
Maison >développement back-end >Tutoriel Python >Chapitre ML Traitement du langage naturel
Chapitre ML Traitement du langage naturel

- Susan Sarandonoriginal
- 2024-11-20 02:34:021042parcourir
Le traitement du langage naturel (NLP) implique l'utilisation de modèles d'apprentissage automatique pour travailler avec du texte et du langage. L’objectif de la PNL est d’apprendre aux machines à comprendre les mots parlés et écrits. Par exemple, lorsque vous dictez quelque chose sur votre iPhone ou votre appareil Android et que celui-ci convertit votre parole en texte, c'est un algorithme PNL à l'œuvre.
Vous pouvez également utiliser la PNL pour analyser une critique de texte et prédire si elle est positive ou négative. La PNL peut catégoriser les articles ou déterminer le genre d'un livre. Il peut même être utilisé pour créer des traducteurs automatiques ou des systèmes de reconnaissance vocale. Dans ces cas, les algorithmes de classification aident à identifier la langue. La plupart des algorithmes PNL sont des modèles de classification, notamment la régression logistique, Naive Bayes, CART (un modèle d'arbre de décision), l'entropie maximale (également liée aux arbres de décision) et les modèles de Markov cachés (basés sur les processus de Markov).
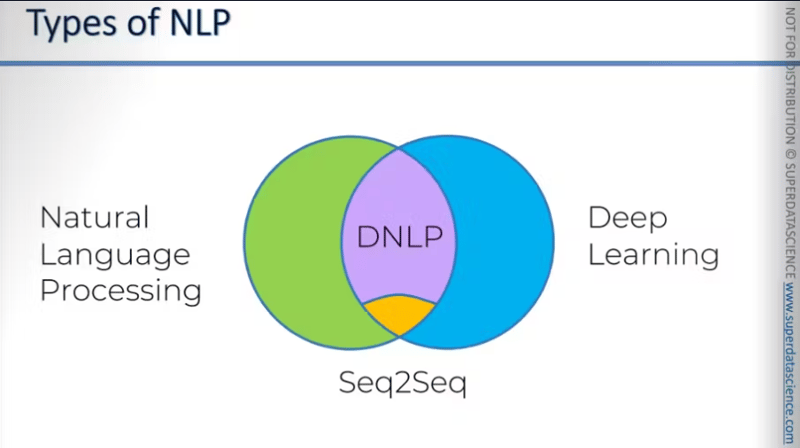
Petit aperçu avant de commencer : A gauche du diagramme de Venn, nous avons du vert représentant la PNL. A droite, nous avons du bleu représentant DL. Au carrefour, nous avons DNLP. Il existe une sous-section de DNLP appelée Seq2Seq. La séquence en séquence est actuellement le modèle le plus avancé et le plus puissant pour la PNL. Cependant, nous ne discuterons pas de seq2seq dans ce blog. Nous couvrirons essentiellement la classification du sac de mots.
Dans cette partie, vous comprendrez et apprendrez à :
- Texte propre pour le préparer aux modèles d'apprentissage automatique.
- Créez un modèle de sac de mots.
- Appliquez des modèles d'apprentissage automatique à ce modèle Bag of Words. Voici sur quoi nous allons nous concentrer. Remarque : Nous ne discuterons pas de Seq2Seq, des chatbots ou du PNL approfondi. Les matériaux que j'ai utilisés proviennent de la PNL avec DL, nous exclurons donc la partie DL.

Pour lire le blog complet : ML Chapitre 7 : Traitement du langage naturel
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!