
Maison >développement back-end >tutoriel php >Exploiter OpenAI Assistant pour la reconnaissance d'entités nommées dans PHP/Symfony 7
Exploiter OpenAI Assistant pour la reconnaissance d'entités nommées dans PHP/Symfony 7

- Patricia Arquetteoriginal
- 2024-12-26 02:44:13879parcourir
L'intégration de grands modèles de langage dans les backends de produits réels est le dernier champ de bataille en matière d'innovation. Mais comme pour toutes les tendances technologiques, les vrais gagnants ne sont pas ceux qui se précipitent pour tout savoir. Il s'agit plutôt de faire une pause, de réfléchir et de prendre des décisions intelligentes.
Même si l’IA est plus accessible que jamais, penser qu’il s’agit d’une tâche triviale est une grave erreur. Le domaine en est encore à ses balbutiements, et presque tous les acteurs de la technologie et des affaires tentent de trouver comment lui donner un sens. Internet regorge à la fois d’informations fiables et de battage médiatique trompeur.
Croyez-le ou non, vous n’avez pas besoin de sauter sur chaque potin que vous entendez sur l’IA. Prenez du recul et abordez-le de manière réfléchie.
Si vous êtes un développeur PHP ou si vous travaillez avec une base de code PHP, l'IA peut ressembler à un concept extraterrestre. Les classes, les interfaces, les files d'attente de messages et les frameworks semblent être des mondes différents de la PNL, du réglage fin, des descentes de gradient stochastiques, de LoRA, de RAG et de tout ce jargon. Je comprends. Pour apprendre systématiquement ces concepts, comme tout en génie logiciel, nous avons besoin de temps et de bonnes pratiques.
Mais l’IA, l’apprentissage automatique et la science des données ne sont-ils pas le domaine des programmeurs Python ou R ? Vous avez en partie raison. La plupart des apprentissages automatiques fondamentaux sont effectués en Python. Et honnêtement, Python est un plaisir à apprendre : il est polyvalent et peut être appliqué à d’innombrables projets intéressants. De la création et de la formation d'un modèle de langage à son déploiement via une API, Python a ce qu'il vous faut.
Mais revenons à PHP.
Ne vous inquiétez pas, vous n'êtes pas sur le point de devenir obsolète en tant qu'ingénieur logiciel ordinaire. Bien au contraire. Alors que nous sommes de plus en plus censés comprendre des domaines connexes tels que la conteneurisation, le CI/CD, l’ingénierie des systèmes et l’infrastructure cloud, l’IA devient rapidement une autre compétence essentielle de notre boîte à outils. Il n’y a pas de meilleur moment que maintenant pour commencer à apprendre.
Cela dit, je ne recommande pas de se lancer tête première dans la création de réseaux de neurones à partir de zéro (sauf si vous le souhaitez vraiment). Il est facile de se sentir dépassé. Au lieu de cela, laissez-moi vous montrer un point de départ pratique pour vos expériences d'IA.
À quoi pouvez-vous vous attendre ?
Voici ce que nous aborderons dans ce guide :
Flux de travail IA asynchrones
Je vais vous montrer comment mettre en œuvre un flux de travail d'IA à l'aide d'une file d'attente de messages, qu'il s'agisse de RabbitMQ, d'Amazon SQS ou de votre courtier préféré.
Solution prête pour la production
Vous verrez un exemple réel de solution déployée dans un système de production qui répond aux exigences commerciales de base avec l'IA
Intégration Symfony
La solution est entièrement implémentée dans le framework Symfony PHP.
Outils OpenAI
Nous utiliserons la bibliothèque OpenAI PHP et les derniers OpenAI Assistants 2.0.
Quels sujets allons-nous aborder ?
Structure de l'ensemble de données
Comment créer un ensemble de données pour entraîner et évaluer votre modèle d'IA.Affiner les modèles OpenAI
Apprenez à préparer un fichier .jsonl approprié et à affiner le modèle GPT-4o-mini ou un autre de la famille GPT pour votre cas d'utilisation professionnel spécifique.Création et test d'un assistant OpenAI 2.0
Comprenez comment configurer un assistant OpenAI et testez-le dans OpenAI Playground.Bases de connaissances
Plongez dans le concept de bases de connaissances : pourquoi GPT ne sait pas tout et comment lui fournir le bon contexte pour augmenter considérablement la précision.Intégration PHP et Symfony
Apprenez à connecter de manière transparente votre agent IA à votre application Symfony.
Intéressé ? Allons-y.
Conditions préalables pour les projets OpenAI PHP
- Compte OpenAI Vous aurez besoin d’un compte sur openai.com.
- Facultatif : compte de pondérations et de biais La création d'un compte sur wandb.ai est facultative mais fortement recommandée. C'est un excellent outil pour suivre les expériences d'IA et visualiser les résultats.
Définir le problème
Plongeons dans le problème que nous résolvons.
À la base, nous avons affaire à un bloc de texte qui représente quelque chose – une adresse, dans notre cas. Le but est de classer ses composants en groupes prédéfinis.
Ainsi, lorsqu'un utilisateur nous envoie une adresse, nous visons à renvoyer une structure JSON qui segmente l'adresse en ses parties. Par exemple :
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
Pourquoi est-ce important ?
Eh bien, ces adresses sont saisies par des personnes – nos clients – et elles sont souvent incohérentes. Voici pourquoi nous avons besoin de données structurées et analysées :
- Formatage cohérent Garantit que les adresses suivent un format standard pour un traitement transparent.
- Validation de l'adresse (facultatif) Permet de vérifier si l'adresse est valide ou existe.
Pour y parvenir, nous disséquons l'adresse en groupes prédéfinis comme « rue », « maison », « code postal », etc., puis nous la réassemblons dans l'ordre souhaité.
Pourquoi ne pas utiliser des expressions régulières ?
À première vue, cela semble simple. Si nous imposons le formatage aux nouveaux clients ou si nous savons qu'ils écrivent généralement les adresses d'une manière spécifique, les expressions régulières peuvent sembler une solution raisonnable.
Cependant, considérons des exemples d'adresses roumaines :
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
Les adresses roumaines sont souvent complexes, écrites sans ordre particulier et omettent fréquemment des éléments comme le code postal. Même les expressions régulières les plus sophistiquées ont du mal à gérer une telle variabilité de manière fiable.
C'est là que brillent les modèles d'IA comme GPT-3.5 Turbo ou GPT-4o-mini : ils peuvent gérer les incohérences et les complexités bien au-delà de ce que les règles statiques comme les regex peuvent gérer.
Un flux de travail d'IA plus intelligent
Oui, nous développons un flux de travail d'IA qui améliore considérablement l'approche traditionnelle.
Chaque projet de machine learning se résume à deux éléments essentiels : les données et le modèle. Et même si les modèles sont importants, les données sont bien plus critiques.
Les modèles sont préemballés, testés et peuvent être échangés pour voir lequel est le plus performant. Mais ce qui change vraiment la donne, c'est la qualité des données que nous fournissons au modèle.
Le rôle des données dans l'apprentissage automatique
En règle générale, nous divisons notre ensemble de données en deux ou trois parties :
- Données d'entraînement : Utilisées pour enseigner au modèle ce qu'il doit faire.
- Données de test : Utilisées pour évaluer les performances du modèle.
Pour ce projet, nous souhaitons diviser une adresse en ses composants, ce qui en fait une tâche de classification. Pour obtenir de bons résultats avec un grand modèle de langage (LLM) comme GPT, nous avons besoin d'au moins 100 exemples dans notre ensemble de données de formation.
Structurer l'ensemble de données
Le format brut de notre ensemble de données n'a pas beaucoup d'importance, mais j'ai choisi une structure intuitive et facile à utiliser :
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
Voici un exemple :
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
Comme vous pouvez le voir, l'objectif est de produire une réponse JSON structurée basée sur l'adresse d'entrée.
Configuration de votre compte API OpenAI
Tout d’abord, vous aurez besoin d’un compte API OpenAI. C'est un processus simple et je recommande d'ajouter quelques fonds initiaux : 10 $ ou 20 $ suffisent pour commencer. OpenAI utilise un modèle d'abonnement prépayé pratique, vous aurez donc un contrôle total sur vos dépenses.
Vous pouvez gérer la facturation de votre compte ici :

Explorer le terrain de jeu OpenAI
Une fois votre compte configuré, rendez-vous sur OpenAI Playground.
Prenez un moment pour vous familiariser avec l'interface. Lorsque vous êtes prêt, recherchez la section « Assistants » dans le menu de gauche.
C'est ici que nous allons créer notre instance GPT personnalisée.
Personnalisation de votre assistant GPT
Nous adapterons notre assistant GPT pour répondre à nos besoins spécifiques en deux étapes :
Instructions système détaillées avec exemples
Cette étape nous aide à tester et valider rapidement si la solution fonctionne. C'est le moyen le plus rapide d'obtenir des résultats.Réglage fin avec la base de connaissances (simple RAG)
Une fois que nous serons satisfaits des premiers résultats, nous affinerons le modèle. Ce processus réduit le besoin de fournir des exemples détaillés dans chaque invite, ce qui, à son tour, diminue le temps d'inférence (le temps nécessaire au modèle pour répondre via l'API).
Les deux étapes combinées nous donnent les résultats les plus précis et les plus efficaces.
Alors, commençons.
Conception d'une invite système pour la reconnaissance d'entités nommées
Pour notre système de reconnaissance d'entités nommées, nous avons besoin que le modèle génère des réponses JSON structurées de manière cohérente. Pour y parvenir, il est essentiel de créer une invite système réfléchie.
Voici ce sur quoi nous allons nous concentrer :
- Structurer l'invite initiale du système « sale » pour produire des résultats clairs.
- Affiner l'invite plus tard pour améliorer l'efficacité et minimiser les coûts.
Commencer par la technique de quelques coups
La technique des « quelques coups » est une approche puissante pour cette tâche. Il fonctionne en fournissant au modèle quelques exemples de la relation entrée-sortie souhaitée. À partir de ces exemples, le modèle peut généraliser et gérer des entrées qu’il n’a jamais vues auparavant.
Éléments clés d'une invite de quelques prises de vue :
L'invite se compose de plusieurs parties, qui doivent être soigneusement structurées pour de meilleurs résultats. Bien que l'ordre exact puisse varier, il est essentiel d'inclure les sections suivantes :
1. Objectif clair
La première partie de l'invite fournit un aperçu général de ce que nous attendons du modèle.
Par exemple, dans ce cas d'utilisation, l'entrée est une adresse roumaine, qui peut inclure des fautes d'orthographe et un formatage incorrect. Ce contexte est essentiel car il prépare le terrain pour le modèle, expliquant le type de données qu'il traitera.

2. Instructions de formatage
Après avoir défini la tâche, nous guidons l'IA sur la façon de formater sa sortie.
Ici, la structure JSON est expliquée en détail, y compris la manière dont le modèle doit dériver chaque paire clé-valeur de l'entrée. Des exemples sont inclus pour clarifier les attentes. De plus, tous les caractères spéciaux sont correctement échappés pour garantir un JSON valide.

3. Exemples
Les exemples sont l'épine dorsale de la technique des « quelques coups ». Plus nous fournissons des exemples pertinents, meilleures sont les performances du modèle.
Grâce à la vaste fenêtre contextuelle de GPT (jusqu'à 16 000 jetons), nous pouvons inclure un grand nombre d'exemples.
Pour créer l'ensemble d'exemples :
Commencez avec une invite de base et évaluez manuellement la sortie du modèle.
Si le résultat contient des erreurs, corrigez-les et ajoutez la version corrigée à l'ensemble d'exemples.
Ce processus itératif améliore les performances de l’assistant au fil du temps.

4. Informations correctives
C'est inévitable : votre assistant fera des erreurs. Parfois, il peut répéter la même erreur.
Pour résoudre ce problème, incluez des informations correctives claires et polies dans votre invite. Expliquez clairement :
Quelles erreurs l'assistant fait.
Ce que vous attendez plutôt du résultat.
Ces commentaires aident le modèle à ajuster son comportement et à générer de meilleurs résultats.

Configuration et test de votre assistant
Maintenant que nous avons élaboré l'invite initiale de notre solution de validation de principe en quelques étapes, il est temps de configurer et de tester l'Assistant.
Étape 1
- Rendez-vous sur le tableau de bord OpenAI
- Dans le menu de gauche, sélectionnez « Assistants »
- Vous serez redirigé vers la page de création de l'Assistant. Revenez au tableau de bord OpenAI et dans le menu de gauche, choisissez « Assistants ». Vous serez redirigé vers l'assistant créateur.
Étape 2 : Configurez votre assistant
- Donnez un nom à votre assistant : choisissez un nom descriptif pour votre assistant qui reflète son objectif (par exemple, « Analyseur d'adresses »).
- Collez les instructions système : copiez l'intégralité de votre invite spécialement conçue et collez-la dans la zone de saisie des instructions système. Cela définit le comportement de votre Assistant et guide ses résultats.
- Enregistrez votre assistant : une fois que vous avez collé l'invite, cliquez sur Enregistrer pour stocker la configuration.
Étape 3 : Choisissez le bon modèle
Pour ce projet, j'ai choisi GPT-4o-mini car :
- C'est moins cher que GPT-3.5 Turbo
- C'est plus précis :)
Cela dit, vous devez toujours sélectionner votre modèle en fonction d'un équilibre entre précision et coût. Exécutez ou recherchez des références pour déterminer ce qui fonctionne le mieux pour votre tâche spécifique.

Définir le schéma de sortie
Une fois la configuration initiale en place, nous pouvons désormais spécifier le schéma de sortie directement dans l'Assistant créateur.
Étape 1 : Utilisation de l'option « Générer »
Au lieu de créer le schéma manuellement, j'ai utilisé l'option "Générer" fournie par l'Assistant créateur. Voici comment :
- Prenez la structure de sortie JSON de votre invite (à partir de l'un des exemples)
- Collez-le dans le champ "Générer".
L'outil fait un excellent travail en générant automatiquement un schéma qui correspond à votre structure.

--
Pour garantir des réponses cohérentes et prévisibles, réglez la température aussi basse que possible.

Qu'est-ce que la température ?
La température contrôle le caractère aléatoire des réponses du modèle. Une valeur de température faible signifie que le modèle produit des sorties plus prévisibles et déterministes.
Pour notre cas d'utilisation, c'est exactement ce que nous voulons. Lorsqu’on lui donne la même adresse en entrée, le modèle doit toujours renvoyer la même réponse correcte. La cohérence est la clé pour des résultats fiables.
Tester l'assistant
Une fois tous les paramètres en place, rendez-vous sur le Playground pour tester votre solution.
Le Playground fournit une console sur laquelle vous pouvez faire travailler votre Assistant. C'est là que le plaisir commence : vous pouvez tester rigoureusement votre solution simple pour découvrir :
- Là où le modèle hallucine (générant des informations non pertinentes ou incorrectes).
- Lacunes potentielles dans votre invite ou votre schéma.
Ces résultats vous aideront à affiner la section Informations correctives de votre invite, rendant ainsi votre Assistant plus robuste.
Vous trouverez ci-dessous un exemple de résultat d'un de mes tests manuels :
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
Pourquoi les tests manuels sont-ils importants ?
Les tests pratiques à l’ancienne constituent la base de la création d’une solution fiable. En évaluant manuellement les sorties du modèle, vous repérerez rapidement les problèmes et comprendrez comment les résoudre. Même si l'automatisation viendra plus tard, les tests manuels constituent une étape inestimable dans la création d'une preuve de concept solide.
Brancher l'assistant sur votre application PHP Symfony
Il est maintenant temps de tout intégrer dans votre application PHP Symfony. La configuration est simple et suit une architecture asynchrone classique.

Voici une répartition du flux :
1.Interaction frontale
En général, ce que nous avons ici est une configuration asynchrone classique avec file d'attente de messages. Nous avons 2 instances de l'application Symfony exécutées dans le conteneur Docker. Le premier consiste à interagir avec le client frontend.
Par exemple, lorsqu'un client tape :
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
L'application traite l'adresse d'entrée et la conditionne dans un objet Message.
L'objet Message est ensuite enveloppé dans une instance Symfony Messenger Envelope. Le message est sérialisé au format JSON, avec des métadonnées supplémentaires pour le traitement.
Symfony Messenger est parfait pour gérer les tâches asynchrones. Cela nous permet de décharger les opérations fastidieuses, comme l'appel de l'API OpenAI, vers des processus en arrière-plan.
Cette approche garantit :
- Réactivité : Le frontend reste rapide et réactif.
- Évolutivité : Les tâches peuvent être réparties entre plusieurs travailleurs.
Vous trouverez ci-dessous la classe de message utilisée pour notre système :
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
L'application se connecte à une instance RabbitMQ à l'aide de l'extension PHP amqp. Pour configurer cela, vous devez définir la liaison de transport et de message dans votre fichier de configuration Messenger.yaml.
Référez-vous à la documentation officielle de Symfony Messenger pour des conseils détaillés :
Configuration du transport Symfony Messenger
Documentation : https://symfony.com/doc/current/messenger.html#transport-configuration
Une fois le message transmis au courtier (par exemple, RabbitMQ, AmazonMQ ou AWS SQS), il est récupéré par la deuxième instance de l'application. Cette instance exécute le démon Messenger pour consommer les messages, comme indiqué 3 dans le schéma d'architecture.
Le processus de consommation est géré en exécutant :
bin/console messager:consommer
fonctionne comme c'est le processus.
Le démon récupère le message de la file d'attente configurée, le désérialise dans la classe Message correspondante et le transmet au gestionnaire de messages pour traitement.
Voici le Gestionnaire de messages où se produit l'interaction avec l'assistant OpenAI :
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
Points clés du gestionnaire
Journalisation
Enregistre le début du traitement pour la traçabilité et le débogage.
Service de normalisationL'OpenAIAddressNormalizationService est appelé pour traiter l'adresse d'entrée via l'Assistant.
Persistance
L'adresse normalisée est enregistrée dans la base de données à l'aide d'EntityManager de Doctrine.
Le gestionnaire de messages peut ressembler à du code Symfony standard, mais le noyau se trouve dans cette ligne :
INPUT: <what goes into the LLM> OUTPUT: <what the LLM should produce>
Ce service est chargé d'interagir avec OpenAI via la bibliothèque PHP désignée.
Client PHP OpenAI
Plongeons dans la mise en œuvre du service avec l'utilisation du client PHP.
Voici l’implémentation complète d’OpenAIAddressNormalizationService :
input: STRADA EREMIA GRIGORESCU, NR.11 BL.45B,SC.B NR 11/38, 107065 PLOIESTI
output: {{"street": "Eremia Grigorescu", "house_number": "11", "flat_number": "38", "block": "45B", "staircase": "45B", floor: "", "apartment": "", "landmark": "", "postcode": "107065", "county": "Prahova", 'commune': '', 'village': '', "city" "Ploiesti"}}
Le workflow pour obtenir une inférence (ou un achèvement) (essentiellement la réponse de GPT) à l'aide de la bibliothèque openai-php/client suit trois étapes principales :
1. Initialisation du client OpenAI et récupération de l'assistant
La première étape consiste à configurer le client OpenAI et à récupérer l'Assistant configuré :
INPUT: BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
OUTPUT:
{
"street": "Bdul 21 Decembrie 1989",
"house": "93",
"flat": "50",
"block": "",
"staircase": "",
"floor": "",
"apartment": "",
"landmark": "",
"intercom": "",
"postcode": "400124",
"county": "Cluj",
"commune": "",
"village": "",
"city": "Cluj"
}
Initialisation du client : La méthode OpenAI::client() crée un nouveau client à l'aide de votre clé API et de votre identifiant d'organisation.
Récupération de l'Assistant : La méthode retrieve() se connecte à l'instance spécifique de l'Assistant configurée pour votre tâche, identifiée par son ID unique.
1. Créer et exécuter un fil de discussion
Une fois le client et l'Assistant initialisés, vous pouvez créer et exécuter un fil de discussion pour commencer l'interaction. Un fil de discussion agit comme un pipeline de communication, gérant l'échange de messages entre l'utilisateur et l'Assistant.
Voici comment le fil de discussion est lancé :
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
- ID de l'assistant : l'ID de l'assistant détermine quelle instance de modèle traitera l'entrée.
- Messages : Chaque fil de discussion comprend une séquence de messages. Dans ce cas, le message a un rôle qui indique si le message provient de l'utilisateur (entrée) ou du système (réponse). Et le second est Contenu - contient le texte saisi (par exemple, une adresse).
3. Gestion de la réponse du thread
Après avoir lancé le fil de discussion, l'application gère la réponse. Étant donné que les processus OpenAI peuvent ne pas se terminer instantanément, vous devez interroger l'état du fil jusqu'à ce qu'il soit marqué comme « terminé » :
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
Interrogation : L'application vérifie à plusieurs reprises l'état du fil de discussion (en file d'attente ou en cours). Une fois que le statut passe à « terminé », le thread contient la sortie finale.
Une fois le fil de discussion terminé, l'application récupère les messages de réponse pour en extraire l'adresse normalisée :
INPUT: <what goes into the LLM> OUTPUT: <what the LLM should produce>
L'adresse normalisée peut désormais être renvoyée au client frontal pour une utilisation immédiate ou stockée dans la base de données en tant qu'entité structurée, comme CustomerAddressNormalized, pour un traitement ultérieur.
Lorsque vous exécutez cette configuration, vous devriez pouvoir extraire et enregistrer la sortie structurée d'OpenAI pour la reconnaissance d'entités nommées et d'autres tâches de classification ou de génération.
Rendre l'Assistant flamboyant précis grâce au réglage fin et à la base de connaissances (génération augmentée de récupération)
Dans certains cas, les solutions d’IA de base ne suffisent pas. Lorsque la conformité réglementaire et les exigences commerciales exigent une grande précision, nous devons faire un effort supplémentaire pour garantir que les résultats sont factuels et fiables.
Par exemple, lors de la génération d'une structure JSON, nous devons garantir que son contenu correspond à la réalité. Un risque courant est celui du modèle hallucinant l’information – comme inventer un lieu basé sur un code postal fourni. Cela peut entraîner de graves problèmes, en particulier dans les environnements à enjeux élevés.
Vérité fondamentale avec base de connaissances
Pour éliminer les hallucinations et garantir l'exactitude des faits, nous devons fournir à l'Assistant une base de connaissances sur la vérité terrain. Cela sert de référence définitive pour le modèle, garantissant qu'il utilise des informations précises lors de l'inférence.
Mon approche : une base de connaissances sur les codes postaux
J'ai créé un fichier JSON simple (mais assez volumineux, environ 12 Mo) contenant la démarcation complète de tous les codes postaux en Roumanie. Cette structure de type dictionnaire fournit :
Code postal : La valeur d'entrée.
Informations validées : Des faits tels que la ville, le comté et le nom général du lieu correspondant.
Cette base de connaissances sert de point de référence à l'assistant lors de la reconnaissance d'entités nommées.
Structure de la base de connaissances
Voici un exemple d'extrait de la structure JSON de la base de connaissances :
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
Une fois la base de connaissances prête, il est temps de demander à l'Assistant de l'utiliser efficacement. Bien que vous puissiez l'intégrer directement dans l'invite, cette approche augmente l'utilisation et les coûts des jetons. C’est donc un excellent moment pour introduire le réglage précis.
Qu’est-ce que le réglage fin ?
Le réglage fin consiste à modifier les couches les plus externes (en particulier les matrices de poids) d'un modèle pré-entraîné, en l'adaptant à une tâche spécifique. Dans notre cas, la reconnaissance d'entités nommées (NER) est un candidat parfait.
Un modèle affiné :
- Nécessite des invites plus petites : Réduit le besoin d'instructions longues ou d'exemples intégrés.
- Réduit les coûts : Des invites plus courtes et moins d'exemples réduisent la consommation de jetons.
- Améliore le temps d'inférence : Des réponses plus rapides signifient de meilleures performances en temps réel.
L'objectif principal est d'aligner plus étroitement le modèle sur les nuances des données du monde réel qu'il traitera. La formation sur des données spécifiques à un domaine permet au modèle de mieux comprendre et de générer des réponses appropriées. Cela réduit également le besoin de post-traitement ou de correction d'erreurs par l'application.
Préparation de l'ensemble de données de réglage fin
Pour affiner le modèle, nous avons besoin d'un ensemble de données correctement formaté au format .jsonl (JSON Lines), comme l'exige OpenAI. Chaque entrée de l'ensemble de données comprend :
- Invite système : L'instruction initiale pour l'Assistant.
- Entrée utilisateur : Les données d'entrée brutes (par exemple, une adresse désordonnée).
- Résultat attendu : La réponse structurée souhaitée.
Cet ensemble de données fournit à l'Assistant des exemples spécifiques à un domaine, lui permettant d'apprendre comment répondre à des invites similaires à l'avenir.
Voici un exemple de la façon de structurer une entrée de réglage fin :
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
Décomposons la structure d'une entrée de réglage fin dans le fichier .jsonl, en utilisant notre cas de traitement d'adresse roumain comme exemple :

Chaque entrée est conçue pour simuler une véritable interaction entre l'utilisateur et l'Assistant, encapsulant :
- Le but et la portée de l’Assistant.
- Le scénario de saisie de l'utilisateur.
- La sortie structurée attendue.
Cette approche aide le modèle à apprendre le comportement souhaité dans des contextes du monde réel.
1. Message de rôle système
Décrit les capacités de l'assistant et l'étendue de ses fonctionnalités, en définissant les attentes concernant les types d'entités qu'il doit reconnaître et extraire, telles que les noms de rue, les numéros de maison et les codes postaux.
Exemple : le système explique que l'assistant est conçu pour fonctionner comme un modèle de reconnaissance d'entités nommées pour les adresses roumaines, détaillant les composants qu'il doit extraire et classer.
2. Message sur le rôle de l'utilisateur
- Fournit un scénario ou une requête détaillé dans lequel l'utilisateur saisit une adresse spécifique. Cette partie de la saisie des données est cruciale car elle influence directement la façon dont le modèle apprendra à répondre à des entrées similaires dans des paramètres opérationnels.
3. Message sur le rôle d'assistant
- Contient la réponse attendue de l'assistant, formatée en JSON. Cette réponse est cruciale car elle entraîne le modèle sur le format de sortie et la précision souhaités.
Création d'un fichier de validation pour un réglage fin
Une fois le dossier de formation créé, l’étape suivante consiste à préparer un dossier de validation. Ce fichier évalue la précision de l'Assistant affiné sur des données réelles. La structure est similaire à celle du fichier de formation, ce qui rend l'automatisation de la création des deux fichiers plus simple.
Le fichier de validation est conçu pour tester les capacités de généralisation du modèle. Cela garantit que l'Assistant optimisé peut gérer de nouvelles entrées et fonctionner de manière cohérente, même lorsqu'il est confronté à des exemples peu familiers ou difficiles.
Structure du dossier de validation

Message système :
Pour maintenir la cohérence avec le processus de formation, le message système doit être identique à celui utilisé dans le fichier de formation.
Message de l'utilisateur :
Introduit une nouvelle entrée (par exemple, une adresse) qui n'était pas incluse dans le fichier de formation. Le nouvel exemple doit être réaliste et spécifique à un domaine, et remettre en question le modèle en incluant des erreurs ou des complexités mineures.
Message de l'assistant :
Fournit la réponse structurée attendue pour la nouvelle entrée utilisateur.
Cela sert de référence pour valider l’exactitude du modèle.
Pour rationaliser la création de fichiers de formation et de validation, des scripts d'automatisation peuvent être utilisés. Ces scripts génèrent des fichiers .jsonl correctement formatés en fonction des ensembles de données d'entrée.
Visitez le référentiel contenant les scripts pour générer les fichiers de formation et de validation :
Scripts de génération .jsonl automatisés
C'est une version Python de l'automatisation de réglage fin. La version PHP arrive bientôt.
Pourquoi la validation est importante ?
- Tests de précision : Mesure les performances du modèle affiné sur des données invisibles.
- Généralisation : Valide la capacité du modèle à gérer des entrées nouvelles, complexes ou sujettes aux erreurs.
- Boucle de rétroaction : Aide à identifier les domaines dans lesquels des réglages ou des données supplémentaires sont nécessaires.
Ajuster manuellement votre assistant
Si vous préférez, vous pouvez affiner l'Assistant manuellement à l'aide de l'interface utilisateur graphique (GUI) d'OpenAI. Une fois que vous avez préparé les dossiers de formation et de validation, suivez ces étapes pour commencer :
Étape 1 : Accédez à l'assistant de réglage fin
- Allez sur le tableau de bord et cliquez sur « Réglage fin » dans le menu de gauche.
- Cliquez sur le bouton vert "Créer" pour ouvrir le menu de réglage fin.
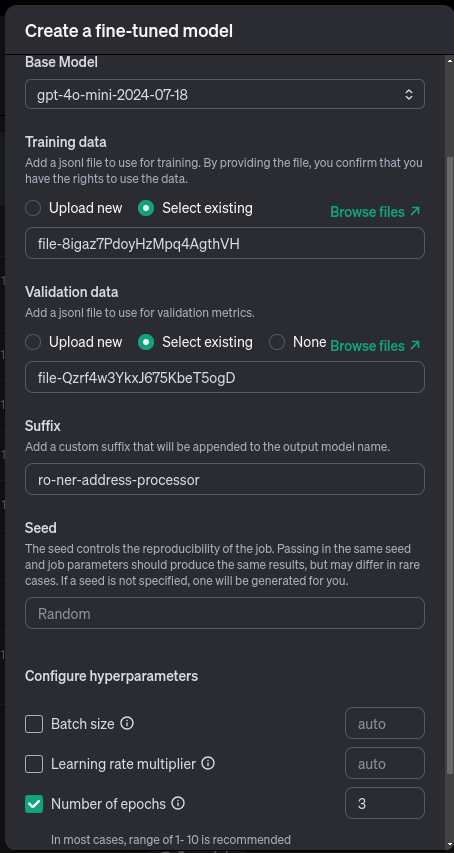
Étape 2 : Configurer le réglage fin
Dans le menu de réglage fin, mettez à jour les paramètres suivants :
- Modèle de base : au moment de la rédaction, le modèle de base le plus rentable et le plus performant est le gpt-4o-mini-2024-07-18. Choisissez le modèle de base qui correspond le mieux à vos exigences en matière de performances et de budget.
- Données de formation et de validation - Téléchargez les données de formation et les fichiers de données de validation que vous avez créés précédemment.
- Nombre d'époques - Définissez le nombre d'époques (itérations du processus de formation sur l'ensemble de l'ensemble de données). Je recommande de commencer par 3 époques, mais vous pouvez expérimenter plus d'époques si votre budget le permet.
Étape 3 : Surveiller le processus de réglage fin
Une fois le processus de réglage fin lancé, vous pouvez suivre sa progression dans le tableau de bord de réglage fin :

Le tableau de bord fournit des mises à jour en temps réel et affiche plusieurs mesures pour vous aider à surveiller et évaluer le processus de formation.
Mesures clés à comprendre
Perte d'entraînement Mesure dans quelle mesure le modèle s'adapte aux données d'entraînement. Une perte de formation inférieure indique que le modèle apprend efficacement des modèles au sein de l'ensemble de données.
Perte de validation complète Indique les performances sur les données invisibles de l'ensemble de données de validation. Une perte de validation plus faible suggère que le modèle se généralisera bien à de nouvelles entrées.
Étapes et temps Les étapes de formation sont un nombre d'itérations où les poids du modèle sont mis à jour en fonction de lots de données.
L'horodatage indique quand chaque étape a été traitée, ce qui permet de surveiller la durée de l'entraînement et les intervalles entre les évaluations.
Interprétation des métriques
La surveillance des métriques ci-dessous vous aide à déterminer si le processus de réglage fin converge correctement ou nécessite des ajustements.
- Perte décroissante : les pertes de formation et de validation devraient idéalement diminuer avec le temps, pour finalement se stabiliser. Surapprentissage : Se produit lorsque la perte d'entraînement continue de diminuer tandis que la perte de validation commence à augmenter ou à fluctuer. Cela indique que le modèle est surspécialisé pour les données d'entraînement et fonctionne mal sur les données invisibles.
Sous-ajustement : Se produit lorsque les deux pertes restent élevées, ce qui montre que le modèle n'apprend pas efficacement.
Branchez le modèle et évaluez
Une fois votre Assistant formé et affiné, il est temps de l'intégrer à votre application et de commencer à évaluer ses performances.
Commencez simplement.
Commencez par des tests manuels, soit dans Assistants Playground, soit directement dans votre application. Évitez de trop compliquer votre évaluation à ce stade ; concentrez-vous sur le fait que les bases fonctionnent comme prévu.
Par exemple, vous pouvez utiliser un outil simple comme Google Sheets pour comparer manuellement l'entrée et la sortie, comme indiqué ici :

C'est la première étape.
Les solutions d'IA et de ML nécessitent une évaluation continue pour garantir que les performances restent cohérentes. Pour des tâches telles que la reconnaissance d'entités nommées, des outils automatisés tels que l'extension PromptFlow pour Visual Studio Code peuvent aider à rationaliser les tests et la validation.
Références
Documentation de réglage fin d'OpenAI
Documentation Symfony Messenger
Bibliothèque cliente OpenAI PHP
Extension PromptFlow pour VS Code
Merci !
Merci d'avoir pris le temps d'explorer ce guide ! J'espère qu'il vous fournira une base solide pour créer et affiner vos solutions basées sur l'IA. Si vous avez des questions ou des suggestions, n'hésitez pas à nous contacter ou à laisser un commentaire.
Bon codage et bonne chance avec vos projets d'IA ! ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)