
Maison >développement back-end >Tutoriel Python >Création d'un pipeline de statistiques NBA avec AWS, Python et DynamoDB
Création d'un pipeline de statistiques NBA avec AWS, Python et DynamoDB

- Mary-Kate Olsenoriginal
- 2025-01-21 22:14:20407parcourir
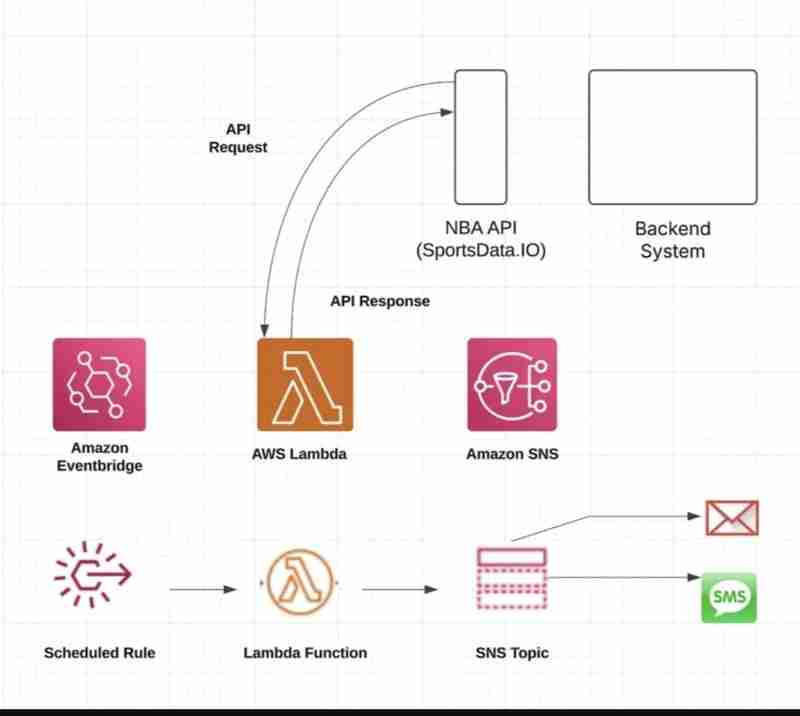
Ce didacticiel détaille la création d'un pipeline automatisé de données statistiques NBA à l'aide des services AWS, Python et DynamoDB. Que vous soyez un passionné de données sportives ou un apprenant AWS, ce projet pratique offre une expérience précieuse dans le traitement des données du monde réel.
Aperçu du projet
Ce pipeline récupère automatiquement les statistiques NBA de l'API SportsData, traite les données et les stocke dans DynamoDB. Les services AWS utilisés incluent :
- DynamoDB : Stockage des données
- Lambda : Exécution sans serveur
- CloudWatch : Surveillance et journalisation
Prérequis
Avant de commencer, assurez-vous d'avoir :
- Compétences de base en Python
- Un compte AWS
- L'AWS CLI installée et configurée
- Une clé API SportsData
Configuration du projet
Clonez le référentiel et installez les dépendances :
<code class="language-bash">git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt</code>
Configuration de l'environnement
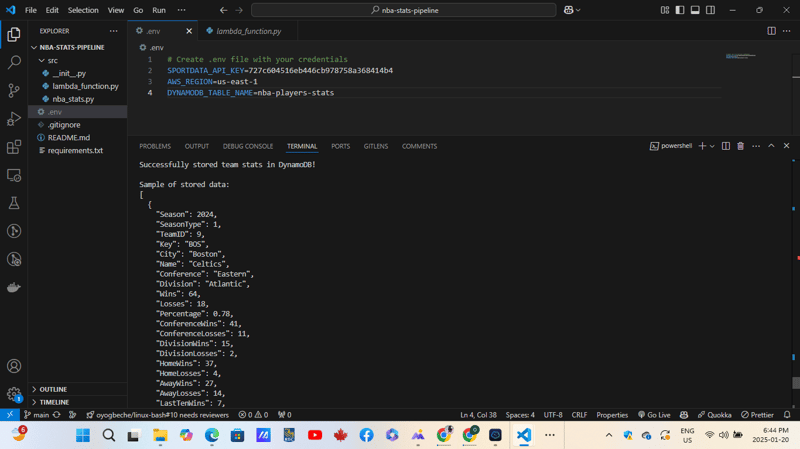
Créez un fichier .env à la racine du projet avec ces variables :
<code>SPORTDATA_API_KEY=your_api_key_here AWS_REGION=us-east-1 DYNAMODB_TABLE_NAME=nba-player-stats</code>
Structure du projet
La structure des répertoires du projet est la suivante :
<code>nba-stats-pipeline/ ├── src/ │ ├── __init__.py │ ├── nba_stats.py │ └── lambda_function.py ├── tests/ ├── requirements.txt ├── README.md └── .env</code>
Stockage et structure des données
Schéma DynamoDB
Le pipeline stocke les statistiques des équipes NBA dans DynamoDB en utilisant ce schéma :
- Clé de partition : TeamID
- Clé de tri : Horodatage
- Attributs : Statistiques de l'équipe (victoires/défaites, points par match, classement de la conférence, classement des divisions, mesures historiques)
Infrastructure AWS

Configuration des tables DynamoDB
Configurez la table DynamoDB comme suit :
- Nom de la table :
nba-player-stats - Clé primaire :
TeamID(Chaîne) - Clé de tri :
Timestamp(Nombre) - Capacité provisionnée : ajustez selon les besoins
Configuration de la fonction Lambda (si vous utilisez Lambda)
- Exécution : Python 3.9
- Mémoire : 256 Mo
- Délai d'expiration : 30 secondes
- Gestionnaire :
lambda_function.lambda_handler
Gestion et surveillance des erreurs
Le pipeline inclut une gestion robuste des erreurs pour les échecs d'API, la limitation DynamoDB, les problèmes de transformation de données et les réponses d'API non valides. CloudWatch enregistre tous les événements au format JSON structuré pour la surveillance des performances, le débogage et garantir le succès du traitement des données.
Nettoyage des ressources
Une fois le projet terminé, nettoyez les ressources AWS :
<code class="language-bash">git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt</code>
Principaux points à retenir
Ce projet a mis en lumière :
- Intégration des services AWS : Utilisation efficace de plusieurs services AWS pour un pipeline de données cohérent.
- Gestion des erreurs : L'importance d'une gestion approfondie des erreurs dans les environnements de production.
- Surveillance : Rôle essentiel de la journalisation et de la surveillance dans la maintenance des pipelines de données.
- Gestion des coûts : Conscience de l'utilisation et du nettoyage des ressources AWS.
Améliorations futures
Les extensions possibles du projet incluent :
- Intégration des statistiques de jeu en temps réel
- Mise en œuvre de la visualisation des données
- Points de terminaison API pour l'accès aux données
- Capacités avancées d'analyse de données
Conclusion
Ce pipeline de statistiques NBA démontre la puissance de la combinaison des services AWS et de Python pour créer des pipelines de données fonctionnels. Il s'agit d'une ressource précieuse pour ceux qui s'intéressent à l'analyse sportive ou au traitement des données AWS. Partagez vos expériences et suggestions d'amélioration !
Suivez pour plus de didacticiels AWS et Python ! Appréciez un ❤️ et un ? si vous avez trouvé cela utile !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!