


Achetez-moi un café☕
*Mon message explique EMNIST.
EMNIST() peut utiliser l'ensemble de données EMNIST comme indiqué ci-dessous :
*Mémos :
- Le 1er argument est root (Required-Type:str ou pathlib.Path). *Un chemin absolu ou relatif est possible.
- Le 2ème argument est split(Required-Type:str). *"byclass", "bymerge", "balanced", "letters", "digits" ou "mnist" peuvent y être définis.
- Il existe un argument de train (Optional-Default:False-Type:float) :
*Mémos :
- Pour split="byclass" et split="byclass", si c'est vrai, les données de train (697 932 images) sont utilisées tandis que si c'est faux, les données de test (116 323 images) sont utilisées.
- Pour split="balanced", si c'est vrai, les données de train (112 800 images) sont utilisées tandis que si c'est faux, les données de test (188 00 images) sont utilisées.
- Pour split="letters", si c'est True, les données de train (124 800 images) sont utilisées tandis que si c'est False, les données de test (20 800 images) sont utilisées.
- Pour split="digits", si c'est vrai, les données de train (240 000 images) sont utilisées tandis que si c'est faux, les données de test (40 000 images) sont utilisées.
- Pour split="mnist", si c'est vrai, les données de train (60 000 images) sont utilisées tandis que si c'est faux, les données de test (10 000 images) sont utilisées.
- Il existe un argument de transformation (Optional-Default:None-Type:callable).
- Il existe un argument target_transform (Optional-Default:None-Type:callable).
- Il existe un argument de téléchargement (Optional-Default:False-Type:bool) :
*Mémos :
- Si c'est vrai, l'ensemble de données est téléchargé depuis Internet et extrait (décompressé) vers root.
- Si c'est True et que l'ensemble de données est déjà téléchargé, il est extrait.
- Si c'est vrai et que l'ensemble de données est déjà téléchargé et extrait, rien ne se passe.
- Il devrait être faux si l'ensemble de données est déjà téléchargé et extrait car il est plus rapide.
- Vous pouvez télécharger et extraire manuellement l'ensemble de données à partir d'ici, par exemple. data/EMNIST/raw/.
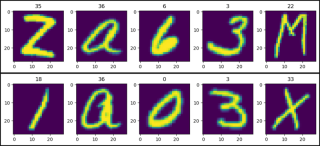
- Il y a le bug selon lequel les images sont retournées et tournées de 90 degrés dans le sens inverse des aiguilles d'une montre par défaut, elles doivent donc être transformées.
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass"
)
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=None,
target_transform=None,
download=False
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
len(train_data), len(test_data)
# 697932 116323
train_data
# Dataset EMNIST
# Number of datapoints: 697932
# Root location: data
# Split: Train
train_data.root
# 'data'
train_data.split
# 'byclass'
train_data.train
# True
print(train_data.transform)
# None
print(train_data.target_transform)
# None
train_data.download
# <bound method emnist.download of dataset emnist number datapoints: root location: data split: train>
train_data[0]
# (<pil.image.image image mode="L" size="28x28">, 35)
train_data[1]
# (<pil.image.image image mode="L" size="28x28">, 36)
train_data[2]
# (<pil.image.image image mode="L" size="28x28">, 6)
train_data[3]
# (<pil.image.image image mode="L" size="28x28">, 3)
train_data[4]
# (<pil.image.image image mode="L" size="28x28">, 22)
train_data.classes
# ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
# 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
# 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
# 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
# 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
</pil.image.image></pil.image.image></pil.image.image></pil.image.image></pil.image.image></bound>
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass",
train=True
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
import matplotlib.pyplot as plt
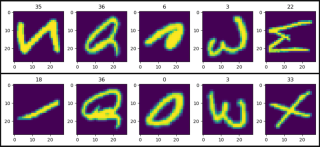
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
from torchvision.datasets import EMNIST
from torchvision.transforms import v2
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
test_data = EMNIST(
root="data",
split="byclass",
train=False,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
import matplotlib.pyplot as plt
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Comment utiliser Python pour trouver la distribution ZIPF d'un fichier texteMar 05, 2025 am 09:58 AM
Comment utiliser Python pour trouver la distribution ZIPF d'un fichier texteMar 05, 2025 am 09:58 AMCe tutoriel montre comment utiliser Python pour traiter le concept statistique de la loi de Zipf et démontre l'efficacité de la lecture et du tri de Python de gros fichiers texte lors du traitement de la loi. Vous vous demandez peut-être ce que signifie le terme distribution ZIPF. Pour comprendre ce terme, nous devons d'abord définir la loi de Zipf. Ne vous inquiétez pas, je vais essayer de simplifier les instructions. La loi de Zipf La loi de Zipf signifie simplement: dans un grand corpus en langage naturel, les mots les plus fréquents apparaissent environ deux fois plus fréquemment que les deuxième mots fréquents, trois fois comme les troisième mots fréquents, quatre fois comme quatrième mots fréquents, etc. Regardons un exemple. Si vous regardez le corpus brun en anglais américain, vous remarquerez que le mot le plus fréquent est "th
 Comment télécharger des fichiers dans PythonMar 01, 2025 am 10:03 AM
Comment télécharger des fichiers dans PythonMar 01, 2025 am 10:03 AMPython fournit une variété de façons de télécharger des fichiers à partir d'Internet, qui peuvent être téléchargés sur HTTP à l'aide du package ULLIB ou de la bibliothèque de demandes. Ce tutoriel expliquera comment utiliser ces bibliothèques pour télécharger des fichiers à partir des URL de Python. Bibliothèque de demandes Les demandes sont l'une des bibliothèques les plus populaires de Python. Il permet d'envoyer des demandes HTTP / 1.1 sans ajouter manuellement les chaînes de requête aux URL ou le codage de formulaire de post-données. La bibliothèque des demandes peut remplir de nombreuses fonctions, notamment: Ajouter des données de formulaire Ajouter un fichier en plusieurs parties Accéder aux données de réponse Python Faire une demande tête
 Comment utiliser la belle soupe pour analyser HTML?Mar 10, 2025 pm 06:54 PM
Comment utiliser la belle soupe pour analyser HTML?Mar 10, 2025 pm 06:54 PMCet article explique comment utiliser la belle soupe, une bibliothèque Python, pour analyser HTML. Il détaille des méthodes courantes comme find (), find_all (), select () et get_text () pour l'extraction des données, la gestion de diverses structures et erreurs HTML et alternatives (Sel
 Filtrage d'image en pythonMar 03, 2025 am 09:44 AM
Filtrage d'image en pythonMar 03, 2025 am 09:44 AMTraiter avec des images bruyantes est un problème courant, en particulier avec des photos de téléphones portables ou de caméras basse résolution. Ce tutoriel explore les techniques de filtrage d'images dans Python à l'aide d'OpenCV pour résoudre ce problème. Filtrage d'image: un outil puissant Filtre d'image
 Comment travailler avec des documents PDF à l'aide de PythonMar 02, 2025 am 09:54 AM
Comment travailler avec des documents PDF à l'aide de PythonMar 02, 2025 am 09:54 AMLes fichiers PDF sont populaires pour leur compatibilité multiplateforme, avec du contenu et de la mise en page cohérents sur les systèmes d'exploitation, les appareils de lecture et les logiciels. Cependant, contrairement aux fichiers de texte brut de traitement Python, les fichiers PDF sont des fichiers binaires avec des structures plus complexes et contiennent des éléments tels que des polices, des couleurs et des images. Heureusement, il n'est pas difficile de traiter les fichiers PDF avec les modules externes de Python. Cet article utilisera le module PYPDF2 pour montrer comment ouvrir un fichier PDF, imprimer une page et extraire du texte. Pour la création et l'édition des fichiers PDF, veuillez vous référer à un autre tutoriel de moi. Préparation Le noyau réside dans l'utilisation du module externe PYPDF2. Tout d'abord, l'installez en utilisant PIP: pip is p
 Comment se cacher en utilisant Redis dans les applications DjangoMar 02, 2025 am 10:10 AM
Comment se cacher en utilisant Redis dans les applications DjangoMar 02, 2025 am 10:10 AMCe tutoriel montre comment tirer parti de la mise en cache Redis pour augmenter les performances des applications Python, en particulier dans un cadre Django. Nous couvrirons l'installation redis, la configuration de Django et les comparaisons de performances pour mettre en évidence le bien
 Présentation de la boîte à outils en langage naturel (NLTK)Mar 01, 2025 am 10:05 AM
Présentation de la boîte à outils en langage naturel (NLTK)Mar 01, 2025 am 10:05 AMLe traitement du langage naturel (PNL) est le traitement automatique ou semi-automatique du langage humain. La PNL est étroitement liée à la linguistique et a des liens vers la recherche en sciences cognitives, psychologie, physiologie et mathématiques. En informatique
 Comment effectuer l'apprentissage en profondeur avec TensorFlow ou Pytorch?Mar 10, 2025 pm 06:52 PM
Comment effectuer l'apprentissage en profondeur avec TensorFlow ou Pytorch?Mar 10, 2025 pm 06:52 PMCet article compare TensorFlow et Pytorch pour l'apprentissage en profondeur. Il détaille les étapes impliquées: préparation des données, construction de modèles, formation, évaluation et déploiement. Différences clés entre les cadres, en particulier en ce qui concerne le raisin informatique


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Dreamweaver Mac
Outils de développement Web visuel

PhpStorm version Mac
Le dernier (2018.2.1) outil de développement intégré PHP professionnel

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

