
Maison >Périphériques technologiques >IA >Le mathing derrière l'apprentissage dans le contexte
Le mathing derrière l'apprentissage dans le contexte

- 王林original
- 2025-02-26 00:03:10645parcourir
Learning Learning (ICL), une caractéristique clé des modèles modernes de grande langue (LLMS), permet aux transformateurs de s'adapter en fonction des exemples dans l'invite d'entrée. L'incitation à quelques coups, en utilisant plusieurs exemples de tâches, démontre efficacement le comportement souhaité. Mais comment les transformateurs réalisent-ils cette adaptation? Cet article explore les mécanismes potentiels derrière ICL.

Le noyau d'ICL est: Étant donné des exemples de paires ((x, y)), les mécanismes d'attention peuvent-ils apprendre un algorithme pour cartographier de nouvelles requêtes (x) à leurs sorties (y)?
SoftMax Attention et recherche de voisin le plus proche
La formule d'attention Softmax est:
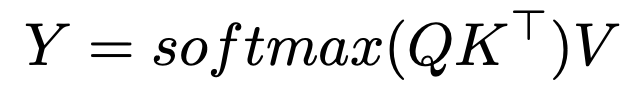
introduisant un paramètre de température inverse, c , modifie l'allocation d'attention:
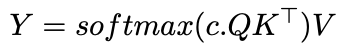
Comme C approche de l'infini, l'attention devient un vecteur à un hot, se concentrant uniquement sur le jeton le plus similaire - effectivement une recherche de voisin le plus proche. Avec un c fini, l'attention ressemble à un lissage du noyau gaussien. Cela suggère que ICL pourrait implémenter un algorithme de voisin le plus proche sur les paires d'entrée-sortie.
Implications et recherches supplémentaires
Comprendre comment les transformateurs apprennent les algorithmes (comme le voisin le plus proche) ouvre des portes pour Automl. Hollmann et al. Formation démontrée d'un transformateur sur les ensembles de données synthétiques pour apprendre l'intégralité du pipeline Automl, prédisant des modèles optimaux et des hyperparamètres à partir de nouvelles données en une seule passe.
La recherche d'Anthropic en 2022 suggère des «têtes d'induction» comme mécanisme. Ces paires de têtes d'attention copient et complets les modèles; Par exemple, étant donné "... a, b ... a", ils prédisent "b" basé sur le contexte antérieur.
Des études récentes (Garg et al. 2022, Oswald et al. 2023) lient l'ICL des transformateurs à la descente de gradient. Attention linéaire, omettant le fonctionnement Softmax:
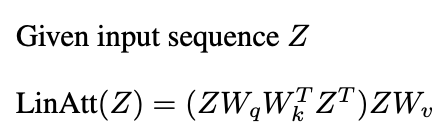
ressemble à une descente de gradient préconditionnée (PGD):
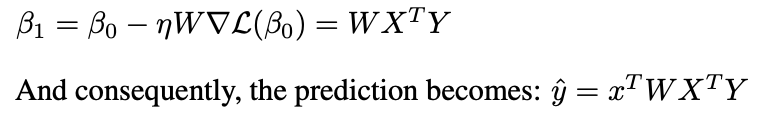
Une couche d'attention linéaire effectue une étape PGD.
Conclusion
Les mécanismes d'attention peuvent mettre en œuvre des algorithmes d'apprentissage, permettant à l'ICL en apprenant des paires de démonstration. Bien que l'interaction de plusieurs couches d'attention et des MLP soit complexe, la recherche met en lumière la mécanique d'ICL. Cet article offre un aperçu de haut niveau de ces idées.
Lire plus approfondie:
- Heads d'apprentissage et d'induction dans le contexte
- Que peuvent apprendre les transformateurs dans le contexte? Une étude de cas des classes de fonctions simples
- Les transformateurs apprennent dans le contexte par descente de gradient
- Les transformateurs apprennent à mettre en œuvre une descente de gradient préconditionnée pour l'apprentissage dans le contexte
Remerciements
Cet article est inspiré par l'automne 2024 Cours d'études supérieures à l'Université du Michigan. Toutes les erreurs sont uniquement celles de l'auteur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI