
Maison >développement back-end >Tutoriel Python >Encodage d'étiquettes en ML
Encodage d'étiquettes en ML

- 王林original
- 2024-08-23 06:01:081385parcourir
Le
Label Encoding est l’une des techniques les plus utilisées en apprentissage automatique. Il est utilisé pour convertir les données catégorielles sous forme numérique. Ainsi, les données peuvent être intégrées au modèle.
Comprenons pourquoi nous utilisons le Label Encoding. Imaginez avoir les données, contenant les colonnes essentielles sous forme de chaîne. Mais vous ne pouvez pas intégrer ces données dans le modèle, car la modélisation ne fonctionne que sur des données numériques, que fait-on ? Voici la technique qui sauve des vies et qui est évaluée lors de l'étape de prétraitement lorsque nous préparons les données pour l'ajustement, à savoir le Codage des étiquettes.
Nous utiliserons l'ensemble de données iris de la bibliothèque Scikit-Learn, pour comprendre le fonctionnement de Label Encoder. Assurez-vous que les bibliothèques suivantes sont installées.
pandas scikit-learn
Pour l'installation en tant que bibliothèques, exécutez la commande suivante :
$ python install -U pandas scikit-learn
Ouvrez maintenant Google Colab Notebook et plongez-vous dans le codage et l'apprentissage de Label Encoder.
Codons
- Commencez par importer les bibliothèques suivantes :
import pandas as pd from sklearn import preprocessing
- Importez l'ensemble de données iris et initialisez-le pour l'utiliser :
from sklearn.datasets import load_iris iris = load_iris()
- Maintenant, nous devons sélectionner les données que nous voulons Encoder, nous allons encoder les noms espèces pour les iris.
species = iris.target_names print(species)
Sortie :
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
- Instancions la classe LabelEncoder à partir du prétraitement :
label_encoder = preprocessing.LabelEncoder()
- Maintenant, nous sommes prêts à ajuster les données à l'aide de l'encodeur d'étiquette :
label_encoder.fit(species)
Vous obtiendrez un résultat similaire à ceci :
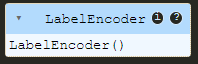
Si vous obtenez ce résultat, vous avez réussi à ajuster les données. Mais la question est de savoir comment découvrir quelles valeurs sont attribuées à chaque espèce et dans quel ordre.
L'ordre dans lequel Label Encoder correspond aux données est stocké dans l'attribut classes_. L'encodage commence de 0 à data_length-1.
label_encoder.classes_
Sortie :
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
L'encodeur d'étiquettes triera automatiquement les données et démarrera l'encodage depuis le côté gauche. Ici :
setosa -> 0 versicolor -> 1 virginica -> 2
- Maintenant, testons les données ajustées. Nous allons transformer l'espèce d'iris setosa.
label_encoder.transform(['setosa'])
Sortie : tableau([0])
Encore une fois, si vous transformez l'espèce virginica.
label_encoder.transform(['virginica'])
Sortie : tableau([2])
Vous pouvez également saisir la liste des espèces, telles que ["setosa", "virginica"]
Documentation Scikit Learn pour l'encodeur d'étiquettes >>>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!