
Maison >développement back-end >Tutoriel Python >Comment récupérer les résultats de recherche Google avec Python
Comment récupérer les résultats de recherche Google avec Python

- Susan Sarandonoriginal
- 2024-12-05 12:31:10580parcourir
Scraping Google Search offre des capacités essentielles d'analyse SERP, d'optimisation du référencement et de collecte de données. Les outils de grattage modernes rendent ce processus plus rapide et plus fiable.
Un des membres de notre communauté a écrit ce blog en guise de contribution au blog Crawlee. Si vous souhaitez contribuer à des blogs comme ceux-ci sur Crawlee Blog, veuillez nous contacter sur notre chaîne Discord.
Dans ce guide, nous allons créer un grattoir de recherche Google à l'aide de Crawlee pour Python, capable de gérer le classement et la pagination des résultats.
Nous allons créer un grattoir qui :
- Extrait les titres, les URL et les descriptions des résultats de recherche
- Gère plusieurs requêtes de recherche
- Suive les positions de classement
- Traite plusieurs pages de résultats
- Enregistre les données dans un format structuré
Conditions préalables
- Python 3.7 ou supérieur
- Compréhension de base des sélecteurs HTML et CSS
- Familiarité avec les concepts de web scraping
- Crawlee pour Python v0.4.2 ou supérieur
Configuration du projet
-
Installez Crawlee avec les dépendances requises :
pipx install crawlee[beautifulsoup,curl-impersonate]
-
Créez un nouveau projet à l'aide de Crawlee CLI :
pipx run crawlee create crawlee-google-search
Lorsque vous y êtes invité, sélectionnez Beautifulsoup comme type de modèle.
-
Accédez au répertoire du projet et terminez l'installation :
cd crawlee-google-search poetry install
Développement du scraper Google Search en Python
1. Définir les données à extraire
Tout d'abord, définissons notre portée d'extraction. Les résultats de recherche de Google incluent désormais des cartes, des personnalités, des détails sur l'entreprise, des vidéos, des questions courantes et bien d'autres éléments. Nous nous concentrerons sur l'analyse des résultats de recherche standard avec classements.
Voici ce que nous allons extraire :

Vérifions si nous pouvons extraire les données nécessaires du code HTML de la page, ou si nous avons besoin d'une analyse plus approfondie ou d'un rendu JS. Notez que cette vérification est sensible aux balises HTML :

Sur la base des données obtenues à partir de la page, toutes les informations nécessaires sont présentes dans le code HTML. Par conséquent, nous pouvons utiliser beautifulsoup_crawler.
Les champs que nous extrairons :
- Titres des résultats de recherche
- URL
- Texte de description
- Positions du classement
2. Configurez le robot d'exploration
Tout d'abord, créons la configuration du robot.
Nous utiliserons CurlImpersonateHttpClient comme client http avec des en-têtes prédéfinis et une usurpation d'identité pertinente pour le navigateur Chrome.
Nous configurerons également ConcurrencySettings pour contrôler l’agressivité du scraping. Ceci est crucial pour éviter d'être bloqué par Google.
Si vous avez besoin d'extraire des données de manière plus intensive, envisagez de configurer ProxyConfiguration.
pipx install crawlee[beautifulsoup,curl-impersonate]
3. Implémentation de l'extraction de données
Tout d'abord, analysons le code HTML des éléments que nous devons extraire :

Il existe une distinction évidente entre les attributs d'ID lisibles et les noms de classe générés et autres attributs. Lors de la création de sélecteurs pour l'extraction de données, vous devez ignorer tous les attributs générés. Même si vous avez lu que Google utilise une balise générée particulière depuis N ans, vous ne devriez pas vous y fier - cela reflète votre expérience dans l'écriture de code robuste.
Maintenant que nous comprenons la structure HTML, implémentons l'extraction. Comme notre robot ne traite qu'un seul type de page, nous pouvons utiliser router.default_handler pour le traiter. Dans le gestionnaire, nous utiliserons BeautifulSoup pour parcourir chaque résultat de recherche, en extrayant des données telles que le titre, l'URL et text_widget tout en enregistrant les résultats.
pipx run crawlee create crawlee-google-search
4. Gestion de la pagination
Étant donné que les résultats Google dépendent de la géolocalisation IP de la requête de recherche, nous ne pouvons pas nous fier au texte du lien pour la pagination. Nous devons créer un sélecteur CSS plus sophistiqué qui fonctionne quels que soient les paramètres de géolocalisation et de langue.
Le paramètre max_crawl_owned contrôle le nombre de pages que notre robot doit analyser. Une fois que nous avons notre sélecteur robuste, nous devons simplement obtenir le lien de la page suivante et l'ajouter à la file d'attente du robot.
Pour écrire des sélecteurs plus efficaces, apprenez les bases de la syntaxe CSS et XPath.
cd crawlee-google-search poetry install
5. Exportation des données au format CSV
Puisque nous souhaitons enregistrer toutes les données des résultats de recherche dans un format tabulaire pratique tel que CSV, nous pouvons simplement ajouter l'appel à la méthode export_data juste après avoir exécuté le robot :
from crawlee.beautifulsoup_crawler import BeautifulSoupCrawler
from crawlee.http_clients.curl_impersonate import CurlImpersonateHttpClient
from crawlee import ConcurrencySettings, HttpHeaders
async def main() -> None:
concurrency_settings = ConcurrencySettings(max_concurrency=5, max_tasks_per_minute=200)
http_client = CurlImpersonateHttpClient(impersonate="chrome124",
headers=HttpHeaders({"referer": "https://www.google.com/",
"accept-language": "en",
"accept-encoding": "gzip, deflate, br, zstd",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}))
crawler = BeautifulSoupCrawler(
max_request_retries=1,
concurrency_settings=concurrency_settings,
http_client=http_client,
max_requests_per_crawl=10,
max_crawl_depth=5
)
await crawler.run(['https://www.google.com/search?q=Apify'])
6. Finalisation du scraper de recherche Google
Bien que notre logique de base de robot d'exploration fonctionne, vous avez peut-être remarqué que nos résultats manquent actuellement d'informations sur la position de classement. Pour compléter notre scraper, nous devons mettre en œuvre un suivi approprié de la position de classement en transmettant des données entre les requêtes à l'aide de user_data dans Request.
Modifions le script pour gérer plusieurs requêtes et suivre les positions de classement pour l'analyse des résultats de recherche. Nous définirons également la profondeur d'exploration en tant que variable de niveau supérieur. Déplaçons le router.default_handler vers routes.py pour correspondre à la structure du projet :
@crawler.router.default_handler
async def default_handler(context: BeautifulSoupCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request} ...')
for item in context.soup.select("div#search div#rso div[data-hveid][lang]"):
data = {
'title': item.select_one("h3").get_text(),
"url": item.select_one("a").get("href"),
"text_widget": item.select_one("div[style*='line']").get_text(),
}
await context.push_data(data)
Modifions également le gestionnaire pour ajouter les champs query et order_no et la gestion des erreurs de base :
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
Et c'est fini !
Notre robot d'exploration de recherche Google est prêt. Regardons les résultats dans le fichier google_ranked.csv :
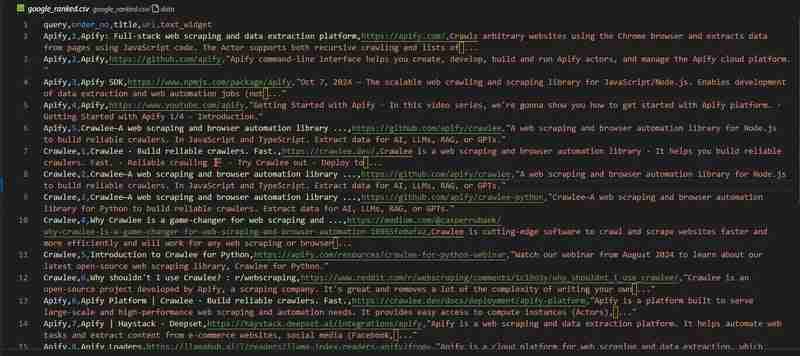
Le dépôt de code est disponible sur GitHub
Grattez les résultats de recherche Google avec Apify
Si vous travaillez sur un projet à grande échelle nécessitant des millions de points de données, comme le projet présenté dans cet article sur l'analyse du classement Google, vous aurez peut-être besoin d'une solution toute faite.
Envisagez d'utiliser Google Search Results Scraper par l'équipe Apify.
Il offre des fonctionnalités importantes telles que :
- Support proxy
- Évolutivité pour l'extraction de données à grande échelle
- Contrôle de géolocalisation
- Intégration avec des services externes comme Zapier, Make, Airbyte, LangChain et autres
Vous pouvez en savoir plus sur le blog Apify
Que vas-tu gratter ?
Dans ce blog, nous avons expliqué étape par étape comment créer un robot d'exploration de recherche Google qui collecte des données de classement. La manière dont vous analysez cet ensemble de données dépend de vous !
Pour rappel, vous pouvez retrouver le code complet du projet sur GitHub.
J'aimerais penser que dans 5 ans j'aurai besoin d'écrire un article sur "Comment extraire des données du meilleur moteur de recherche pour les LLM", mais je soupçonne que dans 5 ans cet article sera toujours d'actualité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!