
 développement back-endTutoriel PythonPartie Construire votre propre IA – Configuration de l'environnement pour le développement de l'IA/ML
développement back-endTutoriel PythonPartie Construire votre propre IA – Configuration de l'environnement pour le développement de l'IA/ML
Auteur : Trix Cyrus
Outil Waymap Pentesting : cliquez ici
TrixSec Github : cliquez ici
Télégramme TrixSec : cliquez ici
Démarrer avec l'IA et le Machine Learning nécessite un environnement de développement bien préparé. Cet article vous guidera dans la configuration des outils et des bibliothèques nécessaires à votre parcours IA/ML, garantissant un démarrage en douceur pour les débutants. Nous discuterons également des plateformes en ligne comme Google Colab pour ceux qui souhaitent éviter les configurations locales complexes.
Configuration système requise pour le développement AI/ML
Avant de vous lancer dans des projets d'IA et d'apprentissage automatique, il est essentiel de vous assurer que votre système peut gérer les demandes de calcul. Alors que la plupart des tâches de base peuvent s'exécuter sur des machines standards, des projets plus avancés (comme l'apprentissage en profondeur) peuvent nécessiter un meilleur matériel. Voici une répartition des exigences système en fonction de la complexité du projet :
1. Pour les débutants : petits projets et apprentissage
- Système d'exploitation : Windows 10/11, macOS ou toute distribution Linux moderne.
- Processeur : CPU double cœur (Intel i5 ou équivalent AMD).
- RAM : 8 Go (minimum) ; 16 Go recommandés pour un multitâche plus fluide.
-
Stockage :
- 20 Go d'espace libre pour Python, les bibliothèques et les petits ensembles de données.
- Un SSD est fortement recommandé pour des performances plus rapides.
- GPU (carte graphique) : Pas nécessaire ; Le processeur suffira pour les tâches de base de ML.
- Connexion Internet : Requise pour télécharger des bibliothèques, des ensembles de données et utiliser des plateformes cloud.
2. Pour les projets intermédiaires : ensembles de données plus grands
- Processeur : Processeur quadricœur (équivalent Intel i7 ou AMD Ryzen 5).
- RAM : 16 Go minimum ; 32 Go recommandés pour les grands ensembles de données.
-
Stockage :
- 50 à 100 Go d'espace libre pour les ensembles de données et les expériences.
- SSD pour un chargement et des opérations rapides des données.
-
GPU :
- GPU dédié avec au moins 4 Go de VRAM (par exemple, NVIDIA GTX 1650 ou AMD Radeon RX 550).
- Utile pour entraîner des modèles plus grands ou expérimenter des réseaux de neurones.
- Affichage : Deux moniteurs peuvent améliorer la productivité lors du débogage et de la visualisation du modèle.
3. Pour les projets avancés : Deep Learning et grands modèles
- Processeur : CPU hautes performances (Intel i9 ou AMD Ryzen 7/9).
- RAM : 32 à 64 Go pour gérer les opérations gourmandes en mémoire et les grands ensembles de données.
-
Stockage :
- 1 To ou plus (SSD fortement recommandé).
- Un stockage externe peut être nécessaire pour les ensembles de données.
-
GPU :
- Les GPU NVIDIA sont préférés pour l'apprentissage en profondeur en raison de la prise en charge de CUDA.
- Recommandé : NVIDIA RTX 3060 (12 Go de VRAM) ou supérieur (par exemple, RTX 3090, RTX 4090).
- Pour les options budgétaires : NVIDIA RTX 2060 ou RTX 2070.
-
Refroidissement et alimentation :
- Assurez un refroidissement adéquat des GPU, en particulier lors de longues séances d'entraînement.
- Alimentation fiable pour prendre en charge le matériel.
4. Plateformes cloud : si votre système échoue
Si votre système ne répond pas aux spécifications ci-dessus ou si vous avez besoin de plus de puissance de calcul, envisagez d'utiliser des plateformes cloud :
- Google Colab : Gratuit avec accès aux GPU (extensible vers Colab Pro pour une durée d'exécution plus longue et de meilleurs GPU).
- AWS EC2 ou SageMaker : Instances hautes performances pour les projets de ML à grande échelle.
- Azure ML ou GCP AI Platform : Convient aux projets de niveau entreprise.
- Kaggle Kernels : Gratuit pour les expériences avec des ensembles de données plus petits.
Configuration recommandée en fonction du cas d'utilisation
| Use Case | CPU | RAM | GPU | Storage |
|---|---|---|---|---|
| Learning Basics | Dual-Core i5 | 8–16 GB | None/Integrated | 20–50 GB |
| Intermediate ML Projects | Quad-Core i7 | 16–32 GB | GTX 1650 (4 GB) | 50–100 GB |
| Deep Learning (Large Models) | High-End i9/Ryzen 9 | 32–64 GB | RTX 3060 (12 GB) | 1 TB SSD |
| Cloud Platforms | Not Required Locally | N/A | Cloud GPUs (e.g., T4, V100) | N/A |
Étape 1 : Installer Python
Python est le langage incontournable pour l'IA/ML en raison de sa simplicité et de son vaste écosystème de bibliothèques. Voici comment l'installer :
-
Télécharger Python :
- Visitez python.org et téléchargez la dernière version stable (de préférence Python 3.9 ou version ultérieure).
-
Installer Python :
- Suivez les étapes d'installation correspondant à votre système d'exploitation (Windows, macOS ou Linux).
- Assurez-vous de cocher l'option ajouter Python à PATH lors de l'installation.
-
Vérifier l'installation :
- Ouvrez un terminal et tapez :
python --version
Vous devriez voir la version installée de Python.
Étape 2 : Configuration d'un environnement virtuel
Pour garder vos projets organisés et éviter les conflits de dépendances, c'est une bonne idée d'utiliser un environnement virtuel.
- Créer un environnement virtuel :
python -m venv env
-
Activer l'environnement virtuel :
- Sous Windows :
.\env\Scripts\activate
-
Sur macOS/Linux :
source env/bin/activate
- Installer les bibliothèques dans l'environnement : Après l'activation, toute bibliothèque installée sera isolée dans cet environnement.
Étape 3 : Installation des bibliothèques essentielles
Une fois Python prêt, installez les bibliothèques suivantes, essentielles pour l'AI/ML :
- NumPy : Pour les calculs numériques.
pip install numpy
- pandas : Pour la manipulation et l'analyse des données.
pip install pandas
- Matplotlib et Seaborn : Pour la visualisation des données.
pip install matplotlib seaborn
- scikit-learn : Pour les algorithmes et outils de base de ML.
pip install scikit-learn
- TensorFlow/PyTorch : Pour l'apprentissage en profondeur.
pip install tensorflow
ou
pip install torch torchvision
- Jupyter Notebook : Un environnement interactif pour le codage et les visualisations.
pip install notebook
Étape 4 : Explorer les notebooks Jupyter
Les notebooks Jupyter offrent un moyen interactif d'écrire et de tester du code, ce qui les rend parfaits pour apprendre l'IA/ML.
- Lancez Jupyter Notebook :
jupyter notebook
Cela ouvrira une interface Web dans votre navigateur.
-
Créer un nouveau carnet :
- Cliquez sur Nouveau > Python 3 Notebook et commencez à coder !
Étape 5 : configuration de Google Colab (facultatif)
Pour ceux qui ne souhaitent pas mettre en place un environnement local, Google Colab est une excellente alternative. C'est gratuit et fournit des GPU puissants pour entraîner des modèles d'IA.
-
Visitez Google Colab :
- Accédez à colab.research.google.com.
-
Créer un nouveau carnet :
- Cliquez sur Nouveau carnet pour commencer.
Installer les bibliothèques (si nécessaire) :
Des bibliothèques comme NumPy et pandas sont préinstallées, mais vous pouvez en installer d'autres en utilisant :
python --version
Étape 6 : tester la configuration
Pour vous assurer que tout fonctionne, exécutez ce test simple dans votre Jupyter Notebook ou Colab :
python -m venv env
La sortie devrait être
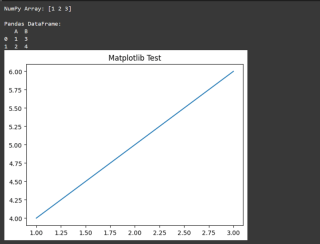
Erreurs courantes et solutions
-
Bibliothèque introuvable :
- Assurez-vous d'avoir installé la bibliothèque dans l'environnement virtuel actif.
-
Python non reconnu :
- Vérifiez que Python est ajouté au PATH de votre système.
-
Problèmes du bloc-notes Jupyter :
- Assurez-vous d'avoir installé Jupyter dans le bon environnement.
~Trixsec
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Les listes Python sont-elles des tableaux dynamiques ou des listes liées sous le capot?May 07, 2025 am 12:16 AM
Les listes Python sont-elles des tableaux dynamiques ou des listes liées sous le capot?May 07, 2025 am 12:16 AMPythonlistsareimpoledasdynamicarrays, notLinkedlists.1) ils sont les plus utiles.
 Comment supprimer les éléments d'une liste Python?May 07, 2025 am 12:15 AM
Comment supprimer les éléments d'une liste Python?May 07, 2025 am 12:15 AMPythonoffersfourmainMethodstoreMoElelementsfromalist: 1) retirez (valeur) supprimer la perception de la réavance, 2) la pop (index) supprimera-theredraturnsanelementAsaspecifiedIndex, 3) DelstatementRemoveselementsbyIndexor
 Que devez-vous vérifier si vous obtenez une erreur 'Autorisation refusée' lorsque vous essayez d'exécuter un script?May 07, 2025 am 12:12 AM
Que devez-vous vérifier si vous obtenez une erreur 'Autorisation refusée' lorsque vous essayez d'exécuter un script?May 07, 2025 am 12:12 AMToresolvea "Permissiondened" Erreur lorsqu'il a fait la recherche de suivi de suivi: 1) CheckAndAdAdAstheScript'sperMissionsusingChmod xmyscript.shtomakeitexecuable.2) s'assureraScriptisloatedInaDirectorywherewheyouHavewritePerMissions, telasyourhomedirectory.
 Comment les tableaux sont-ils utilisés dans le traitement d'image avec Python?May 07, 2025 am 12:04 AM
Comment les tableaux sont-ils utilisés dans le traitement d'image avec Python?May 07, 2025 am 12:04 AMArraysaRecrucialInpythonimage Processeing Antheyeysiable efficiect Manipulation and AnalysyOfimagedata.1) ImagesaReconvertedTonumpyarray
 Pour quels types d'opérations sont-ils considérablement plus rapides que les listes?May 07, 2025 am 12:01 AM
Pour quels types d'opérations sont-ils considérablement plus rapides que les listes?May 07, 2025 am 12:01 AMArraySaRessignifancelyFasterShanlistsForperations BenereFiTFromDirectMemoryAccessSandfixed-Sizestructures.1) AccessingElements: ArraysProvideConstant-TimeAccessDuetoContiguLmemoryStorage.2) ITÉRÉ: ArrayverageCachecalityForfasteriteration.3) Mem
 Expliquez les différences de performance dans les opérations d'élément entre les listes et les tableaux.May 06, 2025 am 12:15 AM
Expliquez les différences de performance dans les opérations d'élément entre les listes et les tableaux.May 06, 2025 am 12:15 AMArraysareBetterForElement-WiseoperationsDuetofasterAccessSandoptimizedImplations.1) ArrayShavEcontiguSMemoryforDirectAccess, EnhancingPerformance.2) ListSaSaSlexible ButslowerDueTopotentialDynamicressizing.3)
 Comment pouvez-vous effectuer efficacement des opérations mathématiques sur des tableaux Numpy entiers?May 06, 2025 am 12:15 AM
Comment pouvez-vous effectuer efficacement des opérations mathématiques sur des tableaux Numpy entiers?May 06, 2025 am 12:15 AMLes opérations mathématiques de l'ensemble du tableau dans Numpy peuvent être implémentées efficacement par le biais d'opérations vectorielles. 1) Utilisez des opérateurs simples tels que l'ajout (ARR 2) pour effectuer des opérations sur les tableaux. 2) Numpy utilise la bibliothèque de langage C sous-jacente, qui améliore la vitesse informatique. 3) Vous pouvez effectuer des opérations complexes telles que la multiplication, la division et les exposants. 4) Faites attention aux opérations de diffusion pour s'assurer que la forme du tableau est compatible. 5) L'utilisation de fonctions Numpy telles que np.sum () peut améliorer considérablement les performances.
 Comment insérez-vous des éléments dans un réseau Python?May 06, 2025 am 12:14 AM
Comment insérez-vous des éléments dans un réseau Python?May 06, 2025 am 12:14 AMDans Python, il existe deux méthodes principales pour insérer des éléments dans une liste: 1) en utilisant la méthode d'insertion (index, valeur), vous pouvez insérer des éléments à l'index spécifié, mais l'insertion au début d'une grande liste est inefficace; 2) En utilisant la méthode APPEND (valeur), ajoutez des éléments à la fin de la liste, ce qui est très efficace. Pour les grandes listes, il est recommandé d'utiliser APPEND () ou d'envisager d'utiliser des tableaux Deque ou Numpy pour optimiser les performances.


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

Dreamweaver Mac
Outils de développement Web visuel

MantisBT
Mantis est un outil Web de suivi des défauts facile à déployer, conçu pour faciliter le suivi des défauts des produits. Cela nécessite PHP, MySQL et un serveur Web. Découvrez nos services de démonstration et d'hébergement.

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

Dreamweaver CS6
Outils de développement Web visuel

