


Aperçu
J'ai écrit un script Python qui traduit la logique métier d'extraction de données PDF en code fonctionnel.
Le script a été testé sur 71 pages de fichiers PDF de déclaration de dépositaire couvrant une période de 10 mois (de janvier à octobre 2024). Le traitement des fichiers PDF a pris environ 4 secondes, soit beaucoup plus rapidement que de le faire manuellement.

D'après ce que je vois, le résultat semble correct et le code n'a rencontré aucune erreur.
Des instantanés des trois sorties CSV sont présentés ci-dessous. Notez que les données sensibles ont été grisées.
Aperçu 1 : avoirs en actions
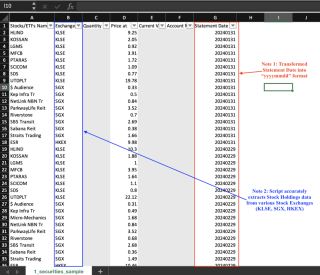
Aperçu 2 : avoirs du fonds

Aperçu 3 : Avoirs en espèces

Ce flux de travail montre les grandes étapes que j'ai suivies pour générer les fichiers CSV.
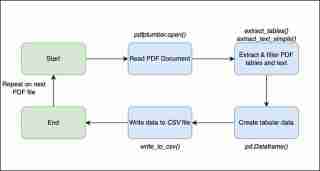
Maintenant, je vais expliquer plus en détail comment j'ai traduit la logique métier en code en Python.
Étape 1 : Lire les documents PDF
J'ai utilisé la fonction open() de pdfplomber.
# Open the PDF file with pdfplumber.open(file_path) as pdf:
file_path est une variable déclarée qui indique à pdfplombier quel fichier ouvrir.
Étape 2.0 : Extraire et filtrer les tableaux de chaque page
La fonction extract_tables() effectue le gros travail d'extraction de toutes les tables de chaque page.
Bien que je ne sois pas vraiment familier avec la logique sous-jacente, je pense que la fonction a fait du plutôt bon travail. Par exemple, les deux instantanés ci-dessous montrent le tableau extrait par rapport à l'original (du PDF)
Instantané A : sortie du terminal VS Code

Instantané B : Tableau en PDF

J'ai ensuite dû étiqueter de manière unique chaque table, afin de pouvoir "sélectionner" des données dans des tables spécifiques plus tard.
L'option idéale était d'utiliser le titre de chaque tableau. Cependant, déterminer les coordonnées du titre dépassait mes capacités.
Pour contourner le problème, j'ai identifié chaque table en concaténant les en-têtes des trois premières colonnes. Par exemple, le tableau Stock Holdings dans Snapshot B est intitulé Stocks/ETFsnNameExchangeQuantity.
⚠️Cette approche présente un sérieux inconvénient : les trois premiers noms d'en-tête ne rendent pas toutes les tables suffisamment uniques. Heureusement, cela n'impacte que les tables non pertinentes.
Étape 2.1 : Extraire, filtrer et transformer le texte autre qu'un tableau
Les valeurs spécifiques dont j'avais besoin - Numéro de compte et Date du relevé - étaient des sous-chaînes dans la page 1 de chaque PDF.
Par exemple, « Numéro de compte M1234567 » contient le numéro de compte « M1234567 ».

J'ai utilisé la bibliothèque re de Python et j'ai demandé à ChatGPT de suggérer des expressions régulières appropriées ("regex"). L'expression régulière divise chaque chaîne en deux groupes, avec les données souhaitées dans le deuxième groupe.
Regex pour les chaînes de date de relevé et de numéro de compte
# Open the PDF file with pdfplumber.open(file_path) as pdf:
J'ai ensuite transformé la date du relevé au format "aaaammjj". Cela facilite l'interrogation et le tri des données.
regex_date=r'Statement for \b([A-Za-z]{3}-\d{4})\b'
regex_acc_no=r'Account Number ([A-Za-z]\d{7})'
match_date est une variable déclarée lorsqu'une chaîne correspondant à l'expression régulière est trouvée.
Étape 3 : Créer des données tabulaires
Les travaux difficiles - l'extraction des points de données pertinents - étaient pratiquement terminés à ce stade.
Ensuite, j'ai utilisé la fonction DataFrame() de pandas pour créer des données tabulaires basées sur la sortie de l'Étape 2 et de l'Étape 3. J'ai également utilisé cette fonction pour supprimer les colonnes et les lignes inutiles.
Le résultat final peut ensuite être facilement écrit dans un CSV ou stocké dans une base de données.
Étape 4 : Écrire les données dans un fichier CSV
J'ai utilisé la fonction write_to_csv() de Python pour écrire chaque trame de données dans un fichier CSV.
if match_date:
# Convert string to a mmm-yyyy date
date_obj=datetime.strptime(match_date.group(1),"%b-%Y")
# Get last day of the month
last_day=calendar.monthrange(date_obj.year,date_obj.month[1]
# Replace day with last day of month
last_day_of_month=date_obj.replace(day=last_day)
statement_date=last_day_of_month.strftime("%Y%m%d")
df_cash_selected est la trame de données Cash Holdings tandis que file_cash_holdings est le nom de fichier du CSV Cash Holdings.
➡️ J'écrirai les données dans une base de données appropriée une fois que j'aurai acquis un certain savoir-faire en matière de bases de données.
Prochaines étapes
Un script fonctionnel est désormais en place pour extraire les données du tableau et du texte du PDF du relevé de garde.
Avant de continuer, je vais exécuter quelques tests pour voir si le script fonctionne comme prévu.
--Fin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Quelles sont les opérations communes qui peuvent être effectuées sur des tableaux Python?Apr 26, 2025 am 12:22 AM
Quelles sont les opérations communes qui peuvent être effectuées sur des tableaux Python?Apr 26, 2025 am 12:22 AMPythonarRaySSupportVariousOperations: 1) SpecingExtractsSubSets, 2) A SPENDANT / EXPENSEDADDDSELLESS, 3) INSERtingPlaceSelelementsAtSpecific Positions, 4) RemovingdeleteSelements, 5) Sorting / ReversingChangeSes
 Dans quels types d'applications les tableaux Numpy sont-ils couramment utilisés?Apr 26, 2025 am 12:13 AM
Dans quels types d'applications les tableaux Numpy sont-ils couramment utilisés?Apr 26, 2025 am 12:13 AMNumpyArraysAressentialFor Applications est en train de réaliser des objets de manière numérique et une datamanipulation.
 Quand choisiriez-vous d'utiliser un tableau sur une liste dans Python?Apr 26, 2025 am 12:12 AM
Quand choisiriez-vous d'utiliser un tableau sur une liste dans Python?Apr 26, 2025 am 12:12 AMUseanarray.arrayoveralistinpythonwendealing withhomogeneousdata, performance-criticalcode, orinterfacingwithccode.1) homogeneousdata: ArraySaveMemorywithTypelements.2) performance-criticalcode
 Toutes les opérations de liste sont-elles prises en charge par des tableaux, et vice versa? Pourquoi ou pourquoi pas?Apr 26, 2025 am 12:05 AM
Toutes les opérations de liste sont-elles prises en charge par des tableaux, et vice versa? Pourquoi ou pourquoi pas?Apr 26, 2025 am 12:05 AMNon, NotallListOperationsResaSupportedByArrays, andviceVersa.1) ArraysDonotsUpportDynamicOperationsLIKEAPENDORINSERSERTWithoutresizing, qui oblige la performance.2) Listes de la glate-enconteConStanttimecomplexityfordirectAccessLikEArraysDo.
 Comment accéder aux éléments dans une liste de python?Apr 26, 2025 am 12:03 AM
Comment accéder aux éléments dans une liste de python?Apr 26, 2025 am 12:03 AMTOACCESSELlementsInapyThonList, Use Indexing, Négatif Indexing, Specing, Oriteration.1) IndexingStarTsat0.2) négatif Indexing Accesssheend.3) SlicingExtractSports.4) itérationussesforloopsoReNumerate.
 Comment les tableaux sont-ils utilisés dans l'informatique scientifique avec Python?Apr 25, 2025 am 12:28 AM
Comment les tableaux sont-ils utilisés dans l'informatique scientifique avec Python?Apr 25, 2025 am 12:28 AMArraySinpython, en particulier Vianumpy, arecrucialinsciciencomputingfortheirefficiency andversatity.1) ils sont les opérations de data-analyse et la machineauning.2)
 Comment gérez-vous différentes versions Python sur le même système?Apr 25, 2025 am 12:24 AM
Comment gérez-vous différentes versions Python sur le même système?Apr 25, 2025 am 12:24 AMVous pouvez gérer différentes versions Python en utilisant Pyenv, Venv et Anaconda. 1) Utilisez PYENV pour gérer plusieurs versions Python: installer PYENV, définir les versions globales et locales. 2) Utilisez VENV pour créer un environnement virtuel pour isoler les dépendances du projet. 3) Utilisez Anaconda pour gérer les versions Python dans votre projet de science des données. 4) Gardez le Système Python pour les tâches au niveau du système. Grâce à ces outils et stratégies, vous pouvez gérer efficacement différentes versions de Python pour assurer le bon fonctionnement du projet.
 Quels sont les avantages de l'utilisation de tableaux Numpy sur des tableaux Python standard?Apr 25, 2025 am 12:21 AM
Quels sont les avantages de l'utilisation de tableaux Numpy sur des tableaux Python standard?Apr 25, 2025 am 12:21 AMNumpyArrayShaveSeveralAdvantages OverStandardPyThonarRays: 1) TheaReMuchfasterDuetoc-bases Implementation, 2) Ils sont économisés par le therdémor


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

VSCode Windows 64 bits Télécharger
Un éditeur IDE gratuit et puissant lancé par Microsoft

SublimeText3 Linux nouvelle version
Dernière version de SublimeText3 Linux

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

