
Maison >développement back-end >Tutoriel Python >ResNet contre EfficientNet contre VGG contre NN
ResNet contre EfficientNet contre VGG contre NN

- PHPzoriginal
- 2024-08-27 06:06:32418parcourir
En tant qu'étudiant, j'ai été témoin de la frustration causée par le système inefficace des objets trouvés de notre université. Le processus actuel, qui repose sur des e-mails individuels pour chaque objet trouvé, entraîne souvent des retards et des connexions manquées entre les objets perdus et leurs propriétaires.
Motivé par le désir d'améliorer cette expérience pour moi et mes camarades étudiants, je me suis lancé dans un projet visant à explorer le potentiel de l'apprentissage profond pour révolutionner notre système des objets trouvés. Dans cet article de blog, je partagerai mon parcours d'évaluation de modèles pré-entraînés - ResNet, EfficientNet, VGG et NasNet - pour automatiser l'identification et la catégorisation des objets perdus.
Grâce à une analyse comparative, mon objectif est d'identifier le modèle le plus approprié à intégrer dans notre système, créant ainsi une expérience des objets trouvés plus rapide, plus précise et plus conviviale pour tout le monde sur le campus.
ResNet
Inception-ResNet V2 est une puissante architecture de réseau neuronal convolutif disponible dans Keras, combinant les atouts de l'architecture Inception avec les connexions résiduelles de ResNet. Ce modèle hybride vise à atteindre une grande précision dans les tâches de classification d'images tout en maintenant l'efficacité informatique.
Ensemble de données de formation : ImageNet
Format d'image : 299 x 299
Fonction de prétraitement
def readyForResNet(fileName):
pic = load_img(fileName, target_size=(299, 299))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_resnet(expanded)
Prédire
data1 = readyForResNet(test_file) prediction = inception_model_resnet.predict(data1) res1 = decode_predictions_resnet(prediction, top=2)
VGG (Groupe de Géométrie Visuelle)
VGG (Visual Geometry Group) est une famille d'architectures de réseaux neuronaux à convolution profonde connues pour leur simplicité et leur efficacité dans les tâches de classification d'images. Ces modèles, en particulier VGG16 et VGG19, ont gagné en popularité en raison de leurs solides performances lors du ImageNet Large Scale Visual Recognition Challenge (ILSVRC) en 2014.
Ensemble de données de formation : ImageNet
Format d'image : 224 x 224
Fonction de prétraitement
def readyForVGG(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_vgg19(expanded)
Prédire
data2 = readyForVGG(test_file) prediction = inception_model_vgg19.predict(data2) res2 = decode_predictions_vgg19(prediction, top=2)
EfficaceNet
EfficientNet est une famille d'architectures de réseaux neuronaux convolutifs qui atteignent une précision de pointe sur les tâches de classification d'images tout en étant nettement plus petites et plus rapides que les modèles précédents. Cette efficacité est obtenue grâce à une nouvelle méthode de mise à l'échelle composée qui équilibre la profondeur, la largeur et la résolution du réseau.
Ensemble de données de formation : ImageNet
Format d'image : 480 x 480
Fonction de prétraitement
def readyForEF(fileName):
pic = load_img(fileName, target_size=(480, 480))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_EF(expanded)
Prédire
data3 = readyForEF(test_file) prediction = inception_model_EF.predict(data3) res3 = decode_predictions_EF(prediction, top=2)
NasNet
NasNet (Neural Architecture Search Network) représente une approche révolutionnaire en matière d'apprentissage profond où l'architecture du réseau neuronal lui-même est découverte grâce à un processus de recherche automatisé. Ce processus de recherche vise à trouver la combinaison optimale de couches et de connexions pour atteindre des performances élevées sur une tâche donnée.
Ensemble de données de formation : ImageNet
Format d'image : 224 x 224
Fonction de prétraitement
def readyForNN(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_NN(expanded)
Prédire
data4 = readyForNN(test_file) prediction = inception_model_NN.predict(data4) res4 = decode_predictions_NN(prediction, top=2)
Épreuve de force
Précision

Le tableau résume les scores de précision revendiqués pour les modèles ci-dessus. EfficientNet B7 est en tête avec la plus grande précision, suivi de près par NasNet-Large et Inception-ResNet V2. Les modèles VGG présentent des précisions inférieures. Pour mon application, je souhaite choisir un modèle qui présente un équilibre entre temps de traitement et précision.
Temps
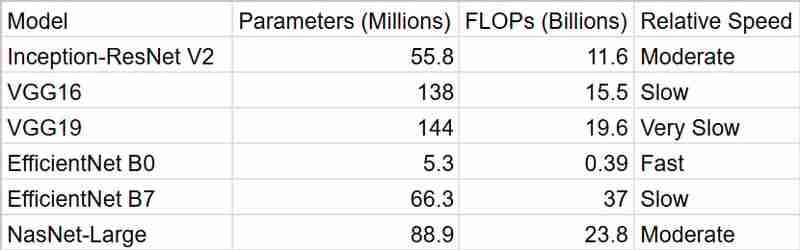
Comme nous pouvons le voir, EfficientNetB0 nous fournit les résultats les plus rapides, mais InceptionResNetV2 est un meilleur package lorsqu'on prend en compte la précision
Résumé
Pour mon système intelligent des objets trouvés, j'ai décidé d'opter pour InceptionResNetV2. Même si EfficientNet B7 semblait tentant avec sa précision de premier ordre, j'étais préoccupé par ses exigences informatiques. Dans un environnement universitaire, où les ressources peuvent être limitées et où les performances en temps réel sont souvent souhaitables, j'ai pensé qu'il était important de trouver un équilibre entre précision et efficacité. InceptionResNetV2 semblait être la solution idéale : il offre de solides performances sans être trop gourmand en calcul.
De plus, le fait qu'il soit pré-entraîné sur ImageNet me donne l'assurance qu'il peut gérer la diversité des objets que les gens pourraient perdre. Et n'oublions pas à quel point il est facile de travailler avec Keras ! Cela a définitivement facilité ma décision.
Dans l'ensemble, je pense qu'InceptionResNetV2 offre le bon mélange de précision, d'efficacité et de praticité pour mon projet. J'ai hâte de voir comment il aide à réunir les objets perdus avec leurs propriétaires !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!