
Maison >Périphériques technologiques >IA >Tutoriel LLAMA 3.2 90B: Application de légende d'image avec rationalisation et grogne
Tutoriel LLAMA 3.2 90B: Application de légende d'image avec rationalisation et grogne

- Lisa Kudroworiginal
- 2025-03-01 10:28:09577parcourir
Meta a finalement ajouté le multimodalité à l'écosystème de lama en introduisant les modèles de vision LLAMA 3.2 11b et 90b. Ces deux modèles excellent dans le traitement du texte et des images, ce qui m'a amené à essayer de construire un projet en utilisant la version 90b.
Dans cet article, je vais partager mon travail et vous guider à travers la création d'une application de sous-traitant d'image interactive en utilisant Streamlit pour le frontal et LLAMA 3.2 90b comme moteur pour générer des légendes.
Pourquoi utiliser Llama 3.2 90b pour une application de sous-titrage d'image
LLAMA 3.2-VISION 90B est un modèle de langage multimodal à la pointe de la technologie (LLM) construit pour des tâches impliquant à la fois des entrées d'image et de texte.
Il se démarque avec sa capacité à lutter contre les tâches complexes comme le raisonnement visuel, la reconnaissance d'image et le sous-titrage de l'image. Il a été formé sur un ensemble de données massif de 6 milliards de paires de texte d'image.
LLAMA 3.2-VISION est un excellent choix pour notre application car il prend en charge plusieurs langues pour les tâches de texte, bien que l'anglais soit son objectif principal pour les applications liées à l'image. Ses caractéristiques clés en font un excellent choix pour les tâches telles que la réponse à la question visuelle (VQA), le document VQA et la récupération de texte d'image, le sous-titrage de l'image étant l'une de ses applications remarquables.
Explorons comment ces capacités se traduisent par une application réelle comme le sous-titrage de l'image.
Pipeline de sous-titrage d'image
Le sous-titrage de l'image est le processus automatisé de génération de texte descriptif qui résume le contenu d'une image. Il combine la vision informatique et le traitement du langage naturel pour interpréter et exprimer des détails visuels dans le langage.
Traditionnellement, le sous-titrage de l'image a nécessité un pipeline complexe, impliquant souvent des étapes distinctes pour le traitement d'image et la génération de langues. L'approche standard implique trois étapes principales: le prétraitement d'image, l'extraction des caractéristiques et la génération de légendes.
- Prétraitement d'image: Les images sont généralement redimensionnées, normalisées et parfois recadrées pour s'assurer qu'elles répondent aux spécifications d'entrée du modèle.
- Extraction des fonctionnalités: les fonctionnalités visuelles sont extraites pour identifier des objets, des scènes ou des détails pertinents dans l'image. Dans la plupart des modèles, cela nécessite un modèle de vision distinct pour interpréter l'image, générant des données structurées que les modèles de langue peuvent comprendre.
- Génération de légende: ces caractéristiques extraites sont ensuite utilisées par un modèle de langue pour élaborer une description cohérente, combinant les objets, le contexte et les relations identifiés dans les données visuelles.
Avec Llama 3.2 90b, ce processus traditionnellement complexe devient plus simple. L'adaptateur de vision du modèle intègre des fonctionnalités visuelles dans le modèle de langue de base, lui permettant d'interpréter directement les images et de générer des légendes via des invites simples.
En intégrant les couches transversales au sein de son architecture, LLAMA 3.2 90B permet aux utilisateurs de décrire une image en invitant simplement le modèle - éliminant la nécessité de étapes distinctes de traitement. Cette simplicité permet un légende d'image plus accessible et efficace, où une seule invite peut produire une légende descriptive naturelle qui capture efficacement l'essence d'une image.
Présentation de l'application de sous-titrage d'image
Pour donner vie à la puissance de LLAMA 3.2 90b, nous créerons une application de sous-titrage d'image simple mais efficace en utilisant Streamlit pour le front-end et le GROQ pour générer des légendes.
L'application permettra aux utilisateurs de télécharger une image et de recevoir une légende descriptive générée par le modèle en seulement deux clics. Cette configuration est conviviale et nécessite des connaissances de codage minimales pour commencer.
Notre application comprendra les fonctionnalités suivantes:
- Titre: Un titre bien affiché, LLAMA Ségende, pour établir le but de l'application.
- Bouton de téléchargement: une interface pour télécharger des images à partir de l'appareil de l'utilisateur.
- Générer le bouton: un bouton pour initier le processus de génération de légende.
- Sortie de légende: l'application affichera la légende générée directement sur l'interface.
Implémentation de code pour notre application LLAMA 3.2 90b
L'API GROQ agira comme le pont entre l'image téléchargée de l'utilisateur et le modèle LLAMA 3.2-vision. Si vous voulez suivre et coder avec moi, assurez-vous d'abord:
- Obtenez votre clé API Groq en vous inscrivant à la console Groq.
- Enregistrez votre touche API dans un fichier idementials.json pour simplifier l'accès.
- Suivez le guide QuickStart de Groq pour l'installation et la configuration.
Cet extrait de code Python ci-dessous met en place une application Streamlit pour interagir avec l'API GROQ. Il comprend:
- Importe des bibliothèques pour le développement d'applications Web (Streamlit), les interactions AI (GROQ), la manipulation d'images (base64) et les opérations de fichiers (OS, JSON).
- lit la touche API Groq à partir d'un fichier JSON séparé pour une sécurité améliorée.
- définit une fonction pour coder des images au format Base64 pour une transmission et un traitement efficaces.
import streamlit as st
from groq import Groq
import base64
import os
import json
# Set up Groq API Key
os.environ['GROQ_API_KEY'] = json.load(open('credentials.json', 'r'))['groq_token']
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
Nous continuons en écrivant la fonction ci-dessous, qui est conçue pour générer une description textuelle d'une image téléchargée à l'aide de l'API GROQ. Voici une ventilation de sa fonctionnalité:
- Encodage d'image: l'image téléchargée est convertie en une chaîne codée Base64. Ce format permet à les données d'image d'être facilement transmises dans la demande d'API.
- Interaction API GROQ: Un client GROQ est instancié pour faciliter la communication avec le service GROQ. Une demande d'achèvement de chat est formulée, comprenant:
- une invite utilisateur: "Qu'y a-t-il dans cette image?"
- Les données d'image codées Base64, intégrées dans un URI de données. Le modèle LLAMA-3.2-90B-Vision-Preview est spécifié pour traiter l'image et générer une description textuelle.
- Extraction de légende: la légende générée est extraite de la réponse de l'API GROQ. Le contenu du message du premier choix, qui contient la légende, est retourné.
import streamlit as st
from groq import Groq
import base64
import os
import json
# Set up Groq API Key
os.environ['GROQ_API_KEY'] = json.load(open('credentials.json', 'r'))['groq_token']
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
Enfin, nous générons notre application Web interactive via Streamlit:
# Function to generate caption
def generate_caption(uploaded_image):
base64_image = base64.b64encode(uploaded_image.read()).decode('utf-8')
client = Groq()
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}
],
model="llama-3.2-90b-vision-preview",
)
return chat_completion.choices[0].message.content
La dernière application Streamlit: LLAMA SUBSEMBER
Cette application Streamlit fournit une interface conviviale pour le sous-titrage de l'image. Voici une ventilation de sa fonctionnalité:
- Titre et téléchargeur de fichiers:
- L'application affiche un titre: "LLAMA SENTINER".
- Un composant de téléchargeur de fichiers permet aux utilisateurs de sélectionner un fichier image (JPG, JPEG ou PNG).
- Affichage de l'image:
- Une fois qu'une image est téléchargée, l'application l'affiche en utilisant la fonction St.Image.
- Génération de légendes:
- un bouton, "Générer la légende", déclenche le processus de génération de légende.
- Lorsqu'il est cliqué, un spinner indique que la légende est générée.
- La fonction Generate_Caption est appelée pour traiter l'image téléchargée et obtenir une légende.
- Après une génération réussie, un message de réussite est affiché, suivi de la légende générée.
Le extrait ci-dessous est le code en action où une image d'Eddie Hall a été téléchargée pour générer la légende. Étonnamment, il a extrait même les informations qui n'étaient pas clairement visibles comme «l'homme le plus fort», etc.
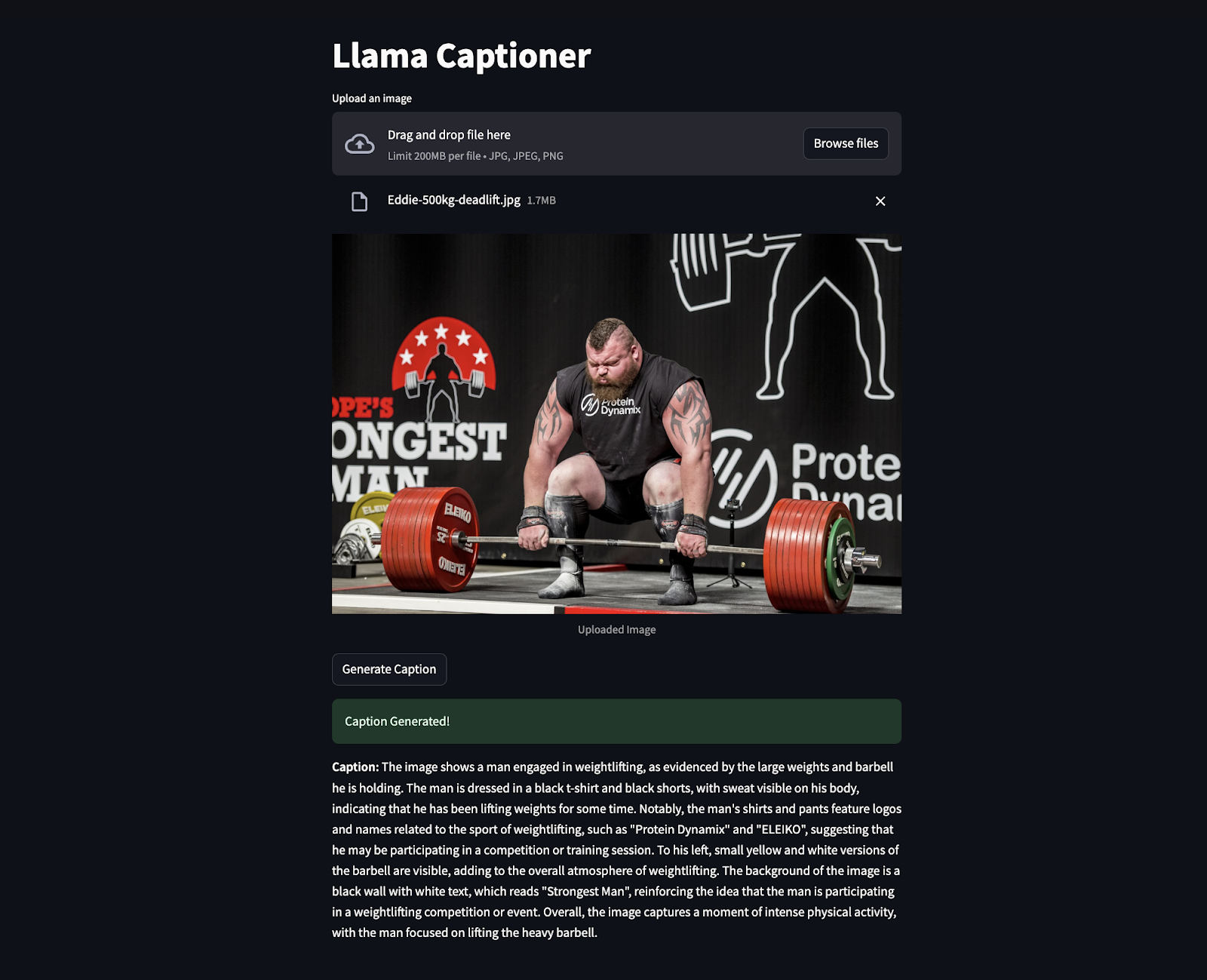
Conclusion
Créer une application de sous-titrage d'image avec LLAMA 3.2 90b et Streamlit montre comment une IA avancée peut faciliter les tâches difficiles. Ce projet combine un modèle puissant avec une interface simple pour créer un outil à la fois intuitif et facile à utiliser.
En tant qu'ingénieur d'IA, je vois un énorme potentiel dans des outils comme ceux-ci. Ils peuvent rendre la technologie plus accessible, aider les gens à mieux s'engager avec le contenu et automatiser les processus de manière plus intelligente.
Pour continuer votre apprentissage sur Llama, je recommande les ressources suivantes:
- Comment exécuter LLAMA 3.2 1B sur un téléphone Android avec Torchchat
- LLAMA 3.2 et Gradio Tutoriel: Créez une application Web multimodale
- LLAMA Stack: un guide avec des exemples pratiques
- LALAMATION DU TUNING FIEUX 3.2 et l'utiliser localement: un guide étape par étape
- lama 3.3: tutoriel étape par étape avec projet de démonstration
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI