
 JavajavaDidacticielIntégration de modèles d'IA sans effort : créer et évaluer des modèles d'IA (Spring Boot et Hugging Face)
JavajavaDidacticielIntégration de modèles d'IA sans effort : créer et évaluer des modèles d'IA (Spring Boot et Hugging Face)
La révolution de l'IA est là, et avec elle une liste toujours croissante de modèles puissants capables de générer du texte, de créer des visuels et de résoudre des problèmes complexes. Mais soyons réalistes : avec autant d’options, déterminer quel modèle convient le mieux à votre projet peut s’avérer une tâche ardue. Et s'il existait un moyen de tester rapidement ces modèles, de voir leurs résultats en action et de décider lequel intégrer dans votre système de production ?
Accédez à l'API d'inférence de Hugging Face : votre raccourci pour explorer et exploiter des modèles d'IA de pointe. Il élimine les tracas liés à la configuration, à l'hébergement ou à la formation des modèles en offrant une solution plug-and-play. Que vous réfléchissiez à une nouvelle fonctionnalité ou évaluiez les capacités d'un modèle, Hugging Face rend l'intégration de l'IA plus simple que jamais.
Dans ce blog, je vais vous guider dans la création d'une application backend légère à l'aide de Spring Boot qui vous permet de tester et d'évaluer des modèles d'IA sans effort. Voici ce à quoi vous pouvez vous attendre :
? Ce que vous apprendrez
- Accéder aux modèles IA : découvrez comment utiliser l'API d'inférence de Hugging Face pour explorer et tester des modèles.
- Créer un backend : créez une application Spring Boot pour interagir avec ces modèles.
- Modèles de test : configurez et testez les points de terminaison pour la génération de texte et d'images à l'aide d'exemples d'invites.
À la fin, vous disposerez d’un outil pratique pour tester différents modèles d’IA et prendre des décisions éclairées quant à leur adéquation aux besoins de votre projet. Si vous êtes prêt à combler le fossé entre la curiosité et la mise en œuvre, commençons !
?️ Pourquoi l'API d'inférence de visage Hugging ?
Voici pourquoi Hugging Face change la donne pour l’intégration de l’IA :
- Facilité d'utilisation : pas besoin de former ou de déployer des modèles : il suffit d'appeler l'API.
- Variété : accédez à plus de 150 000 modèles pour des tâches telles que la génération de texte, la création d'images, etc.
- Évolutivité : parfait pour le prototypage et l'utilisation en production.
? Ce que vous construirez
Nous allons créer QuickAI, une application Spring Boot qui :
- Génère du texte : créez du contenu créatif basé sur une invite.
- Génère des images : transformez les descriptions textuelles en visuels.
- Fournit une documentation sur l'API : utilisez Swagger pour tester et interagir avec l'API.
? Commencer
Étape 1 : Inscrivez-vous à Hugging Face
Rendez-vous sur huggingface.co et créez un compte si vous n'en avez pas déjà un.
Étape 2 : Obtenez votre clé API
Accédez aux paramètres de votre compte et générez une clé API. Cette clé permettra à votre application Spring Boot d'interagir avec l'API d'inférence de Hugging Face.
Étape 3 : Explorer les modèles
Consultez le Hub de modèles Hugging Face pour trouver des modèles adaptés à vos besoins. Pour ce tutoriel, nous utiliserons :
- Un modèle de génération de texte (par exemple, HuggingFaceH4/zephyr-7b-beta).
- Un modèle de génération d'images (par exemple, stabilitéai/stable-diffusion-xl-base-1.0).
?️ Configuration du projet Spring Boot
Étape 1 : Créer un nouveau projet Spring Boot
Utilisez Spring Initializr pour configurer votre projet avec les dépendances suivantes :
- Spring WebFlux : pour les appels API réactifs et non bloquants.
- Lombok : Pour réduire le code passe-partout.
- Swagger : pour la documentation de l'API.
Étape 2 : Ajouter une configuration de visage câlin
Ajoutez votre clé API Hugging Face et vos URL de modèle au fichier application.properties :
huggingface.text.api.url=https://api-inference.huggingface.co/models/your-text-model huggingface.api.key=your-api-key-here huggingface.image.api.url=https://api-inference.huggingface.co/models/your-image-model
? Quelle est la prochaine étape ?
Plongeons dans le code et construisons les services de génération de texte et d'images. Restez à l'écoute !
1. Service de génération de texte :
@Service
public class LLMService {
private final WebClient webClient;
private static final Logger logger = LoggerFactory.getLogger(LLMService.class);
// Constructor to initialize WebClient with Hugging Face API URL and API key
public LLMService(@Value("${huggingface.text.api.url}") String apiUrl,
@Value("${huggingface.api.key}") String apiKey) {
this.webClient = WebClient.builder()
.baseUrl(apiUrl) // Set the base URL for the API
.defaultHeader("Authorization", "Bearer " + apiKey) // Add API key to the header
.build();
}
// Method to generate text using Hugging Face's Inference API
public Mono<string> generateText(String prompt) {
// Validate the input prompt
if (prompt == null || prompt.trim().isEmpty()) {
return Mono.error(new IllegalArgumentException("Prompt must not be null or empty"));
}
// Create the request body with the prompt
Map<string string> body = Collections.singletonMap("inputs", prompt);
// Make a POST request to the Hugging Face API
return webClient.post()
.bodyValue(body)
.retrieve()
.bodyToMono(String.class)
.doOnSuccess(response -> logger.info("Response received: {}", response)) // Log successful responses
.doOnError(error -> logger.error("Error during API call", error)) // Log errors
.retryWhen(Retry.backoff(3, Duration.ofMillis(500))) // Retry on failure with exponential backoff
.timeout(Duration.ofSeconds(5)) // Set a timeout for the API call
.onErrorResume(error -> Mono.just("Fallback response due to error: " + error.getMessage())); // Provide a fallback response on error
}
}
</string></string>
2. Service de génération d'images :
@Service
public class ImageGenerationService {
private static final Logger logger = LoggerFactory.getLogger(ImageGenerationService.class);
private final WebClient webClient;
public ImageGenerationService(@Value("${huggingface.image.api.url}") String apiUrl,
@Value("${huggingface.api.key}") String apiKey) {
this.webClient = WebClient.builder()
.baseUrl(apiUrl)
.defaultHeader("Authorization", "Bearer " + apiKey)
.build();
}
public Mono<byte> generateImage(String prompt) {
if (prompt == null || prompt.trim().isEmpty()) {
return Mono.error(new IllegalArgumentException("Prompt must not be null or empty"));
}
Map<string string> body = Collections.singletonMap("inputs", prompt);
return webClient.post()
.bodyValue(body)
.retrieve()
.bodyToMono(byte[].class) / Convert the response to a Mono<byte> (image bytes)
.timeout(Duration.ofSeconds(10)) // Timeout after 10 seconds
.retryWhen(Retry.backoff(3, Duration.ofMillis(500))) // Retry logic
.doOnSuccess(response -> logger.info("Image generated successfully for prompt: {}", prompt))
.doOnError(error -> logger.error("Error generating image for prompt: {}", prompt, error))
.onErrorResume(WebClientResponseException.class, ex -> {
logger.error("HTTP error during image generation: {}", ex.getMessage(), ex);
return Mono.error(new RuntimeException("Error generating image: " + ex.getMessage()));
})
.onErrorResume(TimeoutException.class, ex -> {
logger.error("Timeout while generating image for prompt: {}", prompt);
return Mono.error(new RuntimeException("Request timed out"));
});
}
}
</byte></string></byte>
Exemples d'invites et leurs résultats : ?
1. Point de terminaison basé sur du texte :
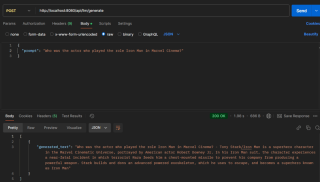
2. Point de terminaison basé sur une image :
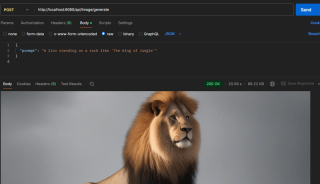
? Explorez le projet
Prêt à plonger ? Consultez le référentiel QuickAI GitHub pour voir le code complet et suivez-le. Si vous le trouvez utile, donnez-lui un ⭐.
Bonus ?
Envie d'aller plus loin dans ce projet ?
- J'ai configuré l'interface utilisateur Swagger pour la documentation de l'API qui vous aidera à créer une application frontale.
- Créez une application frontend simple en utilisant votre framework frontend préféré (comme React, Angular ou tout simplement HTML/CSS/Vanilla JS).
? Félicitations, vous êtes arrivé jusqu'ici.
Vous savez maintenant comment utiliser Hugging Face ? :
- Pour utiliser rapidement des modèles d'IA dans vos applications.
- Générer du texte : créez du contenu créatif à partir d'invites.
- Générer des images : transformez les descriptions textuelles en visuels.
? Connectons-nous !
Vous souhaitez collaborer ou avoir des suggestions, retrouvez-moi sur LinkedIn, Portfolio examine également mes autres projets ici GitHub.
Vous avez une question ou une suggestion, n'hésitez pas à commenter ci-dessous, je me ferai un plaisir d'y répondre.
Bon codage ! ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Pourquoi Java est-il un choix populaire pour développer des applications de bureau multiplateforme?Apr 25, 2025 am 12:23 AM
Pourquoi Java est-il un choix populaire pour développer des applications de bureau multiplateforme?Apr 25, 2025 am 12:23 AMJavaispopularforcross-plateformdesktopapplicationsDuetoit "writeOnce, runanywhere" philosophy.1) iTUSESBYTECODETHATrunSonanyjvm-equipppatform.2) bibliothèqueslikeswingandjavafxhelpcreenative-lookporport
 Discuter des situations où l'écriture de code spécifique à la plate-forme en Java pourrait être nécessaire.Apr 25, 2025 am 12:22 AM
Discuter des situations où l'écriture de code spécifique à la plate-forme en Java pourrait être nécessaire.Apr 25, 2025 am 12:22 AMLes raisons de l'écriture du code spécifique à la plate-forme en Java incluent l'accès à des fonctionnalités spécifiques du système d'exploitation, l'interaction avec le matériel spécifique et l'optimisation des performances. 1) Utilisez JNA ou JNI pour accéder au registre Windows; 2) interagir avec les pilotes matériels spécifiques à Linux via JNI; 3) Utilisez du métal pour optimiser les performances de jeu sur macOS via JNI. Néanmoins, la rédaction du code spécifique à la plate-forme peut affecter la portabilité du code, augmenter la complexité et potentiellement poser des risques de performances et de sécurité.
 Quelles sont les tendances futures du développement de Java qui se rapportent à l'indépendance de la plate-forme?Apr 25, 2025 am 12:12 AM
Quelles sont les tendances futures du développement de Java qui se rapportent à l'indépendance de la plate-forme?Apr 25, 2025 am 12:12 AMJava améliorera encore l'indépendance des plates-formes grâce aux applications natives dans le cloud, au déploiement multi-plate-forme et à l'interopérabilité inter-language. 1) Les applications natives Cloud utiliseront Graalvm et Quarkus pour augmenter la vitesse de démarrage. 2) Java sera étendu aux appareils intégrés, aux appareils mobiles et aux ordinateurs quantiques. 3) Grâce à GraalVM, Java s'intègre de manière transparente à des langages tels que Python et JavaScript pour améliorer l'interopérabilité transversale.
 Comment le fort typage de Java contribue-t-il à l'indépendance des plateformes?Apr 25, 2025 am 12:11 AM
Comment le fort typage de Java contribue-t-il à l'indépendance des plateformes?Apr 25, 2025 am 12:11 AMLe système dactylographié de Java assure l'indépendance de la plate-forme par la sécurité de type, la conversion de type unifié et le polymorphisme. 1) La sécurité des types effectue la vérification du type au temps de compilation pour éviter les erreurs d'exécution; 2) Les règles de conversion de type unifié sont cohérentes sur toutes les plateformes; 3) Les mécanismes de polymorphisme et d'interface font que le code se comporte de manière cohérente sur différentes plates-formes.
 Expliquez comment l'interface native Java (JNI) peut compromettre l'indépendance de la plate-forme.Apr 25, 2025 am 12:07 AM
Expliquez comment l'interface native Java (JNI) peut compromettre l'indépendance de la plate-forme.Apr 25, 2025 am 12:07 AMJNI détruira l'indépendance de la plate-forme de Java. 1) JNI nécessite des bibliothèques locales pour une plate-forme spécifique, 2) le code local doit être compilé et lié sur la plate-forme cible, 3) différentes versions du système d'exploitation ou de JVM peuvent nécessiter différentes versions de bibliothèque locale, 4) le code local peut introduire des vulnérabilités de sécurité ou provoquer des accidents de programme.
 Y a-t-il des technologies émergentes qui menacent ou améliorent l'indépendance de la plate-forme de Java?Apr 24, 2025 am 12:11 AM
Y a-t-il des technologies émergentes qui menacent ou améliorent l'indépendance de la plate-forme de Java?Apr 24, 2025 am 12:11 AMLes technologies émergentes représentent à la fois des menaces et améliorent l'indépendance de la plate-forme de Java. 1) Les technologies de cloud computing et de contenerisation telles que Docker améliorent l'indépendance de la plate-forme de Java, mais doivent être optimisées pour s'adapter à différents environnements cloud. 2) WebAssembly compile le code Java via GRAALVM, prolongeant son indépendance de la plate-forme, mais il doit rivaliser avec d'autres langues pour les performances.
 Quelles sont les différentes implémentations du JVM et fournissent-elles toutes le même niveau d'indépendance de la plate-forme?Apr 24, 2025 am 12:10 AM
Quelles sont les différentes implémentations du JVM et fournissent-elles toutes le même niveau d'indépendance de la plate-forme?Apr 24, 2025 am 12:10 AMDifférentes implémentations JVM peuvent fournir une indépendance de la plate-forme, mais leurs performances sont légèrement différentes. 1. Oraclehotspot et OpenJDKJVM fonctionnent de manière similaire dans l'indépendance de la plate-forme, mais OpenJDK peut nécessiter une configuration supplémentaire. 2. IBMJ9JVM effectue une optimisation sur des systèmes d'exploitation spécifiques. 3. GRAALVM prend en charge plusieurs langues et nécessite une configuration supplémentaire. 4. AzulzingJVM nécessite des ajustements de plate-forme spécifiques.
 Comment l'indépendance des plateformes réduit-elle les coûts et le temps de développement?Apr 24, 2025 am 12:08 AM
Comment l'indépendance des plateformes réduit-elle les coûts et le temps de développement?Apr 24, 2025 am 12:08 AML'indépendance de la plate-forme réduit les coûts de développement et réduit le temps de développement en exécutant le même ensemble de code sur plusieurs systèmes d'exploitation. Plus précisément, il se manifeste comme suit: 1. Réduire le temps de développement, un seul ensemble de code est requis; 2. Réduire les coûts de maintenance et unifier le processus de test; 3. I itération rapide et collaboration d'équipe pour simplifier le processus de déploiement.


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

PhpStorm version Mac
Le dernier (2018.2.1) outil de développement intégré PHP professionnel

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Version Mac de WebStorm
Outils de développement JavaScript utiles

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

Version crackée d'EditPlus en chinois
Petite taille, coloration syntaxique, ne prend pas en charge la fonction d'invite de code

