
Maison >développement back-end >Tutoriel Python >Reliez l'IA/ML avec votre solution Adaptive Analytics
Reliez l'IA/ML avec votre solution Adaptive Analytics

- DDDoriginal
- 2024-09-13 06:27:07818parcourir
Dans le paysage des données actuel, les entreprises sont confrontées à un certain nombre de défis différents. L’une d’elles consiste à effectuer des analyses au-dessus d’une couche de données unifiée et harmonisée disponible pour tous les consommateurs. Une couche qui peut fournir les mêmes réponses aux mêmes questions, quel que soit le dialecte ou l'outil utilisé.
InterSystems IRIS Data Platform répond à cela avec un module complémentaire d'Adaptive Analytics qui peut fournir cette couche sémantique unifiée. Il existe de nombreux articles dans DevCommunity sur son utilisation via les outils BI. Cet article expliquera comment le consommer avec l'IA et également comment en remettre quelques informations.
Allons-y étape par étape...
Qu'est-ce que l'analyse adaptative ?
Vous pouvez facilement trouver une définition sur le site Web de la communauté des développeurs
En quelques mots, il peut fournir des données sous une forme structurée et harmonisée à divers outils de votre choix pour une consommation et une analyse ultérieures. Il fournit les mêmes structures de données à divers outils de BI. Mais... il peut également fournir les mêmes structures de données à vos outils AI/ML !
Adaptive Analytics possède un composant supplémentaire appelé AI-Link qui établit ce pont entre l'IA et la BI.
Qu'est-ce qu'AI-Link exactement ?
Il s'agit d'un composant Python conçu pour permettre une interaction programmatique avec la couche sémantique dans le but de rationaliser les étapes clés du flux de travail d'apprentissage automatique (ML) (par exemple, l'ingénierie des fonctionnalités).
Avec AI-Link, vous pouvez :
- accéder par programmation aux fonctionnalités de votre modèle de données analytiques ;
- faire des requêtes, explorer des dimensions et des mesures ;
- alimenter les pipelines ML ; ... et renvoyez les résultats à votre couche sémantique pour qu'ils soient à nouveau consommés par d'autres (par exemple via Tableau ou Excel).
Comme il s'agit d'une bibliothèque Python, elle peut être utilisée dans n'importe quel environnement Python. Y compris les cahiers.
Et dans cet article, je vais donner un exemple simple pour atteindre la solution Adaptive Analytics de Jupyter Notebook à l'aide d'AI-Link.
Voici le dépôt git qui aura le Notebook complet comme exemple : https://github.com/v23ent/aa-hands-on
Pré-requis
Les autres étapes supposent que vous ayez rempli les conditions préalables suivantes :
- Solution Adaptive Analytics opérationnelle (avec IRIS Data Platform comme Data Warehouse)
- Jupyter Notebook opérationnel
- Une connexion entre 1. et 2. peut être établie
Étape 1 : Configuration
Tout d'abord, installons les composants nécessaires dans notre environnement. Cela téléchargera quelques packages nécessaires pour que les étapes suivantes fonctionnent.
'atscale' - c'est notre package principal pour nous connecter
'prophète' - package dont nous aurons besoin pour faire des prédictions
pip install atscale prophet
Ensuite, nous devrons importer des classes clés représentant certains concepts clés de notre couche sémantique.
Client - classe que nous utiliserons pour établir une connexion à Adaptive Analytics ;
Projet - classe pour représenter les projets dans Adaptive Analytics ;
DataModel - classe qui représentera notre cube virtuel ;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Étape 2 : Connexion
Maintenant, nous devrions être prêts à établir une connexion à notre source de données.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Allez-y et spécifiez les détails de connexion de votre instance Adaptive Analytics. Une fois que l'on vous a demandé de répondre à l'organisation dans la boîte de dialogue, veuillez saisir votre mot de passe de l'instance AtScale.
Une fois la connexion établie, vous devrez ensuite sélectionner votre projet dans la liste des projets publiés sur le serveur. Vous obtiendrez la liste des projets sous forme d'invite interactive et la réponse doit être l'ID entier du projet. Et puis le modèle de données est sélectionné automatiquement s'il est le seul.
project = client.select_project() data_model = project.select_data_model()
Étape 3 : Explorez votre ensemble de données
Il existe un certain nombre de méthodes préparées par AtScale dans la bibliothèque de composants AI-Link. Ils permettent d'explorer le catalogue de données dont vous disposez, d'interroger des données et même d'ingérer certaines données. La documentation AtScale contient une référence API complète décrivant tout ce qui est disponible.
Voyons d'abord quel est notre ensemble de données en appelant quelques méthodes de data_model :
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
Le résultat devrait ressembler à ceci
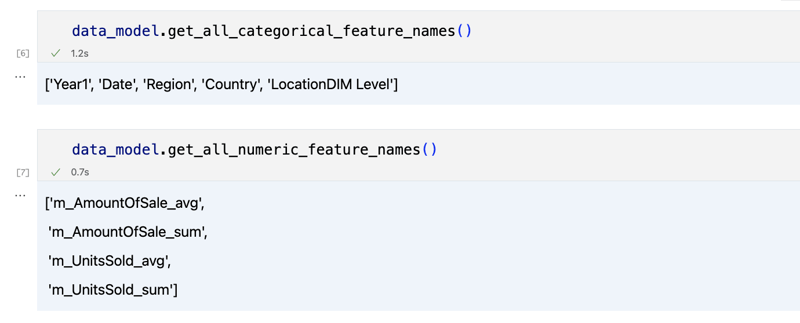
Une fois que nous avons regardé un peu, nous pouvons interroger les données réelles qui nous intéressent en utilisant la méthode 'get_data'. Il renverra un DataFrame pandas contenant les résultats de la requête.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Ce qui affichera votre datadrame :
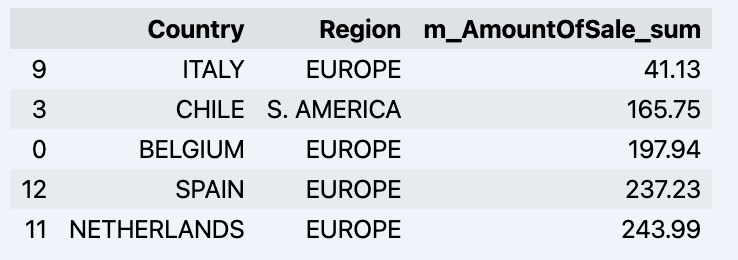
Préparons un ensemble de données et montrons-le rapidement sur le graphique
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Sortie :
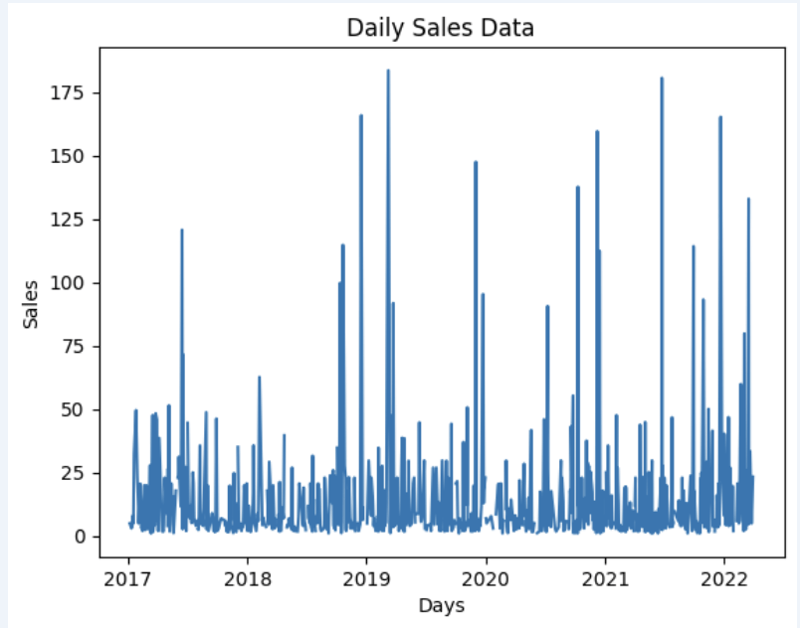
Step 4: Prediction
The next step would be to actually get some value out of AI-Link bridge - let's do some simple prediction!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
We get 2 different datasets here: to train our model and to test it.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
And then we create another dataframe to accomodate our prediction and display it on the graph
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Output:
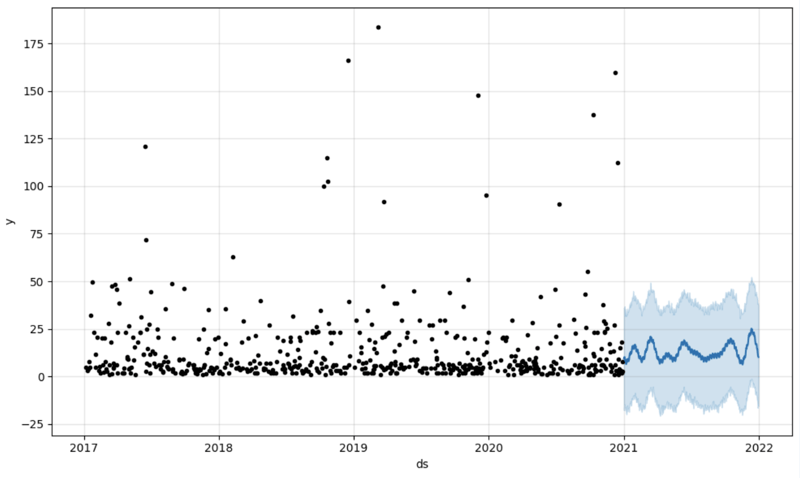
Step 5: Writeback
Once we've got our prediction in place we can then put it back to the data warehouse and add an aggregate to our semantic model to reflect it for other consumers. The prediction would be available through any other BI tool for BI analysts and business users.
The prediction itself will be placed into our data warehouse and stored there.
from atscale.db.connections import Iris<br>
db = Iris(<br>
username,<br>
host,<br>
namespace,<br>
driver,<br>
schema, <br>
port=1972,<br>
password=None, <br>
warehouse_id=None<br>
)
<p>data_model.writeback(dbconn=db,<br>
table_name= 'SalesPrediction',<br>
DataFrame = forecast)</p>
<p>data_model.create_aggregate_feature(dataset_name='SalesPrediction',<br>
column_name='SalesForecasted',<br>
name='sum_sales_forecasted',<br>
aggregation_type='SUM')<br>
</p>
Fin
That is it!
Good luck with your predictions!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!