
Maison >développement back-end >Tutoriel Python >Ma première contribution open source
Ma première contribution open source

- DDDoriginal
- 2024-09-19 10:17:001816parcourir
Déposer un problème
Pour ma première contribution, j'ai déposé un problème pour ajouter une nouvelle fonctionnalité à un autre projet qui consiste à ajouter une nouvelle option de drapeau pour afficher les jetons utilisés pour l'invite et la génération d'achèvement.
 FEAT: Chat Termition Token Info INFORMATION OPTION
#8
FEAT: Chat Termition Token Info INFORMATION OPTION
#8

Description
Une option d'indicateur qui donne à l'utilisateur un nombre de jetons envoyés et reçus. Je pense que c'est une fonctionnalité importante qui guide l'utilisateur à respecter le budget symbolique lorsqu'il fait une demande de terminaison de chat !
implémentation
Pour ce faire, nous aurions besoin d'ajouter un autre indicateur d'option qui pourrait être -t et --token-usage. Lorsqu'un utilisateur inclut cet indicateur dans sa commande, il doit afficher de manière claire et détaillée combien de jetons ont été utilisés lors de la génération de l'achèvement et combien de jetons ont été utilisés dans l'invite.
J'ai choisi de contribuer au projet open source de fadingNA, chat-minal, un outil CLI écrit en Python qui vous permet d'exploiter OpenAI pour faire diverses choses, comme l'utiliser pour générer une révision de code, une conversion de fichiers, générer une démarque à partir de texte et résumer le texte.
Ma demande de tirage
J'ai déjà écrit du code en Python, mais ce n'est pas ma plus grande compétence. Donc contribuer à ce projet offre pour moi une expérience d’apprentissage stimulante mais bonne.
Le défi est que je devrais lire et comprendre le code de quelqu'un d'autre et fournir une solution appropriée de manière à ne pas rompre la conception du code. Comprendre le flux est crucial pour pouvoir ajouter efficacement la fonctionnalité sans avoir à apporter de grandes modifications au code et maintenir la cohérence du code.
FEAT : indicateur d'utilisation du jeton
#9
Fonctionnalité
Ajout de la fonctionnalité pour inclure une option d'indicateur --token_usage pour l'utilisateur. Cette option donne à l'utilisateur des informations sur le nombre de jetons utilisés pour l'invite et l'achèvement généré.
implémentation
La solution que j'ai trouvée en fonction de la conception du code est de vérifier l'existence de l'indicateur token_usage. Je ne veux pas que le code vérifie des instructions if inutiles si l'indicateur token_usage n'a pas été utilisé, j'ai donc créé deux logiques de boucle identiques distinctes, avec la différence de vérifier l'existence de usage_metadata à l'intérieur du morceau.
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Affichage
At the end of the execution of get_completions() method, a check for the flag token_usage is added, which then displays the token usage details to stderr if the flag was used.
if token_usage:
logger.error(f"Tokens used for completion: <span class="pl-s1"><span class="pl-kos">{completion_tokens}</span>"</span>)
logger.error(f"Tokens used for prompt: <span class="pl-s1"><span class="pl-kos">{prompt_tokens}</span>"</span>)
My solution
Retrieving the token usage
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Originally, the code only had one for loop which retrieves the content from a stream and appends it to an array which forms the response of the completion.
Why did I write it this way?
My reasoning behind duplicating the for while adding the distinct if block is to prevent the code from repeatedly checking the if block even if the user is not using the newly added --token_usage flag. So instead, I check for the existence of the flag firstly, and then decide which for loop to execute.
Realization
Even though my pull request has been accepted by the project owner, I realized late that this way adds complexity to the code's maintainability. For example, if there are changes required in the for loop for processing the stream, that means modifying the code twice since there are two identical for loops.
What I think I could do as an improvement for it is to make it into a function so that any changes required can be done in one function only, keeping the maintainability of the code. This just proves that even if I wrote the code with optimization in mind, there are still other things that I can miss which is crucial to a project, which in this case, is maintainability.
Receiving a pull request
My tool, genereadme, also received a contribution. I received a PR from Mounayer, which is to add the same feature to my project.
feat: added a new flag that displays the number of tokens sent in prompt and received in completion
#13

Description
Closes #12.
- Added a new flag --token-usage which when given, prints the number of tokens that were sent in the prompt and the number of tokens that were returned in the completion to `stderr.
This simply required the addition for another flag check --token-usage:
.option("--token-usage", "Show prompt and completion token usage")
I've also made sure to keep your naming conventions/formatting style consistent, in the for loop that does the chat completion for each file processed, I have accumulated the total tokens sent and received:
promptTokens += response.usage.prompt_tokens;
completionTokens += response.usage.completion_tokens;
which I then display at the end of program run-time if the --token-usage flag is provided as such:
if (program.opts().tokenUsage) {
console.error(`Prompt tokens: <span class="pl-s1"><span class="pl-kos">${promptTokens}</span>`</span>);
console.error(`Completion tokens: <span class="pl-s1"><span class="pl-kos">${completionTokens}</span>`</span>);
}
- Updated README.md to explain the new flag.
Testing
Test 1
genereadme examples/sum.js --token-usage
This should display something like:
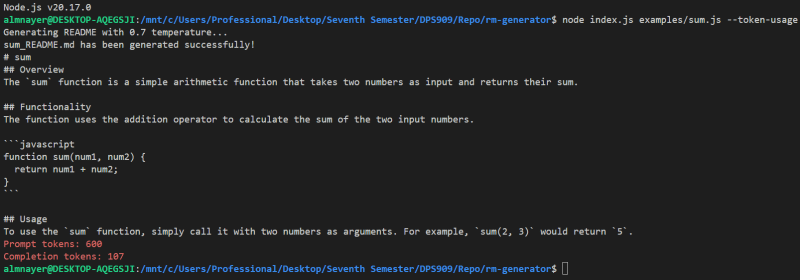
Test 2
You can try it out with multiple files too, i.e.:
genereadme examples/sum.js examples/createUser.js --token-usage
This time, instead of having to read someone else's code, someone had to read mine and contribute to it. It is nice knowing that someone is able to contribute to my project. To me, it means that they understood how my code works, so they were able to add the feature without breaking anything or adding any complexity to the code base.
With that being mentioned, reading code is also a skill that is not to be underestimated. My code is nowhere near perfect and I know there are still places I can improve on, so credit is also due to being able to read and understand code.
This specific pull request did not really require any back and forth changes as the code that was written by Mounayer is what I would have written myself.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!