
 Périphériques technologiquesIABooster la précision LLM avec une génération augmentée (RAG) de récupération et rediffusion
Périphériques technologiquesIABooster la précision LLM avec une génération augmentée (RAG) de récupération et rediffusionBooster la précision LLM avec une génération augmentée (RAG) de récupération et rediffusion

Déverrouiller la puissance des LLM améliorés: génération de récupération (RAG) et redirige
Les modèles de grandes langues (LLM) ont révolutionné l'IA, mais des limitations telles que les hallucinations et les informations obsolètes entravent leur précision. Génération de la récupération (RAG) et remaniement offrent des solutions en intégrant le LLMS à la récupération dynamique des informations. Explorons cette combinaison puissante.
Pourquoi le chiffon améliore les LLMS?
LLMS Excel à diverses tâches NLP, comme illustré ci-dessous:
 Une taxonomie des tâches de langage résolubles par LLMS | Iván Palomares
Une taxonomie des tâches de langage résolubles par LLMS | Iván Palomares
Cependant, les LLM luttent parfois avec des réponses contextuellement appropriées, générant des informations incorrectes ou absurdes (hallucinations). De plus, leurs connaissances sont limitées par le point de «coupure des connaissances» de leurs données de formation. Par exemple, un LLM formé avant janvier 2024 ne connaîtrait pas une nouvelle souche de grippe émergeant ce mois-ci. Le recyclage LLMS est fréquemment coûteux en calcul. Le chiffon fournit une alternative plus efficace.
Rag exploite une base de connaissances externe pour compléter les connaissances internes du LLM. Cela améliore la qualité de la réponse, la pertinence et la précision sans recyclage constant. Le workflow Rag est:
- requête: La question de l'utilisateur est reçue.
- Récupérer: Le système accède à une base de connaissances, en identifiant les documents pertinents.
- Générer: Le LLM combine la requête et les documents récupérés pour formuler une réponse.
RERANKING: Optimisation de la récupération
RERANKING affine les documents récupérés pour hiérarchiser les informations les plus pertinentes pour la requête et le contexte spécifiques. Le processus implique:
- Retriel initial: Un système (par exemple, en utilisant des modèles d'espace TF-IDF ou vectoriels) récupère un ensemble de documents.
- RERANKING: Un mécanisme plus sophistiqué réorganise ces documents sur la base de critères supplémentaires (préférences des utilisateurs, contexte, algorithmes avancés).
 Processus de rediffusion | Iván Palomares
Processus de rediffusion | Iván Palomares
Contrairement aux systèmes de recommandation, RERANKING se concentre sur les réponses de requête en temps réel, et non les suggestions proactives.
La valeur de RERANKING dans les LLMS améliorés par les ragus
Reranking améliore considérablement les LLMS alimentées par RAG. Après la récupération initiale des documents, RERANKING garantit que le LLM utilise les informations les plus pertinentes et les plus de haute qualité, augmentant la précision et la pertinence de la réponse, en particulier dans les domaines spécialisés.
Types de remananker
Diverses approches de rediffusion existent, y compris:
- Rerrankers multi-vecteurs: Utilisez plusieurs représentations vectorielles pour une meilleure correspondance de similitudes.
- Apprendre à classer (LTR): utilise l'apprentissage automatique pour apprendre des classements optimaux.
- RERANKERS basés sur Bert: Tirez parti des capacités de compréhension du langage de Bert.
- Rerrankers d'apprentissage du renforcement: Optimiser les classements basés sur les données d'interaction utilisateur.
- Rerrankers hybrides: combiner plusieurs stratégies.
Construire un pipeline de chiffons avec reranking (exemple de Langchain)
Cette section montre un pipeline de chiffon simplifié avec rediffusion en utilisant la bibliothèque Langchain. (Code complet disponible dans un ordinateur portable Google Colab - Lien omis pour la concision). L'exemple traite des fichiers texte, crée des intégres, utilise le LLM d'OpenAI et intègre une fonction de rediffusion personnalisée basée sur la similitude des cosinus. Le code présente à la fois une version sans rediffusion et une version raffinée avec RERANKING activé.
Exploration supplémentaire
Rag est un progrès crucial dans la technologie LLM. Cet article a couvert le rôle de RERANKING dans l'amélioration des pipelines de chiffon. Pour des plongées plus profondes, explorez les ressources sur le chiffon, ses améliorations de performances et les capacités de Langchain pour le développement des applications LLM. (Liens omis pour la concision).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Tout sur la dernière famille GPT 4.1 d'Open AI - Analytics VidhyaApr 26, 2025 am 10:19 AM
Tout sur la dernière famille GPT 4.1 d'Open AI - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI dévoile la puissante série GPT-4.1: une famille de trois modèles de langage avancé conçus pour des applications réelles. Ce saut significatif en avant offre des temps de réponse plus rapides, une compréhension améliorée et des coûts considérablement réduits par rapport à T
 Que sont les repères LLM?Apr 26, 2025 am 10:13 AM
Que sont les repères LLM?Apr 26, 2025 am 10:13 AMLes modèles de grandes langues (LLM) sont devenus intégrés aux applications d'IA modernes, mais l'évaluation de leurs capacités reste un défi. Les références traditionnelles sont depuis longtemps la norme pour mesurer les performances LLM, mais avec la PR
 7 tâches Gemini 2.5 Pro fait mieux que tout autre chatbot!Apr 26, 2025 am 10:00 AM
7 tâches Gemini 2.5 Pro fait mieux que tout autre chatbot!Apr 26, 2025 am 10:00 AMLes chatbots AI deviennent de plus en plus intelligents et de plus en plus sophistiqués de jour en jour. Le dernier modèle expérimental de Google Deepmind, Gemini 2.5 Pro, représente un bond en avant significatif dans les capacités de chatbot IA. Avec un contex amélioré
 6 invites O3 Vous devez essayer aujourd'hui - Analytics VidhyaApr 26, 2025 am 09:56 AM
6 invites O3 Vous devez essayer aujourd'hui - Analytics VidhyaApr 26, 2025 am 09:56 AMO3 d'Openai: un bond en avant dans le raisonnement et les capacités multimodales Le modèle O3 d'OpenAI représente un progrès important dans les capacités de raisonnement d'IA. Conçu pour la résolution complexe de problèmes, les tâches analytiques et l'utilisation d'outils autonomes, O3 dépasse
 J'ai essayé le code Canva et ici comment ça s'est passé.Apr 26, 2025 am 09:53 AM
J'ai essayé le code Canva et ici comment ça s'est passé.Apr 26, 2025 am 09:53 AMCanva Create 2025: Revolutioning Design avec Canva Code et AI L'événement Create 2025 de CanVA a dévoilé des progrès importants, élargissant sa plate-forme en outils alimentés par l'IA, des solutions d'entreprise et, notamment, des outils de développeur. Les mises à jour clés incluses
 AI Chatbot pour les tâches: comment les agents de l'IA remplacent tranquillement les applicationsApr 26, 2025 am 09:50 AM
AI Chatbot pour les tâches: comment les agents de l'IA remplacent tranquillement les applicationsApr 26, 2025 am 09:50 AML'ère de l'application pour les tâches simples se termine. Imaginez réserver des vacances avec une seule conversation ou faire négocier automatiquement vos factures. C'est la puissance des agents de l'IA - vos nouveaux assistants numériques qui anticipent vos besoins, pas le jus
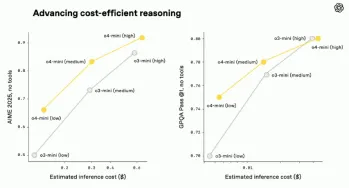 O3 et O4-Mini: modèles de raisonnement les plus avancés d'OpenaiApr 26, 2025 am 09:46 AM
O3 et O4-Mini: modèles de raisonnement les plus avancés d'OpenaiApr 26, 2025 am 09:46 AMModèles de raisonnement Open révolutionnaire O3 et O4-Mini: un saut géant vers AGI Hot sur les talons du lancement de la famille GPT 4.1, Openai a dévoilé ses dernières avancées dans l'IA: les modèles de raisonnement O3 et O4-Mini. Ce ne sont pas seulement des modèles d'IA; le
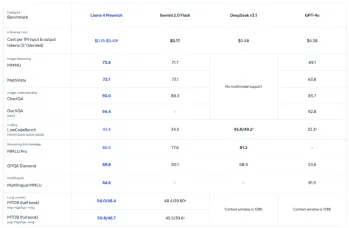 Construire un agent d'IA avec Llama 4 et AutogenApr 26, 2025 am 09:44 AM
Construire un agent d'IA avec Llama 4 et AutogenApr 26, 2025 am 09:44 AMExploiter le pouvoir de Llama 4 et Autogen pour construire des agents d'IA intelligents La famille de modèles Llama 4 de Meta transforme le paysage de l'IA, offrant des capacités multimodales indigènes pour révolutionner le développement de systèmes intelligents. Cet article d'exploration


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

VSCode Windows 64 bits Télécharger
Un éditeur IDE gratuit et puissant lancé par Microsoft

MantisBT
Mantis est un outil Web de suivi des défauts facile à déployer, conçu pour faciliter le suivi des défauts des produits. Cela nécessite PHP, MySQL et un serveur Web. Découvrez nos services de démonstration et d'hébergement.

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

