
Maison >développement back-end >Tutoriel Python >ClassiSage : Modèle automatisé de classification des journaux HDFS basé sur AWS SageMaker Terraform IaC
ClassiSage : Modèle automatisé de classification des journaux HDFS basé sur AWS SageMaker Terraform IaC

- Barbara Streisandoriginal
- 2024-10-26 05:04:30649parcourir
ClassiSage
Un modèle d'apprentissage automatique réalisé avec AWS SageMaker et son SDK Python pour la classification des journaux HDFS à l'aide de Terraform pour l'automatisation de la configuration de l'infrastructure.
Lien : GitHub
Langage : HCL (terraform), Python
Contenu
- Aperçu : Aperçu du projet.
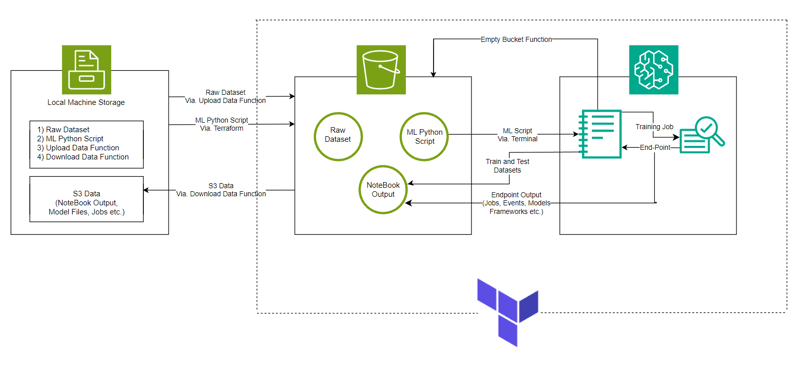
- Architecture du système : diagramme d'architecture du système
- Modèle ML : aperçu du modèle.
- Mise en route : Comment exécuter le projet.
- Observations de la console : modifications des instances et de l'infrastructure qui peuvent être observées lors de l'exécution du projet.
- Fin et nettoyage : garantir l'absence de frais supplémentaires.
- Objets créés automatiquement : fichiers et dossiers créés pendant le processus d'exécution.
- Suivez d'abord la structure des répertoires pour une meilleure configuration du projet.
- Prenez la référence majeure du référentiel de projets de ClassiSage téléchargé dans GitHub pour une meilleure compréhension.
Aperçu
- Le modèle est réalisé avec AWS SageMaker pour la classification des journaux HDFS avec S3 pour le stockage de l'ensemble de données, du fichier Notebook (contenant le code pour l'instance SageMaker) et de la sortie du modèle.
- La configuration de l'infrastructure est automatisée à l'aide de Terraform, un outil permettant de fournir une infrastructure en tant que code créée par HashiCorp.
- L'ensemble de données utilisé est HDFS_v1.
- Le projet implémente le SDK SageMaker Python avec le modèle XGBoost version 1.2
Architecture du système
Modèle ML
- URI de l’image
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')

- Initialisation de l'appel Hyper Parameter et Estimator au conteneur
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).

- Travail de formation
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- Déploiement
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')

- Validation
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
Commencer
- Clonez le référentiel à l'aide de Git Bash / téléchargez un fichier .zip / forkez le référentiel.
- Accédez à votre AWS Management Console, cliquez sur le profil de votre compte dans le coin supérieur droit et sélectionnez Mes informations d'identification de sécurité dans la liste déroulante.
- Créer une clé d'accès : Dans la section Clés d'accès, cliquez sur Créer une nouvelle clé d'accès, une boîte de dialogue apparaîtra avec votre ID de clé d'accès et votre clé d'accès secrète.
- Télécharger ou copier les clés : (IMPORTANT) Téléchargez le fichier .csv ou copiez les clés dans un emplacement sécurisé. C'est la seule fois où vous pouvez voir la clé d'accès secrète.
- Ouvrez le dépôt cloné. dans votre VS Code
- Créez un fichier sous ClassiSage sous le nom terraform.tfvars avec son contenu comme
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
- Téléchargez et installez toutes les dépendances pour utiliser Terraform et Python.
Dans le terminal, tapez/collez terraform init pour initialiser le backend.
Puis tapez/collez terraform Plan pour visualiser le plan ou simplement terraform validez pour vous assurer qu'il n'y a pas d'erreur.
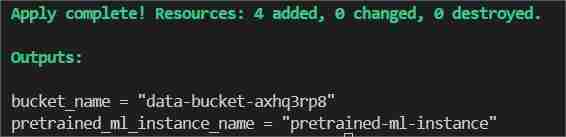
Enfin dans le terminal, tapez/collez terraform apply --auto-approve
Cela affichera deux sorties, l'une sous le nom de bucket_name, l'autre sous le nom de pretrained_ml_instance_name (la 3ème ressource est le nom de variable donné au bucket puisqu'il s'agit de ressources globales).
- Une fois la fin de la commande affichée dans le terminal, accédez à ClassiSage/ml_ops/function.py et à la 11ème ligne du fichier avec le code
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
et remplacez-le par le chemin où se trouve le répertoire du projet et enregistrez-le.
- Ensuite, sur ClassiSageml_opsdata_upload.ipynb, exécutez toutes les cellules de code jusqu'à la cellule numéro 25 avec le code
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
pour télécharger l'ensemble de données sur S3 Bucket.
- Sortie de l'exécution de la cellule de code

- Après l'exécution du notebook, rouvrez votre AWS Management Console.
- Vous pouvez rechercher les services S3 et Sagemaker et verrez une instance de chaque service lancé (un compartiment S3 et un bloc-notes SageMaker)
Seau S3 nommé 'data-bucket-' avec 2 objets téléchargés, un ensemble de données et le fichier pretrained_sm.ipynb contenant le code du modèle.
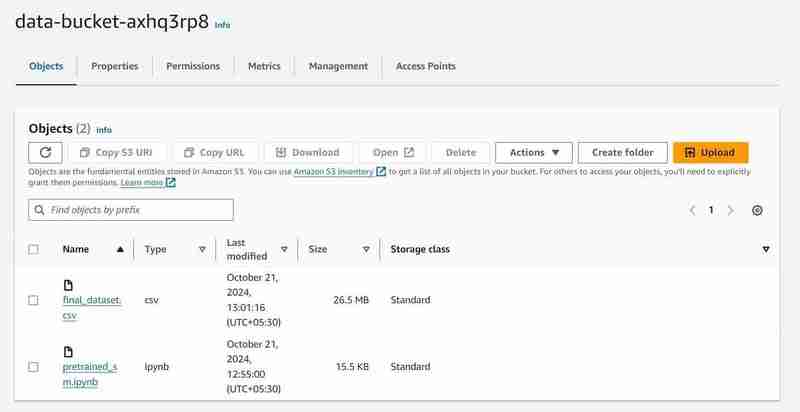

- Accédez à l'instance de notebook dans AWS SageMaker, cliquez sur l'instance créée et cliquez sur ouvrir Jupyter.
- Après cela, cliquez sur nouveau en haut à droite de la fenêtre et sélectionnez sur le terminal.
- Cela créera un nouveau terminal.
- Sur le terminal, collez ce qui suit (en le remplaçant par la sortie bucket_name qui est affichée dans la sortie du terminal du VS Code) :
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
Commande de terminal pour télécharger le pretrained_sm.ipynb de S3 vers l'environnement Jupyter de Notebook
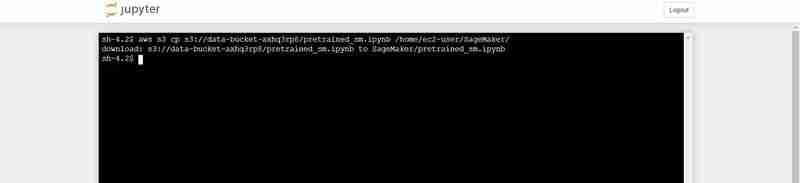
- Retournez à l'instance Jupyter ouverte et cliquez sur le fichier pretrained_sm.ipynb pour l'ouvrir et lui attribuer un noyau conda_python3.
- Faites défiler jusqu'à la 4ème cellule et remplacez la valeur de la variable bucket_name par la sortie du terminal du VS Code pour bucket_name = "
"
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
Sortie de l'exécution de la cellule de code

- En haut du fichier, effectuez un redémarrage en allant dans l'onglet Kernel.
- Exécutez le Notebook jusqu'au numéro de cellule de code 27, avec le code
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
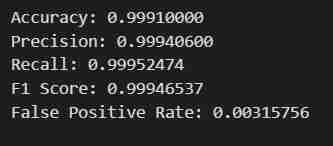
- Vous obtiendrez le résultat escompté. Les données seront récupérées, divisées en ensembles d'entraînement et de test après avoir été ajustées pour les étiquettes et les fonctionnalités avec un chemin de sortie défini, puis un modèle utilisant le SDK Python de SageMaker sera formé, déployé en tant que point final et validé pour donner différentes métriques.
Notes d'observation de la console
Exécution de la 8ème cellule
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
- Un chemin de sortie sera configuré dans le S3 pour stocker les données du modèle.

Exécution de la 23ème cellule
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
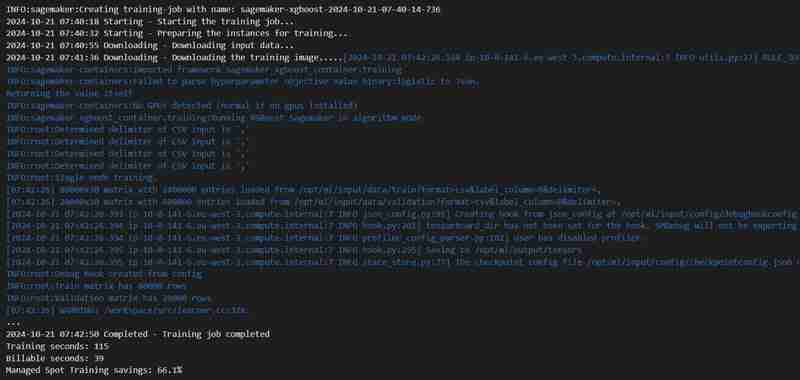
- Un travail de formation va démarrer, vous pouvez le vérifier sous l'onglet formation.

- Après un certain temps (3 minutes est.), il sera terminé et affichera la même chose.

Exécution de la 24ème cellule de code
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
- Un point de terminaison sera déployé sous l'onglet Inférence.
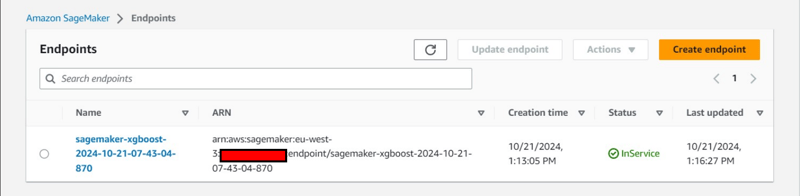
Observation supplémentaire sur la console :
- Création d'une configuration de point de terminaison sous l'onglet Inférence.

- Création d'un modèle également sous l'onglet Inférence.
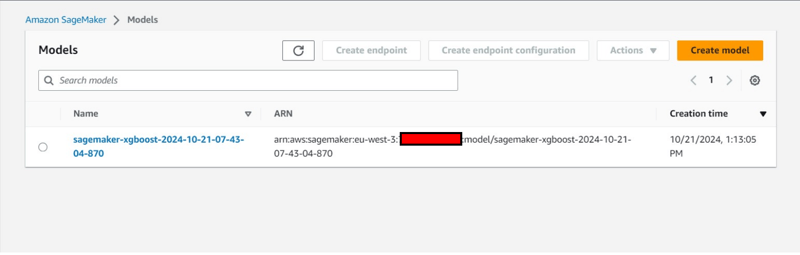
Fin et nettoyage
- Dans le retour de VS Code sur data_upload.ipynb pour exécuter les 2 dernières cellules de code afin de télécharger les données du compartiment S3 dans le système local.
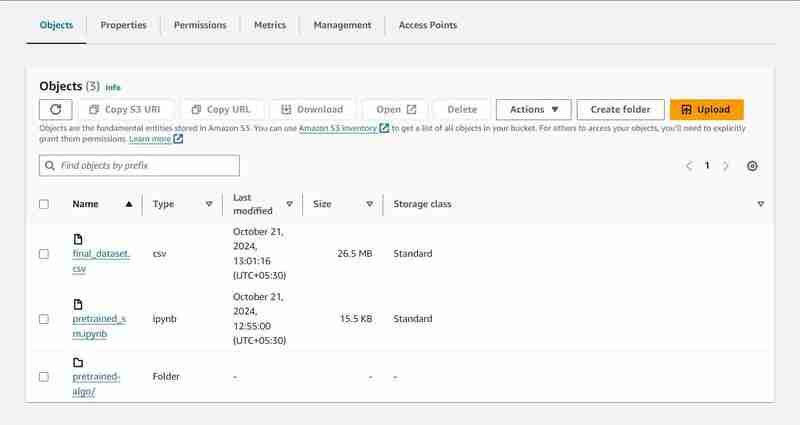
- Le dossier s'appellera download_bucket_content. Structure du répertoire du dossier téléchargé.
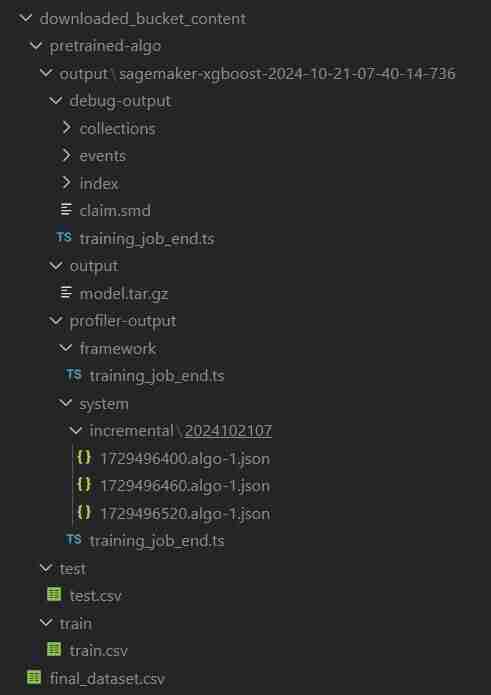
- Vous obtiendrez un journal des fichiers téléchargés dans la cellule de sortie. Il contiendra un pretrained_sm.ipynb brut, final_dataset.csv et un dossier de sortie de modèle nommé 'pretrained-algo' avec les données d'exécution du fichier de code sagemaker.
- Enfin, allez dans pretrained_sm.ipynb présent dans l'instance SageMaker et exécutez les 2 dernières cellules de code. Le point de terminaison et les ressources du compartiment S3 seront supprimés pour garantir l'absence de frais supplémentaires.
- Suppression du point de terminaison
estimator.fit({'train': s3_input_train,'validation': s3_input_test})

- Effacement de S3 : (nécessaire pour détruire l'instance)
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
- Revenez au terminal VS Code pour le fichier de projet, puis tapez/collez terraform destroy --auto-approve
- Toutes les instances de ressources créées seront supprimées.
Objets créés automatiquement
ClassiSage/downloaded_bucket_content
ClassiSage/.terraform
ClassiSage/ml_ops/pycache
ClassiSage/.terraform.lock.hcl
ClassiSage/terraform.tfstate
ClassiSage/terraform.tfstate.backup
REMARQUE :
Si vous avez aimé l'idée et la mise en œuvre de ce projet d'apprentissage automatique utilisant S3 d'AWS Cloud et SageMaker pour la classification des journaux HDFS, en utilisant Terraform pour IaC (automatisation de la configuration de l'infrastructure), pensez à aimer cet article et à jouer après avoir consulté le référentiel du projet sur GitHub. .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!