
Maison >Périphériques technologiques >IA >Comment exécuter des modèles QWEN2.5 localement en 3 minutes?
Comment exécuter des modèles QWEN2.5 localement en 3 minutes?

- Joseph Gordon-Levittoriginal
- 2025-03-07 09:48:11631parcourir
qwen2.5-max: un raisonnement rentable et de type humain modèle grand langage
Le paysage de l'IA bourdonne de modèles puissants et rentables comme Deepseek, Mistral Small 3 et Qwen2.5 Max. Qwen2.5-max, en particulier, fait des vagues comme un puissant mélange de mélange de réseaux (MOE), même surperformant le V3 profondémente dans certains repères. Son ensemble avancé d'architecture et de formation massive (jusqu'à 18 billions de jetons) établit de nouvelles normes de performance. Cet article explore l'architecture de Qwen2.5-Max, ses avantages concurrentiels et son potentiel de rivaliser avec Deepseek V3. Nous vous guiderons également dans l'exécution des modèles QWEN2.5 localement.
Clé des caractéristiques du modèle QWEN2.5:
- Support multilingue: prend en charge plus de 29 langues.
- Contexte étendu: gère des contextes longs jusqu'à 128K jetons.
- Capacités améliorées: Améliorations significatives du codage, des mathématiques, des suites d'instructions et une compréhension des données structurées.
Table des matières:
- Clé des fonctionnalités du modèle QWEN2.5
- en utilisant qwen2.5 avec olllama
- Qwen2.5: 7b Inférence
- QWEN2.5 CODER: 3B Inférence
- Conclusion
exécuter Qwen2.5 localement avec olllama:
Tout d'abord, installez Olllama: Olllama Télécharger le lien
utilisateurs Linux / Ubuntu: curl -fsSL https://ollama.com/install.sh | sh
Modèles Ollama Qwen2.5 disponibles:
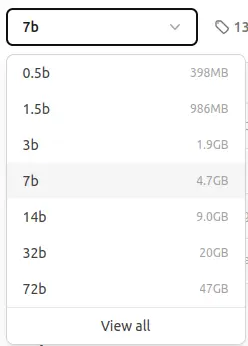
Nous utiliserons le modèle de paramètre 7b (environ 4,7 Go). Des modèles plus petits sont disponibles pour les utilisateurs avec des ressources limitées.
qwen2.5: 7b Inférence:
ollama pull qwen2.5:7b
La commande pull téléchargera le modèle. Vous verrez une sortie similaire à ceci:
<code>pulling manifest pulling 2bada8a74506... 100% ▕████████████████▏ 4.7 GB ... (rest of the output) ... success</code>
Ensuite, exécutez le modèle:
ollama run qwen2.5:7b
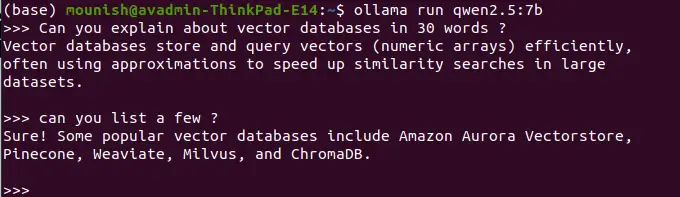
Exemples de requêtes:
Invite: Définissez les bases de données vectorielles en 30 mots.
<code>Vector databases efficiently store and query numerical arrays (vectors), often using approximations for fast similarity searches in large datasets.</code>
Invite: Énumérez quelques exemples.
<code>Popular vector databases include Pinecone, Weaviate, Milvus, ChromaDB, and Amazon Aurora Vectorstore.</code>
(Appuyez sur Ctrl D pour quitter)
Remarque: Les modèles gérés localement manquent de capacités d'accès et de recherche Web en temps réel. Par exemple:
Invite: Quelle est la date d'aujourd'hui?
<code>Today's date is unavailable. My knowledge is not updated in real-time.</code>

QWEN2.5 CODER: 3B Inférence:
Suivez le même processus, substituant qwen2.5-coder:3b par qwen2.5:7b dans les commandes pull et run.
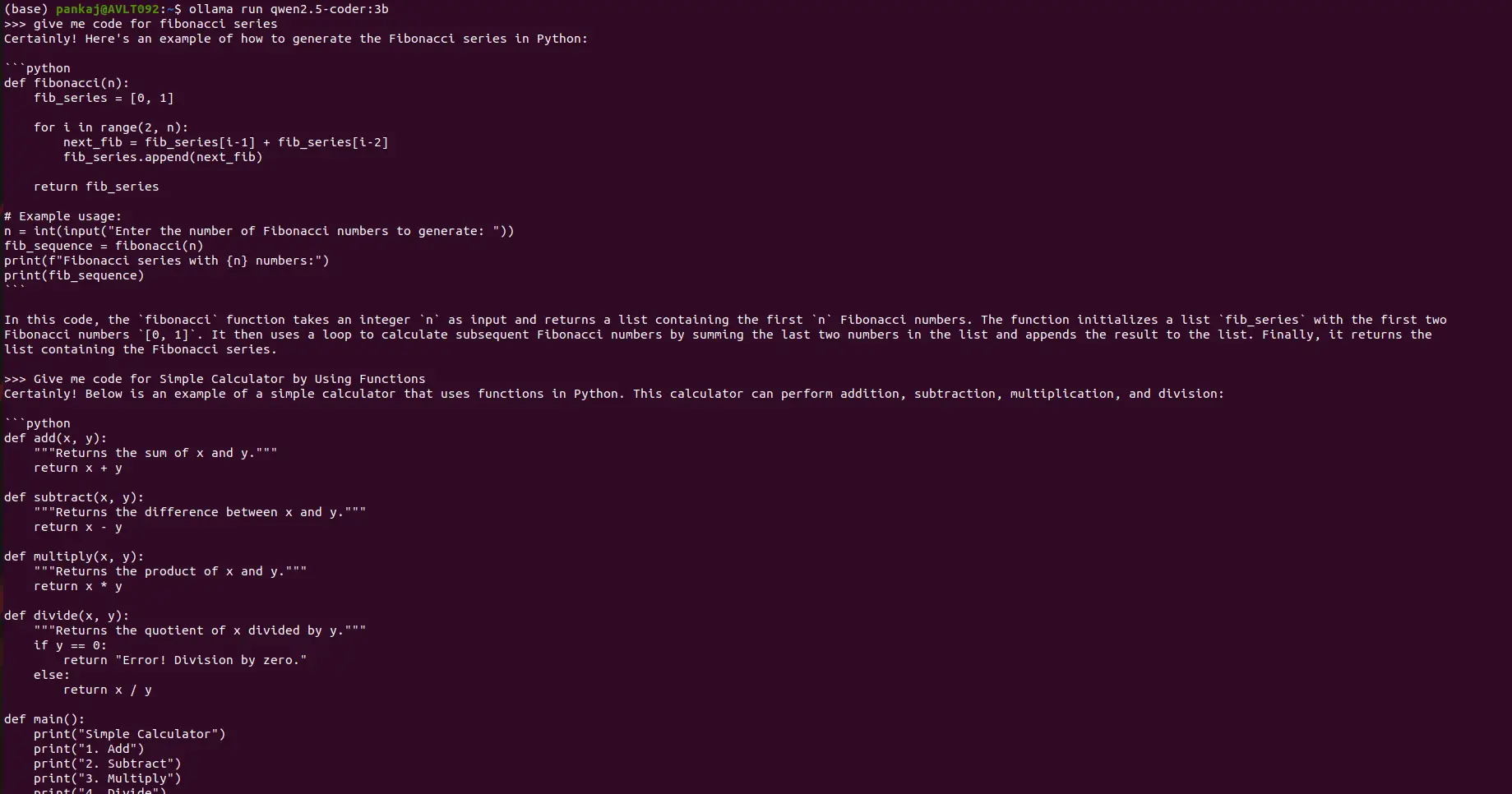
Exemple d'invites de codage:
Invite: Fournir du code Python pour la séquence Fibonacci.
(sortie: le code python pour la séquence de fibonacci sera affiché ici)
Invite: Créez une calculatrice simple à l'aide de fonctions Python.
(sortie: le code python pour une calculatrice simple sera affiché ici)
Conclusion:
Ce guide montre comment exécuter les modèles QWEN2.5 localement à l'aide de Olllama, mettant en évidence les forces de QWEN2.5-MAX: longueur de contexte 128k, support multilingue et capacités améliorées. Alors que l'exécution locale améliore la sécurité, il sacrifie l'accès aux informations en temps réel. Qwen2.5 offre un équilibre convaincant entre l'efficacité, la sécurité et les performances, ce qui en fait une alternative forte à Deepseek V3 pour diverses applications d'IA. De plus amples informations sur l'accès à Qwen2.5-max via Google Colab sont disponibles dans une ressource distincte.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI