
Maison >Périphériques technologiques >IA >O3-Mini peut-il remplacer Deepseek-R1 pour un raisonnement logique?
O3-Mini peut-il remplacer Deepseek-R1 pour un raisonnement logique?

- Jennifer Anistonoriginal
- 2025-03-05 10:42:16228parcourir
Les modèles de raisonnement alimentés en AI prennent d'assaut le monde en 2025! Avec le lancement de Deepseek-R1 et O3-MinI, nous avons vu des niveaux sans précédent de capacités de raisonnement logique dans les chatbots IA. Dans cet article, nous accéderons à ces modèles via leurs API et évaluerons leurs compétences de raisonnement logique pour savoir si O3-Mini peut remplacer Deepseek-R1. Nous comparerons leurs performances sur des références standard ainsi que sur des applications du monde réel comme la résolution de puzzles logiques et même la construction d'un jeu Tetris! Alors bouclez-vous et rejoignez le trajet.
Table des matières
- Deepseek-R1 vs O3-MinI: Reason logique Benchmarks
- Deepseek-R1 vs O3-MinI: Prix API Comparaison
- Comment accéder à Deepseek-R1 et O3-Mini via Api
- Comparaison du raisonnement
- Tâche 1: Construire un jeu Tetris
- Tâche 2: Analyser les inégalités relationnelles
- Tâche 3: Raisonnement logique en mathématiques
- Résumé de la comparaison logique
- Deepseek-R1 et O3-Mini offrent des approches uniques à la pensée et à la déduction structurées, ce qui les rend aptes à divers types de tâches complexes de résolution de problèmes. Avant de parler de leurs performances de référence, jetons d'abord un aperçu de l'architecture de ces modèles.
- O3-Mini est le modèle de raisonnement le plus avancé d'Openai. Il utilise une architecture de transformateur dense, traitant chaque jeton avec tous les paramètres du modèle pour des performances solides mais une consommation élevée de ressources. En revanche, le modèle le plus logique de Deepseek, R1, utilise un framework de mélange d'Experts (MOE), activant uniquement un sous-ensemble de paramètres par entrée pour une plus grande efficacité. Cela rend Deepseek-R1 plus évolutif et optimisé par le calcul tout en maintenant des performances solides.
En savoir plus: O3-MinI d'Openai est-il meilleur que Deepseek-R1?
Maintenant, ce que nous devons voir, c'est comment ces modèles fonctionnent dans les tâches de raisonnement logique. Tout d'abord, jetons un coup d'œil à leurs performances dans les tests de référence LiveBench.
Sources: LiveBench.ai
Les résultats de référence montrent que O3-Mini d'Openai surpasse Deepseek-R1 dans presque tous les aspects, à l'exception des mathématiques. Avec un score moyen mondial de 73,94 par rapport à 71,38 de Deepseek, l'O3-MinI présente des performances globales légèrement plus fortes. Il excelle en particulier dans le raisonnement, atteignant 89,58 contre 83.17 de Deepseek, reflétant des capacités d'analyse et de résolution de problèmes supérieures.
 LIRE AUSSI: Google Gemini 2.0 Pro vs Deepseek-R1: Qui est mieux le codage?
LIRE AUSSI: Google Gemini 2.0 Pro vs Deepseek-R1: Qui est mieux le codage?
Deepseek-R1 vs O3-MinI: Comparaison des prix de l'API
Puisque nous testons ces modèles via leurs API, voyons combien coûtent ces modèles.
| Model | Context length | Input Price | Cached Input Price | Output Price |
| o3-mini | 200k | .10/M tokens | .55/M tokens | .40/M tokens |
| deepseek-chat | 64k | .27/M tokens | .07/M tokens | .10/M tokens |
| deepseek-reasoner | 64k | .55/M tokens | .14/M tokens | .19/M tokens |
Comme le montre le tableau, O3-Mini d'Openai est presque deux fois plus cher que Deepseek R1 en termes de coûts d'API. Il facture 1,10 $ par million de jetons pour les contributions et 4,40 $ pour la production, tandis que Deepseek R1 offre un taux plus rentable de 0,55 $ par million de jetons pour les contributions et 2,19 $ pour la production, ce qui en fait une option plus favorable à un budget pour les applications à grande échelle.
Sources: Deepseek-R1 | o3-min
Comment accéder à Deepseek-R1 et O3-MinI via API
Avant d'entrer dans la comparaison pratique des performances, apprenons à accéder à Deepseek-R1 et O3-Mini à l'aide d'API.
Tout ce que vous avez à faire pour cela, c'est importer les bibliothèques et les clés API nécessaires:
from openai import OpenAI from IPython.display import display, Markdown import time
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()
with open("path_of_api_key") as file:
deepseek_api = file.read().strip()
Deepseek-R1 vs O3-MinI: Comparaison du raisonnement logique
Maintenant que nous avons obtenu l'accès à l'API, comparons Deepseek-R1 et O3-Mini en fonction de leurs capacités de raisonnement logiques. Pour cela, nous donnerons la même invite aux deux modèles et évaluerons leurs réponses en fonction de ces mesures:
- Temps pris par le modèle pour générer la réponse,
- qualité de la réponse générée, et
- coût engagé pour générer la réponse.
Nous marquerons ensuite les modèles 0 ou 1 pour chaque tâche, en fonction de leurs performances. Essayons donc les tâches et voyons qui émerge comme le gagnant de la bataille de raisonnement Deepseek-R1 vs O3-Mini!
Tâche 1: Construire un jeu Tetris
Cette tâche nécessite que le modèle implémente un jeu Tetris entièrement fonctionnel à l'aide de Python, gérant efficacement la logique de jeu, le mouvement des pièces, la détection de collision et le rendu sans compter sur des moteurs de jeu externes.
Invite: "Écrivez un code Python pour ce problème: générez un code Python pour le jeu Tetris"
Entrée de l'API Deepseek-R1
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task1_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = messages=[
{
"role": "system",
"content": """You are a professional Programmer with a large experience ."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game.
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task1_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task2_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are an expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task2_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task3_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task3_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: .005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: .015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices[0].message)
print("----------------=Total Time Taken for task 3:----------------- ", task3_end_time - task3_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices[0].message.content)).14 per 1M tokens
INPUT_COST_CACHE_MISS = 0.55 / 1_000_000 # .55 per 1M tokens
OUTPUT_COST = 2.19 / 1_000_000 # .19 per 1M tokens
# Start timing
task3_start_time = time.time()
# Initialize OpenAI client for DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
messages = [
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
]
# Get token count using tiktoken (adjust model name if necessary)
encoding = tiktoken.get_encoding("cl100k_base") # Use a compatible tokenizer
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
# Call DeepSeek API
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=False
)
# Get output token count
output_tokens = len(encoding.encode(response.choices[0].message.content))
task3_end_time = time.time()
total_time_taken = task3_end_time - task3_start_time
# Assume cache miss for worst-case pricing (adjust if cache info is available)
input_cost = (input_tokens / 1_000_000) * INPUT_COST_CACHE_MISS
output_cost = (output_tokens / 1_000_000) * OUTPUT_COST
total_cost = input_cost + output_cost
# Print results
print("Response:", response.choices[0].message.content)
print("------------------ Total Time Taken for Task 3: ------------------", total_time_taken)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(response.choices[0].message.content)).005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: .015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices[0].message)
print("----------------=Total Time Taken for task 2:----------------- ", task2_end_time - task2_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices[0].message.content)).14 per 1M tokens
INPUT_COST_CACHE_MISS = 0.55 / 1_000_000 # .55 per 1M tokens
OUTPUT_COST = 2.19 / 1_000_000 # .19 per 1M tokens
# Start timing
task2_start_time = time.time()
# Initialize OpenAI client for DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
messages = [
{"role": "system", "content": "You are an expert in solving Reasoning Problems. Please solve the given problem."},
{"role": "user", "content": """ In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""}
]
# Get token count using tiktoken (adjust model name if necessary)
encoding = tiktoken.get_encoding("cl100k_base") # Use a compatible tokenizer
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
# Call DeepSeek API
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=False
)
# Get output token count
output_tokens = len(encoding.encode(response.choices[0].message.content))
task2_end_time = time.time()
total_time_taken = task2_end_time - task2_start_time
# Assume cache miss for worst-case pricing (adjust if cache info is available)
input_cost = (input_tokens / 1_000_000) * INPUT_COST_CACHE_MISS
output_cost = (output_tokens / 1_000_000) * OUTPUT_COST
total_cost = input_cost + output_cost
# Print results
print("Response:", response.choices[0].message.content)
print("------------------ Total Time Taken for Task 2: ------------------", total_time_taken)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(response.choices[0].message.content)).005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: .015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
print(completion.choices[0].message)
print("----------------=Total Time Taken for task 1:----------------- ", task1_end_time - task1_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices[0].message.content)).14 per 1M tokens
INPUT_COST_CACHE_MISS = 0.55 / 1_000_000 # .55 per 1M tokens
OUTPUT_COST = 2.19 / 1_000_000 # .19 per 1M tokens
# Start timing
task1_start_time = time.time()
# Initialize OpenAI client for DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
messages = [
{
"role": "system",
"content": """You are a professional Programmer with a large experience."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game."""
}
]
# Get token count using tiktoken (adjust model name if necessary)
encoding = tiktoken.get_encoding("cl100k_base") # Use a compatible tokenizer
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
# Call DeepSeek API
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=False
)
# Get output token count
output_tokens = len(encoding.encode(response.choices[0].message.content))
task1_end_time = time.time()
total_time_taken = task1_end_time - task1_start_time
# Assume cache miss for worst-case pricing (adjust if cache info is available)
input_cost = (input_tokens / 1_000_000) * INPUT_COST_CACHE_MISS
output_cost = (output_tokens / 1_000_000) * OUTPUT_COST
total_cost = input_cost + output_cost
# Print results
print("Response:", response.choices[0].message.content)
print("------------------ Total Time Taken for Task 1: ------------------", total_time_taken)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(response.choices[0].message.content))
Réponse par Deepseek-R1

Vous pouvez trouver la réponse complète de Deepseek-R1 ici.
Coût de jeton de sortie:
Tokens d'entrée: 28 | Tokens de sortie: 3323 | Coût estimé: 0,0073 $
Sortie du code
Entrée à l'API O3-MinI
Réponse par O3-MinI

Vous pouvez trouver la réponse complète d'O3-Mini ici.
Coût de jeton de sortie:
Tokens d'entrée: 28 | Tokens de sortie: 3235 | Coût estimé: 0,014265 $
Sortie du code
Analyse comparative
Dans cette tâche, les modèles étaient nécessaires pour générer du code TETRIS fonctionnel qui permet un gameplay réel. Deepseek-R1 a produit avec succès une implémentation entièrement fonctionnelle, comme démontré dans la vidéo de sortie du code. En revanche, alors que le code d'O3-Mini semblait bien structuré, il a rencontré des erreurs pendant l'exécution. En conséquence, Deepseek-R1 surpasse O3-MinI dans ce scénario, offrant une solution plus fiable et jouable.
Score: Deepseek-R1: 1 | O3-min: 0
Tâche 2: Analyse des inégalités relationnelles
Cette tâche nécessite que le modèle analyse efficacement les inégalités relationnelles plutôt que de s'appuyer sur des méthodes de tri de base.
Invite: " Dans la question suivante en supposant que les déclarations données sont vraies, trouvez lequel de la conclusion parmi les conclusions données est / est certainement vrai et donnez ensuite vos réponses en conséquence.
Instructions:
h & gt; F ≤ o ≤ l; F ≥ V & lt; D
Conclusions: I. l ≥ V II. O & gt; D
Les options sont:
a. Seul je suis vrai
b. Seul II est vrai
c. I et II sont vrais
d. I ou II est vrai
e. Ni I ni II n'est vrai. »
Entrée de l'API Deepseek-R1
from openai import OpenAI from IPython.display import display, Markdown import time
Coût de jeton de sortie:
Tokens d'entrée: 136 | Tokens de sortie: 352 | Coût estimé: 0,000004 $
Réponse par Deepseek-R1
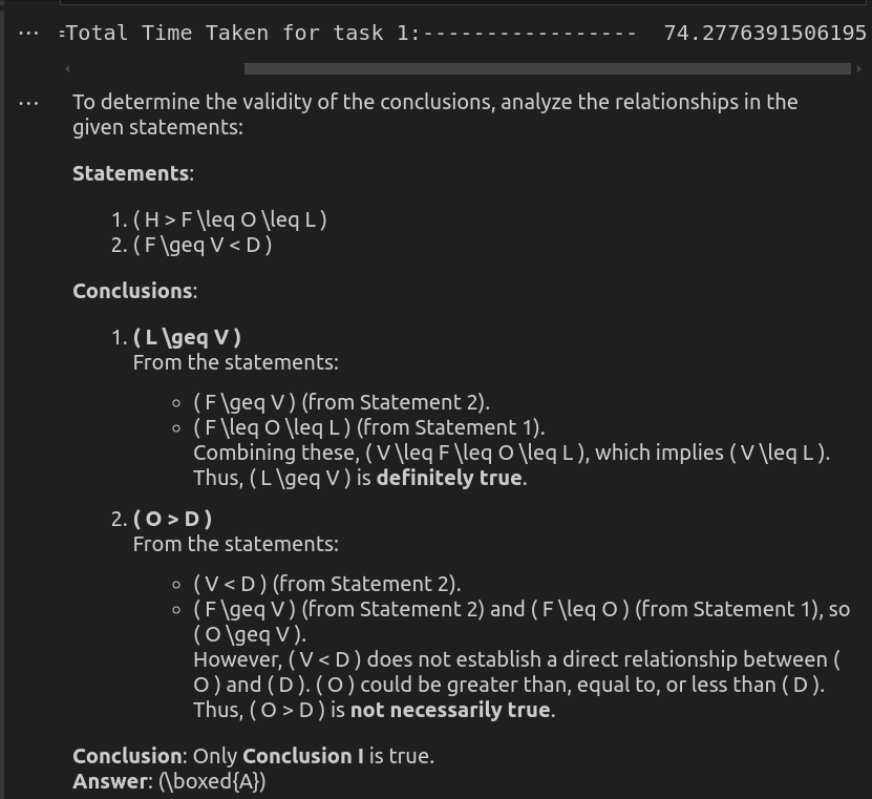
Entrée à l'API O3-MinI
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()
Coût de jeton de sortie:
Tokens d'entrée: 135 | Tokens de sortie: 423 | Coût estimé: 0,002010 $
Réponse par O3-MinI
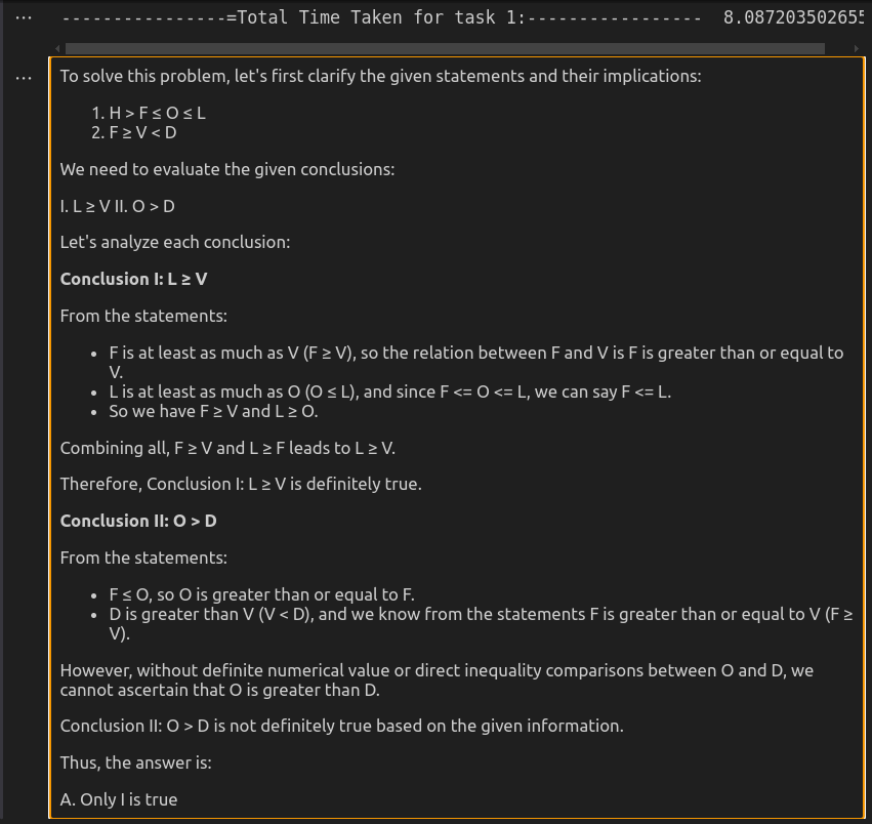
Analyse comparative
O3-MINI offre la solution la plus efficace, fournissant une réponse concise mais précise en beaucoup moins de temps. Il maintient la clarté tout en garantissant la solidité logique, ce qui le rend idéal pour des tâches de raisonnement rapide. Deepseek-R1, bien que tout aussi correct, est beaucoup plus lent et plus verbeux. Sa rupture détaillée des relations logiques améliore l'explication mais peut se sentir excessive pour des évaluations simples. Bien que les deux modèles arrivent à la même conclusion, la vitesse et l'approche directe d'O3-Mini en font le meilleur choix pour une utilisation pratique.
Score: Deepseek-R1: 0 | O3-min: 1
Tâche 3: raisonnement logique en mathématiques
Cette tâche remet en question le modèle pour reconnaître les modèles numériques, qui peuvent impliquer des opérations arithmétiques, une multiplication ou une combinaison de règles mathématiques. Au lieu d'une recherche par force brute, le modèle doit adopter une approche structurée pour déduire efficacement la logique cachée.
Invite: " Étudiez soigneusement la matrice donnée et sélectionnez le numéro parmi les options données qui peuvent remplacer le point d'interrogation (?).
____________
| 7 | 13 | 174 |
| 9 | 25 | 104 |
| 11 | 30 | ? |
| _____ | ____ | ___ |
Les options sont:
a 335
b 129
c 431
d 100
Veuillez mentionner votre approche que vous avez adoptée à chaque étape. "
Entrée de l'API Deepseek-R1
from openai import OpenAI from IPython.display import display, Markdown import time
Coût de jeton de sortie:
Tokens d'entrée: 134 | Tokens de sortie: 274 | Coût estimé: 0,000003 $
Réponse par Deepseek-R1

Entrée à l'API O3-MinI
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()
Coût de jeton de sortie:
Tokens d'entrée: 134 | Tokens de sortie: 736 | Coût estimé: 0,003386 $
Sortie par O3-MinI




Analyse comparative
Ici, le motif suivi dans chaque ligne est:
(1er numéro) ^ 3− (2ème numéro) ^ 2 = 3ème numéro
Application de ce modèle:
- Row 1: 7 ^ 3 - 13 ^ 2 = 343 - 169 = 174
- Row 2: 9 ^ 3 - 25 ^ 2 = 729 - 625 = 104
- Row 3: 11 ^ 3 - 30 ^ 2 = 1331 - 900 = 431
Par conséquent, la bonne réponse est 431.
Deepseek-R1 identifie et applique correctement ce modèle, conduisant à la bonne réponse. Son approche structurée garantit la précision, bien qu'il prenne beaucoup plus de temps pour calculer le résultat. O3-MinI, en revanche, ne parvient pas à établir un modèle cohérent. Il essaie plusieurs opérations, telles que la multiplication, l'addition et l'exponentiation, mais n'arrive pas à une réponse définitive. Il en résulte une réponse peu claire et incorrecte. Dans l'ensemble, Deepseek-R1 surpasse O3-MinI dans le raisonnement logique et la précision, tandis que O3-Mini lutte en raison de son approche incohérente et inefficace.
Score: Deepseek-R1: 1 | O3-min: 0
Score final: Deepseek-R1: 2 | O3-min: 1
Résumé de la comparaison du raisonnement logique
| Task No. | Task Type | Model | Performance | Time Taken (seconds) | Cost |
| 1 | Code Generation | DeepSeek-R1 | ✅ Working Code | 606.45 | .0073 |
| o3-mini | ❌ Non-working Code | 99.73 | .014265 | ||
| 2 | Alphabetical Reasoning | DeepSeek-R1 | ✅ Correct | 74.28 | .000004 |
| o3-mini | ✅ Correct | 8.08 | .002010 | ||
| 3 | Mathematical Reasoning | DeepSeek-R1 | ✅ Correct | 450.53 | .000003 |
| o3-mini | ❌ Wrong Answer | 12.37 | .003386 |
Conclusion
Comme nous l'avons vu dans cette comparaison, Deepseek-R1 et O3-MINI montrent des forces uniques qui répondent à des besoins différents. Deepseek-R1 excelle dans les tâches axées sur la précision, en particulier dans le raisonnement mathématique et la génération de code complexe, ce qui en fait un candidat solide pour les applications nécessitant une profondeur logique et une exactitude. Cependant, un inconvénient significatif est ses temps de réponse plus lents, en partie en raison de problèmes de maintenance des serveurs en cours qui ont affecté son accessibilité. D'un autre côté, O3-MinI offre des temps de réponse beaucoup plus rapides, mais sa tendance à produire des résultats incorrects limite sa fiabilité pour les tâches de raisonnement à enjeux élevés.
Cette analyse souligne les compromis entre la vitesse et la précision dans les modèles de langue. Alors que O3-MinI peut être utile pour les applications rapides et à faible risque, Deepseek-R1 se démarque comme le choix supérieur pour les tâches à forte intensité de raisonnement, à condition que ses problèmes de latence soient résolus. Au fur et à mesure que les modèles d'IA continuent d'évoluer, trouver un équilibre entre l'efficacité des performances et l'exactitude sera la clé pour optimiser les flux de travail dirigés par l'IA dans divers domaines.
Lisez également: OpenIa O3-MinI a-t-il battu Claude Sonnet 3.5 en codage?
Les questions fréquemment posées
Q1. Quelles sont les principales différences entre Deepseek-R1 et O3-MinI?a. Deepseek-R1 excelle dans le raisonnement mathématique et la génération de code complexe, ce qui le rend idéal pour les applications qui nécessitent une profondeur et une précision logiques. O3-MinI, en revanche, est significativement plus rapide mais sacrifie souvent la précision, conduisant à des sorties incorrectes occasionnelles.
Q2. Deepseek-R1 est-il meilleur que O3-Mini pour les tâches de codage?a. Deepseek-R1 est le meilleur choix de codage et de tâches à forte intensité de raisonnement en raison de sa précision supérieure et de sa capacité à gérer la logique complexe. Alors que O3-Mini fournit des réponses plus rapides, elle peut générer des erreurs, ce qui la rend moins fiable pour les tâches de programmation à enjeux élevés.
Q3. O3-MinI convient-il aux applications du monde réel?a. O3-MinI est le mieux adapté aux applications à faible risque et dépendantes de la vitesse, telles que les chatbots, la génération de texte décontractée et les expériences interactives de l'IA. Cependant, pour les tâches nécessitant une précision élevée, Deepseek-R1 est l'option préférée.
Q4. Quel modèle est le meilleur pour le raisonnement et la résolution de problèmes - Deepseek-R1 ou O3-min?a. Deepseek-R1 a un raisonnement logique supérieur et des capacités de résolution de problèmes, ce qui en fait un choix fort pour les calculs mathématiques, l'assistance de programmation et les requêtes scientifiques. O3-Mini fournit des réponses rapides mais parfois incohérentes dans des scénarios de résolution de problèmes complexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI