
Maison >développement back-end >Tutoriel Python >Comment supprimer les avis Target.com avec Python
Comment supprimer les avis Target.com avec Python

- DDDoriginal
- 2025-01-06 06:41:41525parcourir
Introduction
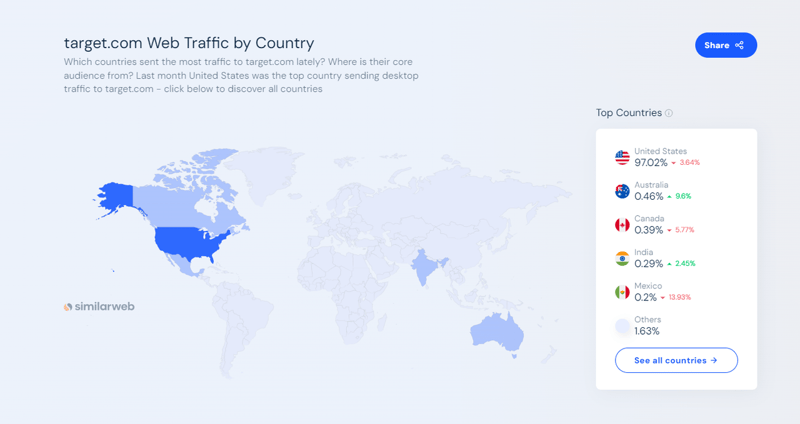
Target.com est l'une des plus grandes places de marché de commerce électronique et de shopping d'Amérique. Il permet aux consommateurs d'acheter de tout en ligne et en magasin, des produits d'épicerie et des produits essentiels aux vêtements et aux appareils électroniques. En septembre 2024, selon les données de SimilarWeb, Target.com attirait un trafic Web mensuel de plus de 166 millions.
Le site Web Target.com propose, entre autres, des avis clients, des informations dynamiques sur les prix, des comparaisons de produits et des évaluations de produits. Il s'agit d'une source de données précieuse pour les analystes, les équipes marketing, les entreprises ou les chercheurs qui souhaitent suivre les tendances des produits, surveiller les prix des concurrents ou analyser les sentiments des clients à travers les avis.
Dans cet article, vous apprendrez comment :
- Configurer et installer Python, Selenium et Beautiful Soup pour le web scraping
- Récupérez les avis et les notes sur les produits de Target.com à l'aide de Python
- Utilisez ScraperAPI pour contourner efficacement les mécanismes anti-scraping de Target.com
- Mettre en œuvre des proxys pour éviter les interdictions d'adresses IP et améliorer les performances de scraping
À la fin de cet article, vous apprendrez comment collecter des avis et des évaluations de produits sur Target.com à l'aide de Python, Selenium et ScraperAPI sans être bloqué. Vous apprendrez également à utiliser vos données récupérées pour l'analyse des sentiments.
Si vous êtes enthousiasmé au moment où j'écris ce tutoriel, allons-y directement. ?
TL;DR : Scraping Target Product Review [Code complet]
Pour ceux qui sont pressés, voici l'extrait de code complet que nous allons construire à partir de ce tutoriel :
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Découvrez le code complet sur GitHub : https://github.com/Eunit99/target_com_scraper. Vous voulez comprendre chaque ligne de code ? Construisons ensemble le web scraper à partir de zéro !
Comment supprimer les avis Target.com avec Python et ScraperAPI
Dans un article précédent, nous avons couvert tout ce que vous devez savoir pour récupérer les données des produits Target.com. Cependant, dans cet article, je me concentrerai sur la façon de récupérer Target.com pour les évaluations et les avis sur les produits avec Python et ScraperAPI.
Conditions préalables
Pour suivre ce tutoriel et commencer à scraper Target.com, vous devrez d'abord faire quelques choses.
1. Avoir un compte avec ScraperAPI
Commencez avec un compte gratuit sur ScraperAPI. ScraperAPI vous permet de commencer à collecter des données à partir de millions de sources Web sans solutions de contournement complexes et coûteuses grâce à notre API facile à utiliser pour le web scraping.
ScraperAPI déverrouille même les sites les plus difficiles, réduit les coûts d'infrastructure et de développement, vous permet de déployer des web scrapers plus rapidement et vous offre également 1 000 crédits API gratuits pour essayer des choses en premier, et bien plus encore.
2. Éditeur de texte ou IDE
Utilisez un éditeur de code comme Visual Studio Code. D'autres options incluent Sublime Text ou PyCharm.
3. Exigences du projet et configuration de l'environnement virtuel
Avant de commencer à récupérer les avis Target.com, assurez-vous d'avoir les éléments suivants :
- Python installé sur votre machine (version 3.10 ou plus récente)
- pip (installateur du package Python)
Il est recommandé d'utiliser un environnement virtuel pour les projets Python afin de gérer les dépendances et d'éviter les conflits.
Pour créer un environnement virtuel, exécutez cette commande dans votre terminal :
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
4. Activation de l'environnement virtuel
Activez l'environnement virtuel en fonction de votre système d'exploitation :
python3 -m venv env
Certains IDE peuvent activer automatiquement l'environnement virtuel.
5. Avoir une compréhension de base des sélecteurs CSS et des outils de développement du navigateur de navigation
Pour suivre efficacement cet article, il est essentiel d'avoir une compréhension de base des sélecteurs CSS. Les sélecteurs CSS sont utilisés pour cibler des éléments HTML spécifiques sur une page Web, ce qui vous permet d'extraire les informations dont vous avez besoin.
De plus, être à l'aise avec les DevTools du navigateur est crucial pour inspecter et identifier la structure des pages Web.
Configuration du projet
Après avoir satisfait aux prérequis ci-dessus, il est temps de monter votre projet. Commencez par créer un dossier qui contiendra le code source du scraper Target.com. Dans ce cas, je nommerai mon dossier python-target-dot-com-scraper.
Exécutez les commandes suivantes pour créer un dossier nommé python-target-dot-com-scraper :
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
Entrez dans le dossier et créez un nouveau fichier Python main.py en exécutant ces commandes :
mkdir python-target-dot-com-scraper
Créez un fichier exigences.txt en exécutant la commande suivante :
cd python-target-dot-com-scraper && touch main.py
Pour cet article, j'utiliserai les bibliothèques Selenium et Beautiful Soup, ainsi que Webdriver Manager pour Python pour créer le web scraper. Selenium gérera l'automatisation du navigateur et la bibliothèque Beautiful Soup extraira les données du contenu HTML du site Web Target.com. Dans le même temps, Webdriver Manager pour Python fournit un moyen de gérer automatiquement les pilotes pour différents navigateurs.
Ajoutez les lignes suivantes à votre fichier exigences.txt pour spécifier les packages nécessaires :
touch requirements.txt
Pour installer les packages, exécutez la commande suivante :
selenium~=4.25.0 bs4~=0.0.2 python-dotenv~=1.0.1 webdriver_manager selenium-wire blinker==1.7.0 python-dotenv==1.0.1
Extraire les avis sur les produits Target.com avec Selenium
Dans cette section, je vais vous guider à travers un guide étape par étape pour obtenir des notes et des avis sur des produits à partir d'une page de produit comme celle-ci de Target.com.
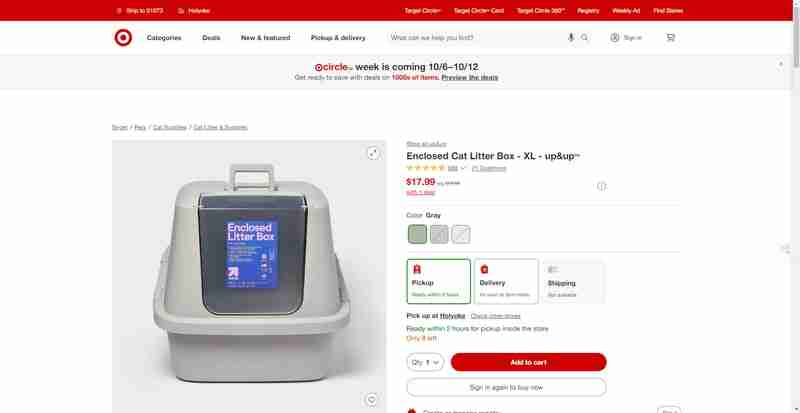
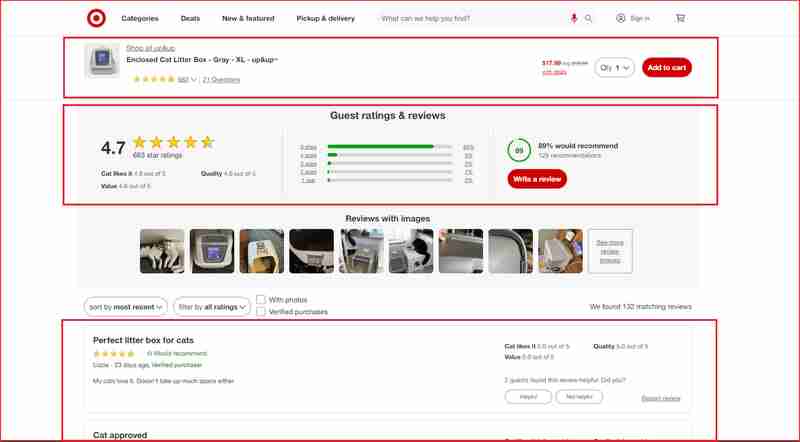
Je me concentrerai sur les avis et les notes de ces sections du site Web mises en évidence dans cette capture d'écran ci-dessous :
Avant d'approfondir, vous devez comprendre la structure HTML et identifier le sélecteur DOM associé à la balise HTML enveloppant les informations que nous souhaitons extraire. Dans cette section suivante, je vais vous expliquer comment utiliser Chrome DevTools pour comprendre la structure du site Target.com.
Utilisation de Chrome DevTools pour comprendre la structure du site Target.com
Ouvrez Chrome DevTools en appuyant sur F12 ou en cliquant avec le bouton droit n'importe où sur la page et en choisissant Inspecter. L'inspection de la page à partir de l'URL ci-dessus révèle ce qui suit :
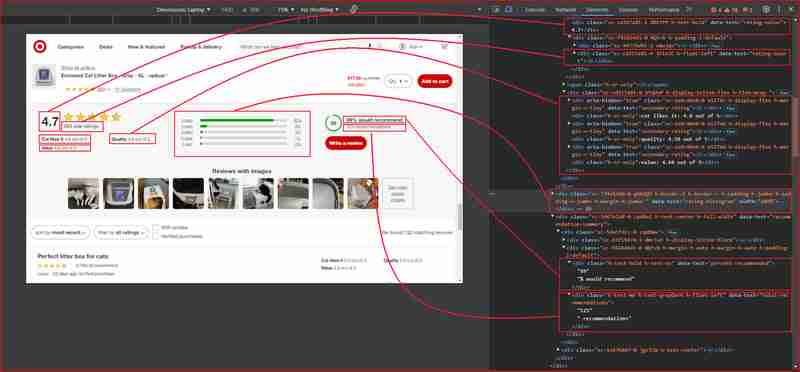
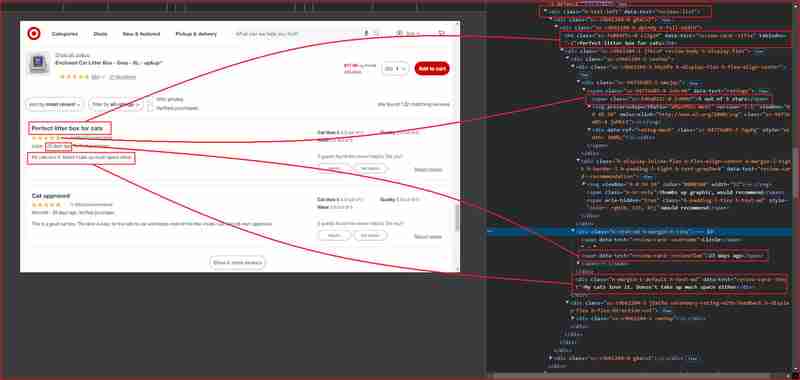
À partir des images ci-dessus, voici tous les sélecteurs DOM que le web scraper ciblera pour extraire les informations :
| Information | DOM selector | Value |
|---|---|---|
| Product ratings | ||
| Rating value | div[data-test='rating-value'] | 4.7 |
| Rating count | div[data-test='rating-count'] | 683 star ratings |
| Secondary rating | div[data-test='secondary-rating'] | 683 star ratings |
| Rating histogram | div[data-test='rating-histogram'] | 5 stars 85%4 stars 8%3 stars 3%2 stars 1%1 star 2% |
| Percent recommended | div[data-test='percent-recommended'] | 89% would recommend |
| Total recommendations | div[data-test='total-recommendations'] | 125 recommendations |
| Product reviews | ||
| Reviews list | div[data-test='reviews-list'] | Returns children elements corresponding to individual product review |
| Review card title | h4[data-test='review-card--title'] | Perfect litter box for cats |
| Ratings | span[data-test='ratings'] | 4.7 out of 5 stars with 683 reviews |
| Review time | span[data-test='review-card--reviewTime'] | 23 days ago |
| Review card text | div[data-test='review-card--text'] | My cats love it. Doesn't take up much space either |
Construire votre grattoir d'avis cible
Maintenant que nous avons décrit toutes les exigences et localisé les différents éléments qui nous intéressent sur la page d'évaluation des produits Target.com. Nous allons passer à l'étape suivante qui consiste à importer les modules nécessaires :
1. Importation de Selenium et d'autres modules
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Dans ce code, chaque module répond à un objectif spécifique pour créer notre web scraper :
- os gère les variables d'environnement telles que les clés API.
- le temps introduit des retards lors du chargement des pages.
- dotenv charge les clés API à partir des fichiers .env.
- le sélénium permet l'automatisation et l'interaction du navigateur.
- webdriver_manager installe automatiquement ChromeDriver.
- BeautifulSoup analyse le HTML pour l'extraction de données.
- seleniumwire gère les proxys pour le scraping sans interdictions IP.
2. Configuration du pilote Web
Dans cette étape, vous initialiserez Chrome WebDriver de Selenium et configurerez les options importantes du navigateur. Ces options incluent la désactivation des fonctionnalités inutiles pour améliorer les performances, la définition de la taille de la fenêtre et la gestion des journaux. Vous instancierez WebDriver à l'aide de webdriver.Chrome() pour contrôler le navigateur tout au long du processus de scraping.
python3 -m venv env
Créer une fonction de défilement vers le bas
Dans cette section, nous créons une fonction pour faire défiler toute la page. Le site Web Target.com charge du contenu supplémentaire (tel que des avis) de manière dynamique à mesure que l'utilisateur fait défiler vers le bas.
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
La fonction scroll_down_page() fait défiler progressivement la page Web d'un nombre défini de pixels (distance) avec une courte pause (délai) entre chaque défilement. Il calcule d’abord la hauteur totale de la page et fait défiler vers le bas jusqu’au bas. Au fur et à mesure du défilement, la hauteur totale de la page est mise à jour dynamiquement pour s'adapter au nouveau contenu susceptible de se charger au cours du processus.
Combiner le sélénium avec BeautifulSoup
Dans cette section, nous combinons les atouts de Selenium et de BeautifulSoup pour créer une configuration de web scraping efficace et fiable. Alors que Selenium est utilisé pour interagir avec du contenu dynamique comme le chargement de pages et la gestion des éléments rendus en JavaScript, BeautifulSoup est plus efficace pour analyser et extraire des éléments HTML statiques. Nous utilisons d'abord Selenium pour naviguer sur la page Web et attendre que des éléments spécifiques, tels que les évaluations des produits et le nombre d'avis, se chargent. Ces éléments sont extraits avec la fonction WebDriverWait de Selenium, qui garantit que les données sont visibles avant de les capturer. Cependant, gérer les avis individuels via Selenium seul peut devenir complexe et inefficace.
En utilisant BeautifulSoup, nous simplifions le processus de lecture en boucle de plusieurs avis sur la page. Une fois que Selenium a entièrement chargé la page, BeautifulSoup analyse le contenu HTML pour extraire efficacement les avis. En utilisant les méthodes select() et select_one() de BeautifulSoup, nous pouvons parcourir la structure de la page et rassembler le titre, la note, l'heure et le texte de chaque avis. Cette approche permet un grattage plus propre et plus structuré des éléments répétés (comme des listes d'avis) et offre une plus grande flexibilité dans la gestion du HTML, par rapport à la gestion de tout via Selenium seul.
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Utilisation de proxys dans Python Selenium : une interaction complexe avec les navigateurs sans tête
Lors du scraping de sites Web complexes, en particulier ceux dotés de mesures anti-bot robustes comme Target.com, des défis tels que les interdictions IP, les limites de débit ou les restrictions d'accès surviennent souvent. Utiliser Selenium pour de telles tâches devient complexe, en particulier lors du déploiement d'un navigateur sans tête. Les navigateurs sans tête permettent une interaction sans interface graphique, mais la gestion manuelle des proxys dans cet environnement devient difficile. Vous devez configurer les paramètres de proxy, faire pivoter les adresses IP et gérer d'autres interactions telles que le rendu JavaScript, ce qui rend le scraping plus lent et sujet aux échecs.
En revanche, ScraperAPI rationalise considérablement ce processus en gérant automatiquement les proxys. Plutôt que de gérer des configurations manuelles dans Selenium, le mode proxy de ScraperAPI distribue les requêtes sur plusieurs adresses IP, garantissant ainsi un scraping plus fluide sans se soucier des interdictions IP, des limites de débit ou des restrictions géographiques. Cela devient particulièrement utile lorsque vous travaillez avec des navigateurs sans tête, où la gestion du contenu dynamique et des interactions complexes sur le site nécessite un codage supplémentaire.
Configuration de ScraperAPI avec Selenium
L'intégration du mode proxy de ScraperAPI avec Selenium est simplifiée en utilisant Selenium Wire, un outil qui permet une configuration facile du proxy. Voici une configuration rapide :
- Inscrivez-vous à ScraperAPI : Créez un compte et récupérez votre clé API.
- Installer Selenium Wire : remplacez Selenium standard par Selenium Wire en exécutant pip install selenium-wire.
- Configurer le proxy : utilisez le pool de proxy de ScraperAPI dans vos paramètres WebDriver pour gérer les rotations IP sans effort.
Une fois intégrée, cette configuration permet des interactions plus fluides avec des pages dynamiques, des adresses IP à rotation automatique et le contournement des limites de débit sans les tracas manuels liés à la gestion des proxys dans un environnement de navigateur sans tête.
L'extrait ci-dessous montre comment configurer le proxy de ScraperAPI en Python :
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Avec cette configuration, les requêtes envoyées au serveur proxy ScraperAPI sont redirigées vers le site Web Target.com, gardant votre véritable adresse IP cachée et fournissant une défense robuste contre les mécanismes anti-scraping du site Web Target.com. Le proxy peut également être personnalisé en incluant des paramètres tels que render=true pour le rendu JavaScript ou en spécifiant un country_code pour la géolocalisation.
Données d'examen supprimées de Target.com
Le code JSON ci-dessous est un exemple de réponse utilisant le Target Reviews Scraper :
python3 -m venv env
Comment utiliser notre grattoir d'avis Cloud Target.com
Si vous souhaitez obtenir rapidement vos avis Target.com sans configurer votre environnement, savoir coder ou configurer des proxys, vous pouvez utiliser notre API Target Scraper pour obtenir gratuitement les données dont vous avez besoin. L'API Target Scraper est hébergée sur la plateforme Apify et est prête à être utilisée sans aucune configuration requise.
Rendez-vous sur Apify et cliquez sur « Essayer gratuitement » pour commencer maintenant.

Utilisation des avis cibles pour l'analyse des sentiments
Maintenant que vous disposez de vos données d'avis et de notes Target.com, il est temps de donner un sens à ces données. Ces données d'avis et de notes peuvent fournir des informations précieuses sur les opinions des clients sur un produit ou un service particulier. En analysant ces avis, vous pouvez identifier les éloges et les plaintes courantes, évaluer la satisfaction des clients, prédire le comportement futur et transformer ces avis en informations exploitables.
En tant que professionnel du marketing ou propriétaire d'entreprise cherchant des moyens de mieux comprendre votre public principal et d'améliorer vos stratégies marketing et produits. Vous trouverez ci-dessous quelques façons de transformer ces données en informations exploitables pour optimiser les efforts marketing, améliorer les stratégies produits et stimuler l'engagement client :
- Affiner les offres de produits : identifiez les plaintes ou les éloges courants des clients pour affiner les fonctionnalités du produit.
- Amélioration du service client : détectez rapidement les avis négatifs pour résoudre les problèmes et maintenir la satisfaction des clients.
- Optimisation des campagnes marketing : utilisez les informations issues des commentaires positifs pour créer des campagnes personnalisées et ciblées.
En utilisant ScraperAPI pour collecter des données d'avis à grande échelle à grande échelle, vous pouvez automatiser et faire évoluer l'analyse des sentiments, permettant ainsi une meilleure prise de décision et une meilleure croissance.
FAQ sur le scraping des avis sur les produits cibles
Est-il légal de supprimer les pages de produits Target.com ?
Oui, il est légal d'accéder à Target.com pour obtenir des informations accessibles au public, telles que les évaluations et les avis sur les produits. Mais il est important de se rappeler que ces informations publiques peuvent toujours inclure des données personnelles.
Nous avons rédigé un article de blog sur les aspects juridiques du web scraping et les considérations éthiques. Vous pouvez en apprendre davantage là-bas.
Target.com bloque-t-il les scrapers ?
Oui, Target.com met en œuvre diverses mesures anti-scraping pour bloquer les scrapers automatisés. Il s'agit notamment du blocage IP, de la limitation du débit et des défis CAPTCHA, tous conçus pour détecter et arrêter les requêtes automatisées excessives provenant de scrapers ou de robots.
Comment éviter d’être bloqué par Target.com ?
Pour éviter d'être bloqué par Target.com, vous devez ralentir le taux de requêtes, alterner les agents utilisateurs, utiliser des techniques de résolution de CAPTCHA et éviter de faire des requêtes répétitives ou à haute fréquence. La combinaison de ces méthodes avec des proxys peut aider à réduire la probabilité de détection.
Envisagez également d'utiliser des scrapers dédiés comme l'API Target Scraper ou l'API Scraping pour contourner ces limitations de Target.com.
Dois-je utiliser des proxys pour supprimer Target.com ?
Oui, l'utilisation de proxys est essentielle pour gratter efficacement Target.com. Les proxys aident à répartir les requêtes sur plusieurs adresses IP, minimisant ainsi les risques de blocage. Les proxys ScraperAPI masquent votre adresse IP, ce qui rend plus difficile la détection de votre activité par les systèmes anti-scraping.
Conclusion
Dans cet article, vous avez appris à créer un grattoir de notes et d'avis Target.com à l'aide de Python, Selenium et à utiliser ScraperAPI pour contourner efficacement les mécanismes anti-scraping de Target.com, éviter les interdictions IP et améliorer les performances de grattage.
Avec cet outil, vous pouvez collecter de précieux commentaires clients de manière efficace et fiable.
Une fois que vous avez collecté ces données, l'étape suivante consiste à utiliser l'analyse des sentiments pour découvrir des informations clés. En analysant les avis des clients, vous, en tant qu'entreprise, pouvez identifier les points forts des produits, résoudre les problèmes et optimiser vos stratégies marketing pour mieux répondre aux besoins de vos clients.
En utilisant l'API Target Scraper pour la collecte de données à grande échelle, vous pouvez surveiller en permanence les avis et garder une longueur d'avance dans la compréhension du sentiment des clients, ce qui vous permet d'affiner le développement de produits et de créer des campagnes marketing plus ciblées.
Essayez ScraperAPI dès maintenant pour une extraction transparente de données à grande échelle ou utilisez notre Cloud Target.com Reviews Scraper !
Pour plus de tutoriels et de contenus intéressants, suivez-moi sur Twitter (X) @ eunit99
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!