

 interface Webjs tutorielNettoyer le contenu HTML pour une génération augmentée par récupération avec Readability.js
interface Webjs tutorielNettoyer le contenu HTML pour une génération augmentée par récupération avec Readability.js
Le Web scraping est une méthode courante de collecte de contenu pour votre application de génération augmentée par récupération (RAG). Cependant, l'analyse du contenu d'une page Web peut s'avérer difficile.
La bibliothèque open source Readability.js de Mozilla offre une solution pratique pour extraire uniquement les parties essentielles d'une page Web. Explorons son intégration dans un pipeline d'ingestion de données pour une application RAG.
Extraire des données non structurées à partir de pages Web
Les pages Web sont de riches sources de données non structurées, idéales pour les applications RAG. Cependant, les pages Web contiennent souvent des informations non pertinentes telles que des en-têtes, des barres latérales et des pieds de page. Bien qu'utile pour la navigation, ce contenu supplémentaire nuit au sujet principal de la page.
Pour des données RAG optimales, le contenu non pertinent doit être supprimé. Bien que des outils tels que Cheerio puissent analyser le HTML en fonction de la structure connue d'un site, cette approche est inefficace pour supprimer diverses mises en page de sites Web. Une méthode robuste est nécessaire pour extraire uniquement le contenu pertinent.
Exploiter la fonctionnalité Reader View
La plupart des navigateurs incluent une vue lecteur qui supprime tout sauf le titre et le contenu de l'article. L'image suivante illustre la différence entre la navigation standard et le mode lecteur appliqué à un article de blog DataStax :

Mozilla fournit Readability.js, la bibliothèque derrière le mode lecteur de Firefox, en tant que module open source autonome. Cela nous permet d'intégrer Readability.js dans un pipeline de données pour supprimer le contenu non pertinent et améliorer les résultats du scraping.
Scraping de données avec Node.js et Readability.js
Illustrons le contenu d'un article de scraping d'un article de blog précédent sur la création d'intégrations vectorielles dans Node.js. Le code JavaScript suivant récupère le HTML de la page :
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
Cela inclut tout le code HTML, y compris la navigation, les pieds de page et d'autres éléments courants sur les sites Web.
Vous pouvez également utiliser Cheerio pour sélectionner des éléments spécifiques :
npm install cheerio
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
Cela donne le titre et le texte de l'article. Cependant, cette approche repose sur la connaissance de la structure HTML, ce qui n'est pas toujours réalisable.
Une meilleure approche consiste à installer Readability.js et jsdom :
npm install @mozilla/readability jsdom
Readability.js fonctionne dans un environnement de navigateur, ce qui nécessite que jsdom simule cela dans Node.js. Nous pouvons convertir le HTML chargé en document et utiliser Readability.js pour analyser le contenu :
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
L'objet article contient divers éléments analysés :
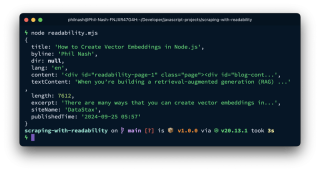
Cela inclut le titre, l'auteur, l'extrait, l'heure de publication et à la fois le HTML (content) et le texte brut (textContent). textContent est prêt pour le regroupement, l'intégration et le stockage, tandis que content conserve les liens et les images pour un traitement ultérieur.
La fonction isProbablyReaderable permet de déterminer si le document est adapté à Readability.js :
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
Les pages inappropriées doivent être signalées pour examen.
Intégrer la lisibilité avec LangChain.js
Readability.js s'intègre parfaitement à LangChain.js. L'exemple suivant utilise LangChain.js pour charger une page, extraire du contenu avec MozillaReadabilityTransformer, diviser le texte avec RecursiveCharacterTextSplitter, créer des intégrations avec OpenAI et stocker des données dans Astra DB.
Dépendances obligatoires :
npm install cheerio
Vous aurez besoin des informations d'identification Astra DB ( ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_API_ENDPOINT) et d'une clé API OpenAI (OPENAI_API_KEY) comme variables d'environnement.
Importer les modules nécessaires :
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
Initialiser les composants :
npm install @mozilla/readability jsdom
Charger, transformer, diviser, intégrer et stocker des documents :
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
Amélioration de la précision du Web Scraping avec Readability.js
Readability.js, une bibliothèque robuste qui alimente le mode lecteur de Firefox, extrait efficacement les données pertinentes des pages Web, améliorant ainsi la qualité des données RAG. Il peut être utilisé directement ou via le MozillaReadabilityTransformer de LangChain.js.
Ce n'est que la première étape de votre pipeline d'ingestion. Le regroupement, l'intégration et le stockage Astra DB sont les étapes suivantes de la création de votre application RAG.
Utilisez-vous d'autres méthodes pour nettoyer le contenu Web dans vos applications RAG ? Partagez vos techniques !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Remplacer les caractères de chaîne en javascriptMar 11, 2025 am 12:07 AM
Remplacer les caractères de chaîne en javascriptMar 11, 2025 am 12:07 AMExplication détaillée de la méthode de remplacement de la chaîne JavaScript et de la FAQ Cet article explorera deux façons de remplacer les caractères de chaîne dans JavaScript: le code JavaScript interne et le HTML interne pour les pages Web. Remplacer la chaîne dans le code JavaScript Le moyen le plus direct consiste à utiliser la méthode Remplace (): str = str.replace ("trouver", "remplacer"); Cette méthode remplace uniquement la première correspondance. Pour remplacer toutes les correspondances, utilisez une expression régulière et ajoutez le drapeau global G: str = str.replace (/ fi
 Comment créer et publier mes propres bibliothèques JavaScript?Mar 18, 2025 pm 03:12 PM
Comment créer et publier mes propres bibliothèques JavaScript?Mar 18, 2025 pm 03:12 PML'article discute de la création, de la publication et du maintien des bibliothèques JavaScript, en se concentrant sur la planification, le développement, les tests, la documentation et les stratégies de promotion.
 Comment optimiser le code JavaScript pour les performances dans le navigateur?Mar 18, 2025 pm 03:14 PM
Comment optimiser le code JavaScript pour les performances dans le navigateur?Mar 18, 2025 pm 03:14 PML'article traite des stratégies pour optimiser les performances JavaScript dans les navigateurs, en nous concentrant sur la réduction du temps d'exécution et la minimisation de l'impact sur la vitesse de chargement de la page.
 Effets de la matrice jQueryMar 10, 2025 am 12:52 AM
Effets de la matrice jQueryMar 10, 2025 am 12:52 AMApportez des effets de film de matrice à votre page! Ceci est un plugin jQuery cool basé sur le célèbre film "The Matrix". Le plugin simule les effets de caractère vert classique dans le film, et sélectionnez simplement une image et le plugin le convertira en une image de style matrice remplie de caractères numériques. Venez et essayez, c'est très intéressant! Comment ça marche Le plugin charge l'image sur la toile et lit le pixel et les valeurs de couleur: data = ctx.getImagedata (x, y, settings.grainsize, settings.grainsize) .data Le plugin lit intelligemment la zone rectangulaire de l'image et utilise jQuery pour calculer la couleur moyenne de chaque zone. Ensuite, utilisez
 Comment déboguer efficacement le code JavaScript à l'aide d'outils de développeur de navigateur?Mar 18, 2025 pm 03:16 PM
Comment déboguer efficacement le code JavaScript à l'aide d'outils de développeur de navigateur?Mar 18, 2025 pm 03:16 PML'article traite du débogage efficace de JavaScript à l'aide d'outils de développeur de navigateur, de se concentrer sur la définition des points d'arrêt, de l'utilisation de la console et d'analyser les performances.
 Comment construire un simple curseur jQueryMar 11, 2025 am 12:19 AM
Comment construire un simple curseur jQueryMar 11, 2025 am 12:19 AMCet article vous guidera pour créer un carrousel d'image simple à l'aide de la bibliothèque JQuery. Nous utiliserons la bibliothèque BXSLider, qui est construite sur jQuery et offre de nombreuses options de configuration pour configurer le carrousel. De nos jours, Picture Carrousel est devenue une fonctionnalité incontournable sur le site Web - une image vaut mieux que mille mots! Après avoir décidé d'utiliser le carrousel d'image, la question suivante est de savoir comment la créer. Tout d'abord, vous devez collecter des images de haute qualité et haute résolution. Ensuite, vous devez créer un carrousel d'image en utilisant HTML et un code JavaScript. Il existe de nombreuses bibliothèques sur le Web qui peuvent vous aider à créer des carrousels de différentes manières. Nous utiliserons la bibliothèque BXSLider open source. La bibliothèque Bxslider prend en charge la conception réactive, de sorte que le carrousel construit avec cette bibliothèque peut être adapté à n'importe quel
 Amélioration du balisage structurel avec JavaScriptMar 10, 2025 am 12:18 AM
Amélioration du balisage structurel avec JavaScriptMar 10, 2025 am 12:18 AMPoints clés Le marquage structuré amélioré avec JavaScript peut considérablement améliorer l'accessibilité et la maintenabilité du contenu de la page Web tout en réduisant la taille du fichier. JavaScript peut être utilisé efficacement pour ajouter dynamiquement des fonctionnalités aux éléments HTML, tels que l'utilisation de l'attribut CITE pour insérer automatiquement les liens de référence en références de bloc. L'intégration de JavaScript avec des balises structurées vous permet de créer des interfaces utilisateur dynamiques, telles que des panneaux d'onglet qui ne nécessitent pas de rafraîchissement de page. Il est crucial de s'assurer que les améliorations JavaScript ne gênent pas la fonctionnalité de base des pages Web; même si JavaScript est désactivé, la page doit rester fonctionnelle. La technologie avancée JavaScript peut être utilisée (
 Comment télécharger et télécharger des fichiers CSV avec AngularMar 10, 2025 am 01:01 AM
Comment télécharger et télécharger des fichiers CSV avec AngularMar 10, 2025 am 01:01 AMLes ensembles de données sont extrêmement essentiels pour créer des modèles d'API et divers processus métier. C'est pourquoi l'importation et l'exportation de CSV sont une fonctionnalité souvent nécessaire. Dans ce tutoriel, vous apprendrez à télécharger et à importer un fichier CSV dans un


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

ZendStudio 13.5.1 Mac
Puissant environnement de développement intégré PHP

Navigateur d'examen sécurisé
Safe Exam Browser est un environnement de navigation sécurisé permettant de passer des examens en ligne en toute sécurité. Ce logiciel transforme n'importe quel ordinateur en poste de travail sécurisé. Il contrôle l'accès à n'importe quel utilitaire et empêche les étudiants d'utiliser des ressources non autorisées.

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

Version Mac de WebStorm
Outils de développement JavaScript utiles

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

