11:12 AM
Pourquoi l'empathie est plus importante que le contrôle des dirigeants dans un avenir dirigé par l'IAApr 29, 2025 am 11:12 AMLes progrès technologiques rapides nécessitent une perspective prospective sur l'avenir du travail. Que se passe-t-il lorsque l'IA transcende une simple amélioration de la productivité et commence à façonner nos structures sociétales? Le prochain livre de Topher McDougal, Gaia Wakes:
 IA pour la classification des produits: les machines peuvent-elles maîtriser la loi fiscale?Apr 29, 2025 am 11:11 AM
IA pour la classification des produits: les machines peuvent-elles maîtriser la loi fiscale?Apr 29, 2025 am 11:11 AMLa classification des produits, impliquant souvent des codes complexes comme "HS 8471.30" à partir de systèmes tels que le système harmonisé (HS), est crucial pour le commerce international et les ventes intérieures. Ces codes garantissent une application fiscale correcte, impactant chaque inv
 La demande du centre de données pourrait-elle susciter un rebond de technologie climatique?Apr 29, 2025 am 11:10 AM
La demande du centre de données pourrait-elle susciter un rebond de technologie climatique?Apr 29, 2025 am 11:10 AML'avenir de la consommation d'énergie dans les centres de données et l'investissement en technologie climatique Cet article explore la forte augmentation de la consommation d'énergie dans les centres de données motivés par l'IA et son impact sur le changement climatique, et analyse des solutions innovantes et des recommandations politiques pour relever ce défi. Défis de la demande d'énergie: les centres de données à grande échelle importants et ultra-larges consomment une puissance énorme, comparable à la somme de centaines de milliers de familles nord-américaines ordinaires, et des centres émergents d'IA à l'échelle ultra-large consomment des dizaines de fois plus de puissance que cela. Au cours des huit premiers mois de 2024, Microsoft, Meta, Google et Amazon ont investi environ 125 milliards de dollars en construction et en fonctionnement des centres de données d'IA (JP Morgan, 2024) (tableau 1). La demande d'énergie croissante est à la fois un défi et une opportunité. Selon Canary Media, l'électricité imminente
 L'âge d'or de l'IA et de l'IA et d'HollywoodApr 29, 2025 am 11:09 AM
L'âge d'or de l'IA et de l'IA et d'HollywoodApr 29, 2025 am 11:09 AML'IA générative révolutionne la production cinématographique et télévisée. Le modèle Ray 2 de Luma, ainsi que la Gen-4 de Runway, Sora d'Openai, Veo et d'autres modèles de Google, améliorent la qualité des vidéos générées à une vitesse sans précédent. Ces modèles peuvent facilement créer des effets spéciaux complexes et des scènes réalistes, même de courts clips vidéo et des effets de mouvement perçus par la caméra ont été réalisés. Bien que la manipulation et la cohérence de ces outils doivent encore être améliorées, la vitesse de progrès est incroyable. La vidéo générative devient un support indépendant. Certains modèles sont bons dans la production d'animation, tandis que d'autres sont bons dans les images en direct. Il convient de noter que Adobe's Firefly et Moonvalley's MA
 Chatgpt devient-il lentement le plus grand homme de l'IA?Apr 29, 2025 am 11:08 AM
Chatgpt devient-il lentement le plus grand homme de l'IA?Apr 29, 2025 am 11:08 AML'expérience utilisateur de ChatGPT diminue: est-ce une dégradation du modèle ou des attentes de l'utilisateur? Récemment, un grand nombre d'utilisateurs payés par Chatgpt se sont plaints de leur dégradation des performances, ce qui a attiré une attention généralisée. Les utilisateurs ont signalé des réponses plus lentes aux modèles, des réponses plus courtes, un manque d'aide et encore plus d'hallucinations. Certains utilisateurs ont exprimé leur insatisfaction aux réseaux sociaux, soulignant que Chatgpt est devenu «trop flatteur» et a tendance à vérifier les vues des utilisateurs plutôt que de fournir des commentaires critiques. Cela affecte non seulement l'expérience utilisateur, mais apporte également des pertes réelles aux clients des entreprises, tels que la réduction de la productivité et le gaspillage des ressources informatiques. Preuve de dégradation des performances De nombreux utilisateurs ont signalé une dégradation significative des performances de Chatgpt, en particulier dans des modèles plus anciens tels que le GPT-4 (qui sera bientôt interrompu du service à la fin de ce mois). ce


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

SublimeText3 Linux nouvelle version
Dernière version de SublimeText3 Linux

