
Maison >développement back-end >Tutoriel Python >Premiers pas avec la recherche de vecteurs dans Azure Cosmos DB
Premiers pas avec la recherche de vecteurs dans Azure Cosmos DB

- Susan Sarandonoriginal
- 2025-01-26 20:15:09294parcourir
Ce didacticiel montre comment implémenter rapidement la recherche vectorielle dans Azure Cosmos DB pour NoSQL à l'aide d'un simple jeu de données de film. L'application est disponible en Python, TypeScript, .NET et Java, fournissant des instructions étape par étape pour les requêtes de configuration, de chargement de données et de recherche de similarité.
Les bases de données vectorielles excellent dans le stockage et la gestion des représentations vectorielles vectorielles, des représentations mathématiques de haute dimension des données. Chaque dimension reflète une caractéristique de données, pouvant se chiffrer en dizaines de milliers. L'emplacement d'un vecteur dans cet espace signifie ses caractéristiques. Cette technique vectorise divers types de données, notamment des mots, des phrases, des documents, des images et de l'audio, permettant des applications telles que la recherche de similarité, la recherche multimodale, les moteurs de recommandation et les grands modèles linguistiques (LLM).
Prérequis :
- Un abonnement Azure (ou un compte Azure gratuit, ou le niveau gratuit d'Azure Cosmos DB pour NoSQL).
- Un compte Azure Cosmos DB pour NoSQL.
- Une ressource Azure OpenAI Service avec le
text-embedding-ada-002modèle d'intégration déployé (accessible via le portail Azure AI Foundry). Ce modèle fournit des intégrations de texte. - L'environnement de langage de programmation nécessaire (Maven pour Java).
Configuration de la base de données vectorielles dans Azure Cosmos DB pour NoSQL :
-
Activer la fonctionnalité : Il s'agit d'une étape unique. Activez explicitement l’indexation vectorielle et la recherche dans Azure Cosmos DB.

-
Créer une base de données et un conteneur : Créez une base de données (par exemple,
movies_db) et un conteneur (par exemple,movies) avec une clé de partition de/id. -
Créer des politiques : Configurez une politique d'intégration de vecteurs et une politique d'indexation pour le conteneur. Pour cet exemple, utilisez les paramètres indiqués ci-dessous (la configuration manuelle via le portail Azure est utilisée ici, bien que des méthodes programmatiques soient également disponibles).
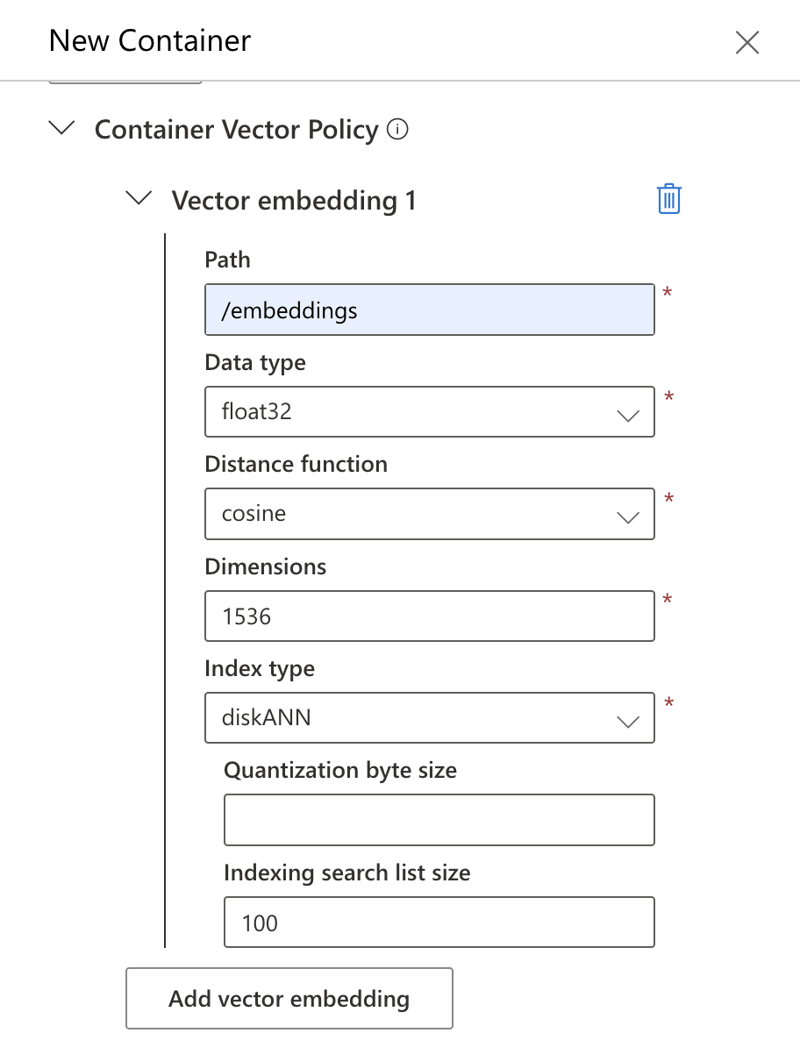
Remarque sur le type d'index : L'exemple utilise le type d'index
diskANNavec une dimension de 1536, correspondant au modèletext-embedding-ada-002. Bien qu'adaptable, la modification du type d'index nécessite d'ajuster le modèle d'intégration pour qu'il corresponde à la nouvelle dimension.
Chargement de données dans Azure Cosmos DB :
Un exemple de fichier movies.json fournit des données de film. Le processus implique :
- lire les informations du film du fichier JSON.
- Générer des incorporations vectorielles pour les descriptions de films à l'aide du service Azure Openai.
- Insertion des données complètes (titre, description et intégres) dans le conteneur Azure Cosmos DB.
Définissez les variables d'environnement suivantes avant de continuer:
<code class="language-bash">export COSMOS_DB_CONNECTION_STRING="" export DATABASE_NAME="" export CONTAINER_NAME="" export AZURE_OPENAI_ENDPOINT="" export AZURE_OPENAI_KEY="" export AZURE_OPENAI_VERSION="2024-10-21" export EMBEDDINGS_MODEL="text-embedding-ada-002"</code>
Clone le référentiel:
<code class="language-bash">git clone https://github.com/abhirockzz/cosmosdb-vector-search-python-typescript-java-dotnet cd cosmosdb-vector-search-python-typescript-java-dotnet</code>
Les instructions spécifiques à la langue pour le chargement des données sont fournies ci-dessous. Chaque méthode utilise les variables d'environnement définies ci-dessus. Une exécution réussie publiera des messages indiquant l'insertion de données dans Cosmos DB.
Instructions de chargement de données (abrégé):
- python:
cd python; python3 -m venv .venv; source .venv/bin/activate; pip install -r requirements.txt; python load.py - TypeScript:
cd typescript; npm install; npm run build; npm run load - java:
cd java; mvn clean install; java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar load - .net:
cd dotnet; dotnet restore; dotnet run load
Vérification des données dans Azure Cosmos DB:
confirmer l'insertion de données à l'aide du portail Azure ou d'une extension de code Visual Studio.

Recherche de vecteur / similitude:
Le composant de recherche utilise la fonction VectorDistance pour trouver des films similaires basés sur un critère de recherche (par exemple, "comédie"). Le processus est:
- Générer un vecteur incorporant pour le critère de recherche.
- Utiliser
VectorDistancepour le comparer avec les intérêts existants.
la requête:
<code class="language-sql">SELECT TOP @num_results c.id, c.description, VectorDistance(c.embeddings, @embedding) AS similarityScore FROM c ORDER BY VectorDistance(c.embeddings, @embedding)</code>
Instructions spécifiques à la langue (en supposant que les variables d'environnement sont définies et les données sont chargées):
Instructions de recherche (abrégé):
- python:
python search.py "inspiring" 3 - TypeScript:
npm run search "inspiring" 3 - java:
java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar search "inspiring" 3 - .net:
dotnet run search "inspiring" 3
Remarques de clôture:
Expérimentez avec différents types d'index vectoriels (flat, quantizedFlat), les métriques de distance (cosinus, euclidien, produit DOT) et les modèles d'intégration (text-embedding-3-large, text-embedding-3-small). Azure Cosmos DB pour MongoDB VCore prend également en charge la recherche de vecteurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!