
Maison >Périphériques technologiques >IA >Tutoriel Deepchecks: Test d'apprentissage automatique automatisant
Tutoriel Deepchecks: Test d'apprentissage automatique automatisant

- Lisa Kudroworiginal
- 2025-03-05 09:03:10556parcourir
Ce didacticiel explore les profondeurs des tests de validation des données et les tests de modèle d'apprentissage automatique, et exploite les actions GitHub pour les tests automatisés et la création d'artefacts. Nous couvrirons les principes de test d'apprentissage automatique, les fonctionnalités de profondeur et un flux de travail automatisé complet.

Image par auteur
Comprendre les tests d'apprentissage automatique
L'apprentissage automatique efficace nécessite des tests rigoureux au-delà des métriques de précision simple. Nous devons évaluer l'équité, la robustesse et les considérations éthiques, notamment la détection des biais, les faux positifs / négatifs, les mesures de performance, le débit et l'alignement avec l'éthique de l'IA. Cela implique des techniques telles que la validation des données, la validation croisée, le calcul des scores F1, l'analyse de la matrice de confusion et la détection de dérive (données et prédiction). Le fractionnement des données (train / test / validation) est crucial pour une évaluation fiable du modèle. L'automatisation de ce processus est la clé pour construire des systèmes d'IA fiables.
Pour les débutants, les principes fondamentaux de l'apprentissage automatique avec Python Skill Track offrent une base solide.
Deepchecks, une bibliothèque Python open source, simplifie des tests d'apprentissage automatique complets. Il propose des vérifications intégrées pour les performances du modèle, l'intégrité des données et la distribution, prenant en charge la validation continue pour un déploiement de modèle fiable.
Début avec Deepchecks
Installez les profondeurs en utilisant PIP:
pip install deepchecks --upgrade -q
Chargement et préparation des données (ensemble de données de prêt)
Nous utiliserons l'ensemble de données de données de prêt à partir de Datacamp.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()
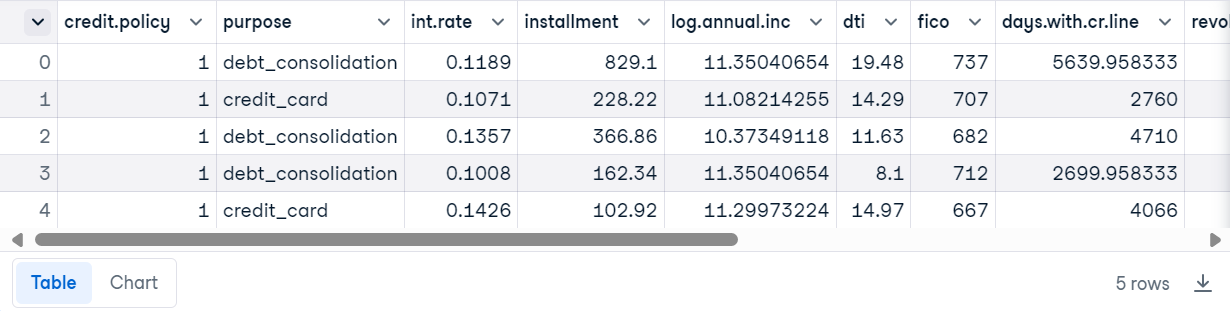
Créer un ensemble de données Deepchecks:
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
Test d'intégrité des données
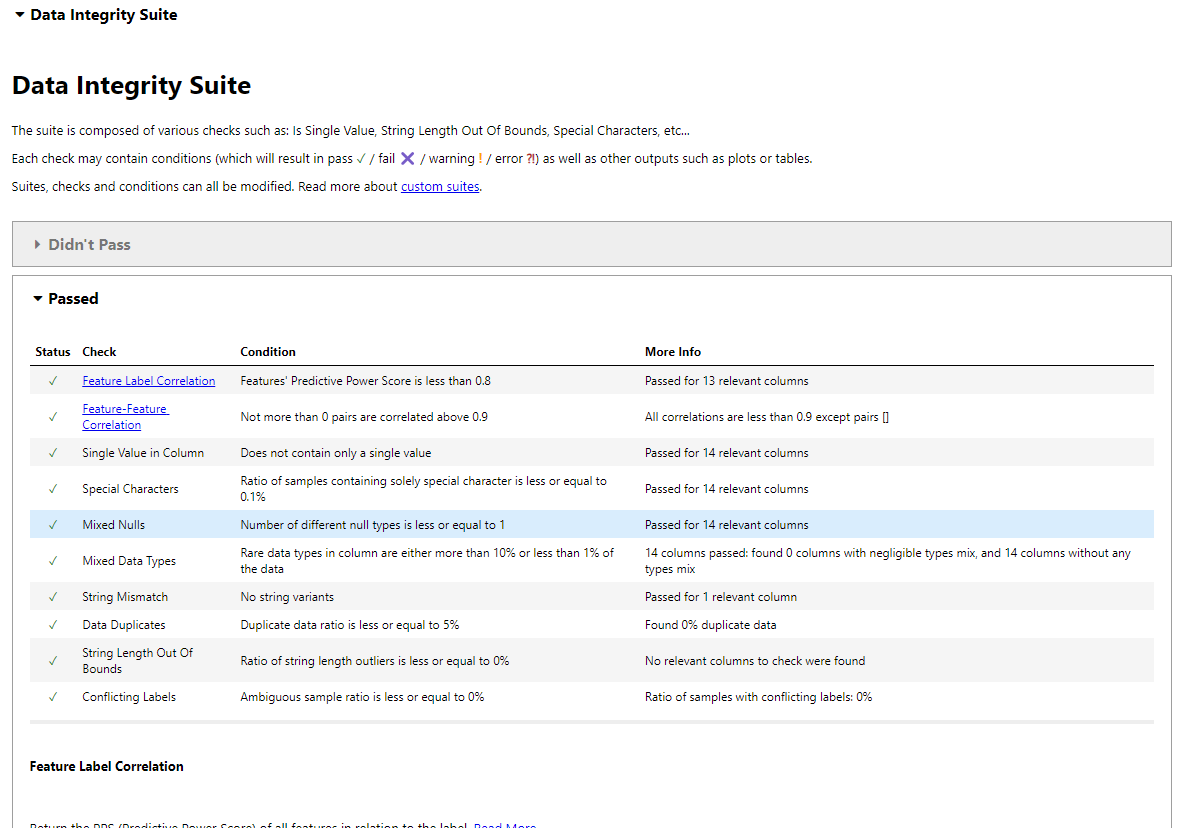
La suite d'intégrité des données de Deepchecks effectue des vérifications automatisées.
from deepchecks.tabular.suites import data_integrity integ_suite = data_integrity() suite_result = integ_suite.run(deep_loan_data) suite_result.show_in_iframe() # Use show_in_iframe for DataLab compatibility
Cela génère un rapport couvrant: corrélation d'étiquette de fonctionnalité, corrélation de fonction de fonctionnalité, vérification de valeur unique, détection spéciale des caractères, analyse de valeur nul, cohérence du type de données, décontrats de cordes, détection en double, validation de la longueur des chaînes, étiquettes contradictoires et détection des valeurs aberrantes.
Enregistrer le rapport:
suite_result.save_as_html()
Exécution de test individuel
Pour l'efficacité, exécutez des tests individuels:
from deepchecks.tabular.checks import IsSingleValue, DataDuplicates result = IsSingleValue().run(deep_loan_data) print(result.value) # Unique value counts per column result = DataDuplicates().run(deep_loan_data) print(result.value) # Duplicate sample count
Évaluation du modèle avec Deepchecks
Nous allons entraîner un modèle d'ensemble (régression logistique, forêt aléatoire, bayes naïve gaussien) et l'évaluer à l'aide de profondeurs.
pip install deepchecks --upgrade -q
Le rapport d'évaluation du modèle comprend: les courbes ROC, les performances faibles du segment, la détection des fonctionnalités inutilisées, la comparaison des performances des tests de train, l'analyse de la dérive de prédiction, les comparaisons simples du modèle, le temps d'inférence du modèle, les matrices de confusion, et plus encore.

Sortie JSON:
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()
Exemple de test individuel (dérive d'étiquette):
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
Automatisation avec les actions GitHub
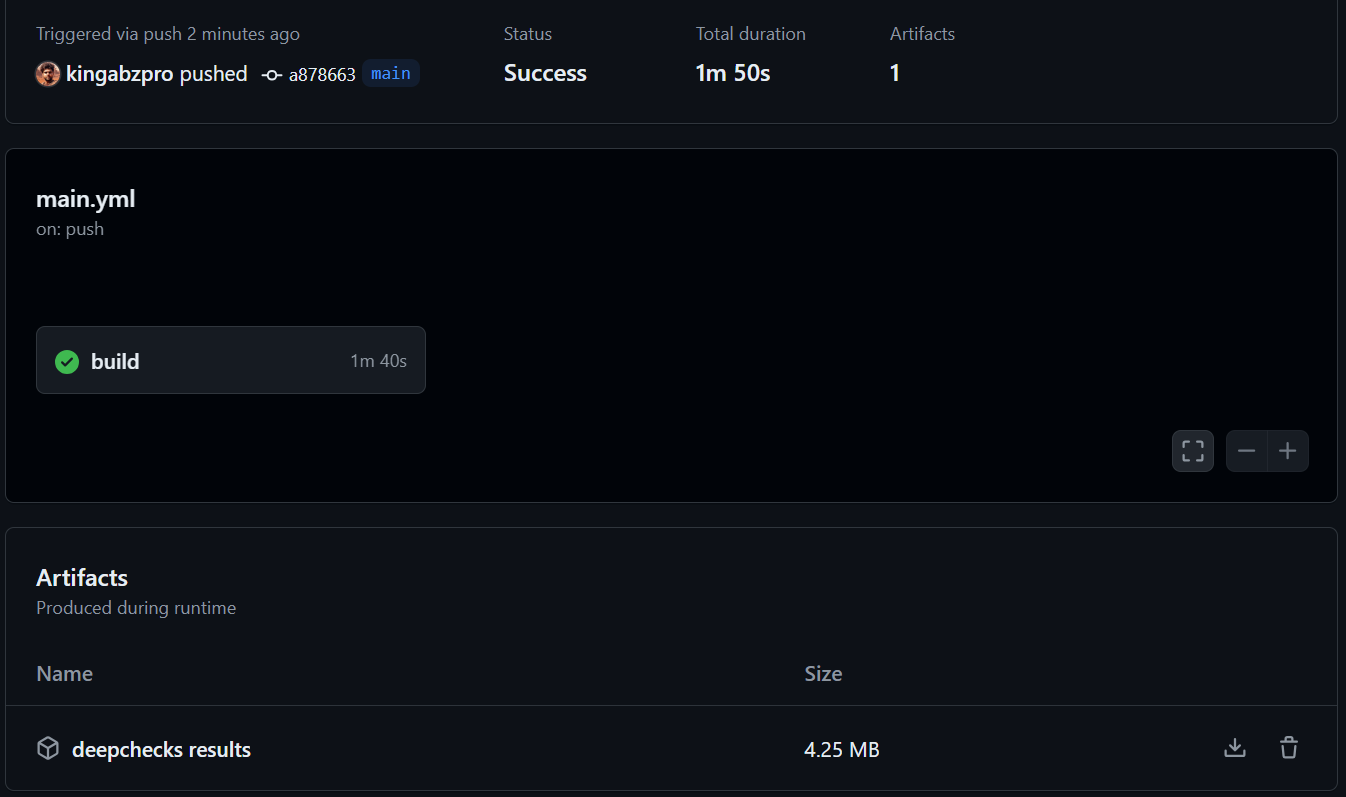
Cette section détaille la configuration d'un flux de travail GitHub Actions pour automatiser la validation des données et les tests de modèle. Le processus consiste à créer un référentiel, à ajouter des données et des scripts Python (data_validation.py, train_validation.py) et de configurer un flux de travail GitHub Actions (main.yml) pour exécuter ces scripts et enregistrer les résultats sous forme d'artefacts. Des étapes détaillées et des extraits de code sont fournis dans l'entrée d'origine. Reportez-vous au référentiel kingabzpro/Automating-Machine-Learning-Testing pour un exemple complet. Le flux de travail utilise les actions actions/checkout, actions/setup-python et actions/upload-artifact.
Conclusion
Les tests d'apprentissage automatique automatisant à l'aide de Deepchecks et des actions GitHub améliorent considérablement l'efficacité et la fiabilité. La détection précoce des problèmes améliore la précision du modèle et l'équité. Ce tutoriel fournit un guide pratique pour mettre en œuvre ce flux de travail, permettant aux développeurs de créer des systèmes d'IA plus robustes et dignes de confiance. Considérez le spécialiste de l'apprentissage automatique avec une piste de carrière Python pour un développement ultérieur dans ce domaine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI