



Le cadre omnihuman-1 révolutionnaire de Bytedance révolutionne l'animation humaine! Ce nouveau modèle, détaillé dans un article de recherche récent, exploite une architecture de transformateur de diffusion pour générer des vidéos humaines incroyablement réalistes à partir d'une seule image et d'une seule entrée audio. Oubliez des configurations complexes - Omnihuman simplifie le processus et fournit des résultats supérieurs. Plongeons dans les détails.
Table des matières
- Limites des modèles d'animation existants
- La solution omnihuman-1: une approche multimodale
- Exemple de vidéos omnihuman-1
- Formation et architecture du modèle
- La stratégie de formation des conditions omni-conditions
- Validation expérimentale et performance
- Étude d'ablation: optimisation du processus de formation
- Résultats visuels étendus: démontrant la polyvalence
- Conclusion
Limites des modèles d'animation humaine existants
Les modèles d'animation humaine actuels souffrent souvent de limitations. Ils comptent fréquemment sur de petits ensembles de données spécialisés, ce qui entraîne des animations inflexibles de faible qualité. Beaucoup luttent contre la généralisation dans divers contextes, manquant de réalisme et de fluidité. La dépendance à l'égard des modalités d'entrée unique (par exemple, uniquement du texte ou de l'image) restreint gravement leur capacité à capturer les nuances du mouvement et de l'expression humaines.
La solution omnihuman-1
Omnihuman-1 relève ces défis de front avec une approche multimodale. Il intègre le texte, l'audio et poser des informations en tant que signaux de conditionnement, créant des animations contextuellement riches et réalistes. La conception innovante des conditions omni-conditions préserve l'identité du sujet et les détails de fond de l'image de référence, garantissant la cohérence. Une stratégie de formation unique maximise l'utilisation des données, empêchant le sur-ajustement et augmenter les performances.

Exemple de vidéos omnihuman-1
omnihuman-1 génère des vidéos réalistes à partir d'une image et d'un audio. Il gère divers styles visuels et audio, produisant des vidéos dans n'importe quel rapport d'aspect et proportion corporelle. Les animations résultantes offrent un mouvement, un éclairage et des textures détaillés. (Remarque: les images de référence sont omises par la brièveté mais disponibles sur demande.)
Talking
chant
Diversité
Halfbody Cases avec les mains
Formation et architecture du modèle
La formation d'Omnihuman-1 tire parti d'un modèle de diffusion multi-conditions. Le noyau est un modèle d'algues pré-formé (architecture MMDIT), initialement formé sur des paires générales de texte de texte. Ceci est ensuite adapté à la génération de vidéo humaine en intégrant des signaux de texte, d'audio et de pose. Un autoencoder variationnel causal 3D (3DVAE) projette des vidéos dans un espace latent pour un débroussage efficace. L'architecture réutilise intelligemment le processus de débrassement pour préserver l'identité et l'arrière-plan de l'image de référence.
Diagramme d'architecture du modèle
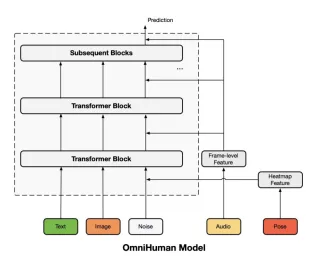
La stratégie de formation des conditions omni-conditions
Ce processus à trois étapes affine progressivement le modèle de diffusion. Il introduit séquentiellement les modalités de conditionnement (texte, audio, pose), en fonction de leur force de corrélation de mouvement (faible à forte). Cela garantit une contribution équilibrée de chaque modalité, optimisant la qualité de l'animation. Le conditionnement audio utilise WAV2VEC pour l'extraction des caractéristiques, et le conditionnement de la pose intègre des thermaps de pose.

Validation expérimentale et performance
L'article présente une validation expérimentale rigoureuse à l'aide d'un ensemble de données massif (18,7 000 heures de données liées à l'homme). Omnihuman-1 surpasse les méthodes existantes sur diverses mesures (IQA, ASE, Sync-C, FID, FVD), démontrant ses performances et sa polyvalence supérieures dans la gestion de différentes configurations d'entrée.
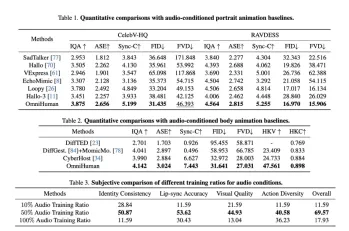
Étude d'ablation: optimisation du processus de formation
L'étude d'ablation explore l'impact de différents rapports de données d'entraînement pour chaque modalité. Il révèle des ratios optimaux pour les données audio et pose, équilibrant le réalisme et la plage dynamique. L'étude met également en évidence l'importance d'un rapport d'image de référence suffisant pour préserver l'identité et la fidélité visuelle. Les visualisations démontrent clairement les effets de variation des rapports audio et des conditions de pose.

Résultats visuels étendus: démontrant la polyvalence
Les résultats visuels étendus présentent la capacité d'Omnihuman-1 à générer des animations diverses et de haute qualité, mettant en évidence sa capacité à gérer divers styles, interactions objets et scénarios axés sur la pose.

Conclusion
omnihuman-1 représente un bond en avant significatif dans la génération de vidéo humaine. Sa capacité à créer des animations réalistes à partir d'une entrée limitée et de ses capacités multimodales en fait une réalisation vraiment remarquable. Ce modèle est sur le point de révolutionner le domaine de l'animation numérique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Pourquoi Sam Altman et d'autres utilisent maintenant les vibrations comme une nouvelle jauge pour les derniers progrès en IAMay 06, 2025 am 11:12 AM
Pourquoi Sam Altman et d'autres utilisent maintenant les vibrations comme une nouvelle jauge pour les derniers progrès en IAMay 06, 2025 am 11:12 AMDiscutons de l'utilisation croissante des «vibrations» comme métrique d'évaluation dans le champ IA. Cette analyse fait partie de ma colonne Forbes en cours sur les progrès de l'IA, explorant des aspects complexes du développement de l'IA (voir le lien ici). Vibrations dans l'évaluation de l'IA Tradot
 À l'intérieur de la construction d'usine Waymo un avenir robotaxiMay 06, 2025 am 11:11 AM
À l'intérieur de la construction d'usine Waymo un avenir robotaxiMay 06, 2025 am 11:11 AML'Arizona Factory de Waymo: Jaguars autonomes producteurs de masse et au-delà Situé près de Phoenix, en Arizona, Waymo exploite une installation ultramoderne produisant sa flotte de VUS électriques Jaguar I-Pace autonomes. Cette usine de 239 000 pieds carrés a ouvert ses portes
 À l'intérieur de la transformation basée sur les données de S&P Global avec l'IA au cœurMay 06, 2025 am 11:10 AM
À l'intérieur de la transformation basée sur les données de S&P Global avec l'IA au cœurMay 06, 2025 am 11:10 AMLe directeur des solutions numériques de S&P Global, Jigar Kocherlakota, discute du parcours de l'IA de l'entreprise, des acquisitions stratégiques et de la transformation numérique axée sur le futur. Un rôle de leadership transformateur et une équipe prête pour l'avenir Le rôle de Kocherlakota
 La montée des super-applications: 4 étapes pour s'épanouir dans un écosystème numériqueMay 06, 2025 am 11:09 AM
La montée des super-applications: 4 étapes pour s'épanouir dans un écosystème numériqueMay 06, 2025 am 11:09 AMDes applications aux écosystèmes: naviguer dans le paysage numérique La révolution numérique s'étend bien au-delà des médias sociaux et de l'IA. Nous assistons à la montée en puissance de «tout les applications» - des écosystèmes numériques complets intégrant tous les aspects de la vie. Sam A
 MasterCard et Visa Unleash Ai Agents pour vous acheter pour vousMay 06, 2025 am 11:08 AM
MasterCard et Visa Unleash Ai Agents pour vous acheter pour vousMay 06, 2025 am 11:08 AMPayage de l'agent de MasterCard: les paiements alimentés par AI révolutionnent le commerce Alors que les capacités de transaction alimentées par Visa ont fait la une des journaux, MasterCard a dévoilé le salaire d'agent, un système de paiement AI plus avancé construit sur la tokenisation, la confiance et l'agent
 Soutenir The Bold: Future Ventures's Transformator Innovation PlaybookMay 06, 2025 am 11:07 AM
Soutenir The Bold: Future Ventures's Transformator Innovation PlaybookMay 06, 2025 am 11:07 AMFuture Ventures Fund IV: un pari de 200 millions de dollars sur les nouvelles technologies Future Ventures a récemment clôturé son fonds sursubscrit IV, totalisant 200 millions de dollars. Ce nouveau fonds, géré par Steve Jurvetson, Maryanna Saenko et Nico Enriquez, représente un INV significatif
 Au fur et à mesure que l'IA utilise des monnaieMay 05, 2025 am 11:09 AM
Au fur et à mesure que l'IA utilise des monnaieMay 05, 2025 am 11:09 AMAvec l'explosion des applications d'IA, les entreprises passent de l'optimisation traditionnelle du moteur de recherche (SEO) à l'optimisation générative du moteur (GEO). Google mène le changement. Sa fonctionnalité "AI APORTOW" a servi plus d'un milliard d'utilisateurs, fournissant des réponses complètes avant que les utilisateurs ne cliquent sur le lien. [^ 2] D'autres participants augmentent également rapidement. Chatgpt, Microsoft Copilot et Perplexity créent une nouvelle catégorie de «moteur de réponse» qui contourne complètement les résultats de recherche traditionnels. Si votre entreprise n'apparaît pas dans ces réponses générées par l'AI, les clients potentiels peuvent ne jamais vous trouver, même si vous vous classez haut dans les résultats de recherche traditionnels. Du référencement à Geo - qu'est-ce que cela signifie exactement? Pendant des décennies
 De grands paris sur lesquels de ces voies pousseront l'IA d'aujourd'hui pour devenir précieux AGIMay 05, 2025 am 11:08 AM
De grands paris sur lesquels de ces voies pousseront l'IA d'aujourd'hui pour devenir précieux AGIMay 05, 2025 am 11:08 AMExplorons les voies potentielles de l'intelligence générale artificielle (AGI). Cette analyse fait partie de ma colonne Forbes en cours sur les progrès de l'IA, plongeant dans les complexités de la réalisation de l'AGI et de la superintelligence artificielle (ASI). (Voir l'art connexe


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Version Mac de WebStorm
Outils de développement JavaScript utiles

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Navigateur d'examen sécurisé
Safe Exam Browser est un environnement de navigation sécurisé permettant de passer des examens en ligne en toute sécurité. Ce logiciel transforme n'importe quel ordinateur en poste de travail sécurisé. Il contrôle l'accès à n'importe quel utilitaire et empêche les étudiants d'utiliser des ressources non autorisées.

Version crackée d'EditPlus en chinois
Petite taille, coloration syntaxique, ne prend pas en charge la fonction d'invite de code

