
Maison >Périphériques technologiques >IA >Le premier grand modèle multimodal du MoE auto-développé par la Chine révèle la compréhension multimodale à éléments mixtes de Tencent
Le premier grand modèle multimodal du MoE auto-développé par la Chine révèle la compréhension multimodale à éléments mixtes de Tencent

- 王林original
- 2024-08-22 22:38:25630parcourir

La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com

模 Diagramme schématique de l'architecture du modèle multimodal à éléments mixtes Tencent
Simple et à grande échelle
- Utilisation d'un simple adaptateur MLP : par rapport au précédent adaptateur Q-former grand public, l'adaptateur MLP a moins de perte lors de la transmission des informations.
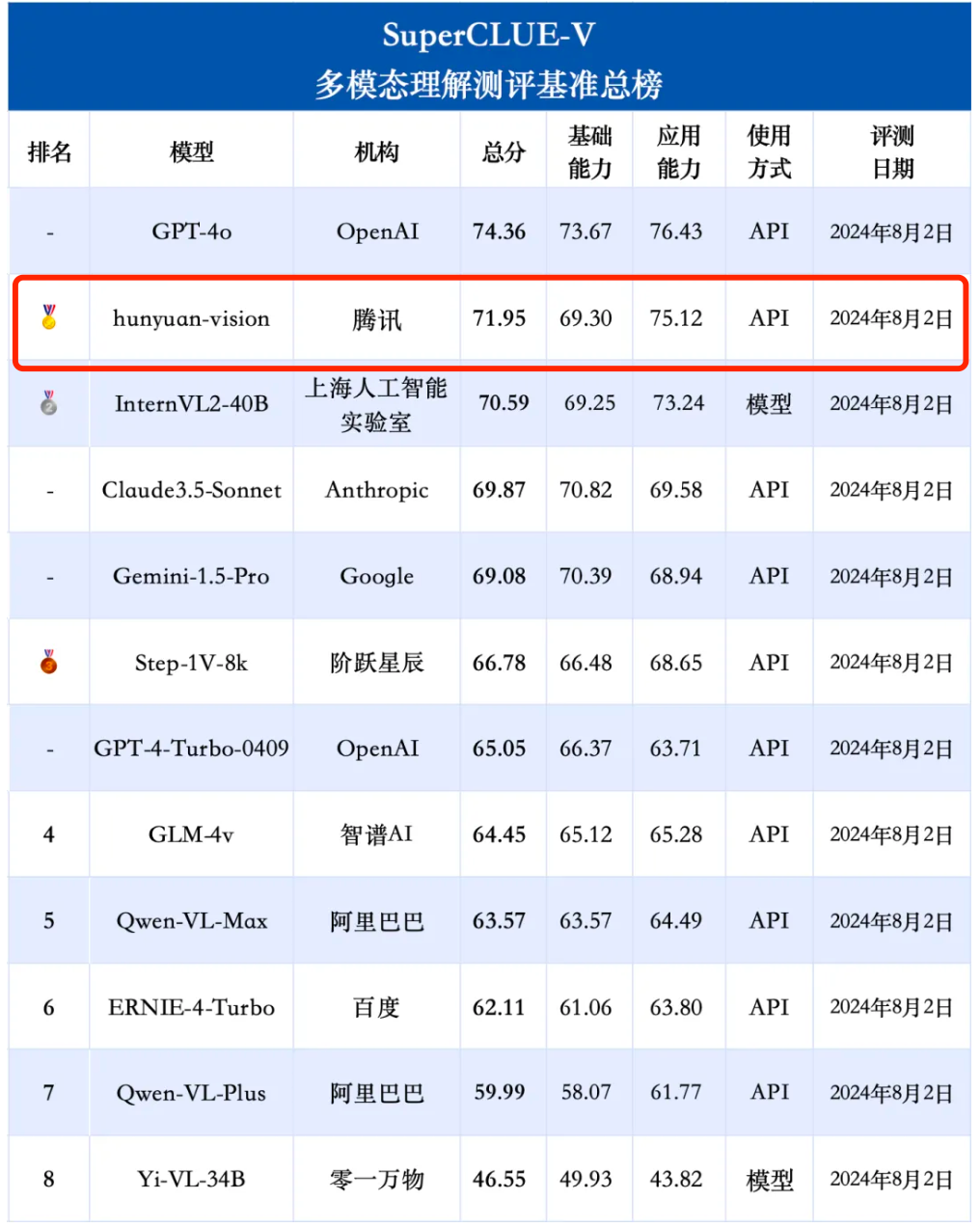
SuperClue-V se classe premier dans la liste nationale
Dans cette évaluation, le système de compréhension multimodale Hunyuan, hunyuan-vision, a obtenu un score de 71,95, juste derrière GPT-4o. En termes d'applications multimodales, hunyuan-vision devance Claude3.5-Sonnet et Gemini-1.5-Pro. 
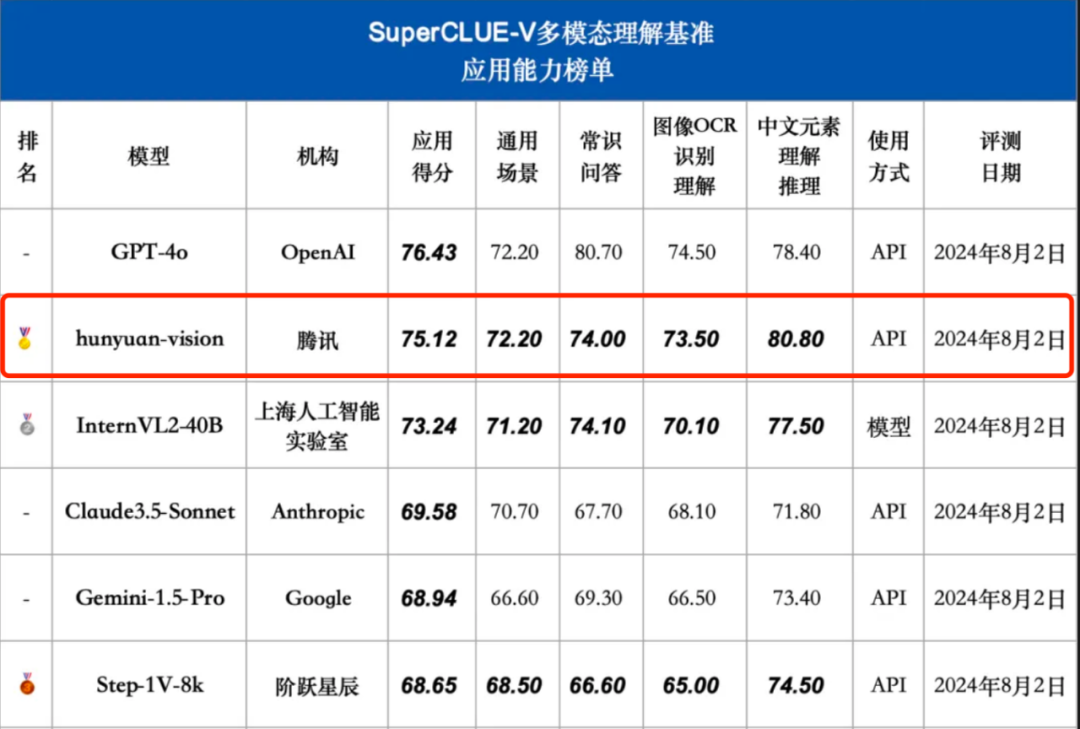
Tencent Hunyuan Graphics and Text Large Model montre de bonnes performances dans plusieurs dimensions telles que les scènes générales, la reconnaissance et la compréhension OCR d'images, ainsi que la compréhension et le raisonnement des éléments chinois, et reflète également le potentiel du modèle dans les applications futures. . 
 Destiné aux scénarios d'application généraux
Destiné aux scénarios d'application généraux
Voici des exemples plus typiques : 
Expliquer un morceau de code : 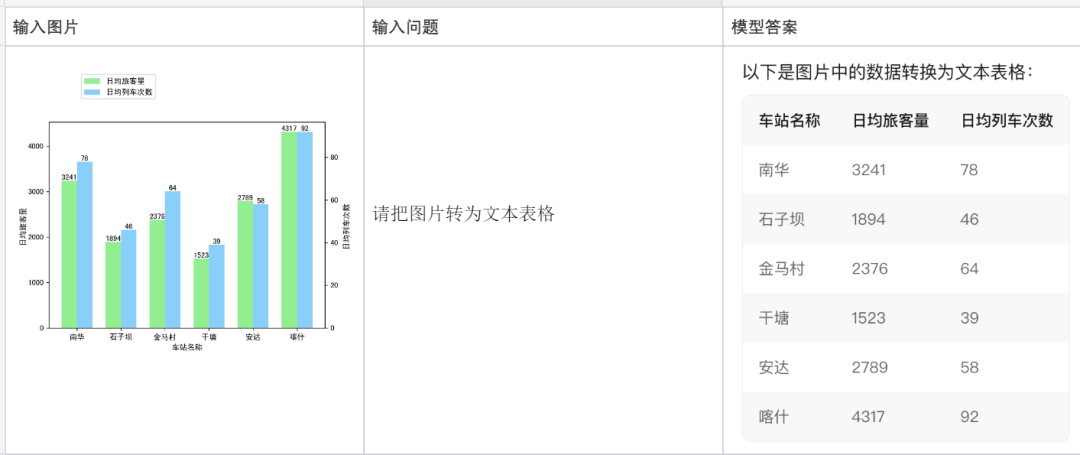
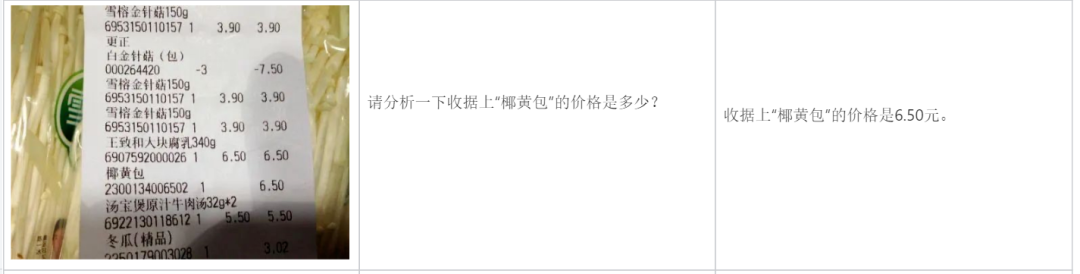
Analyser une facture : 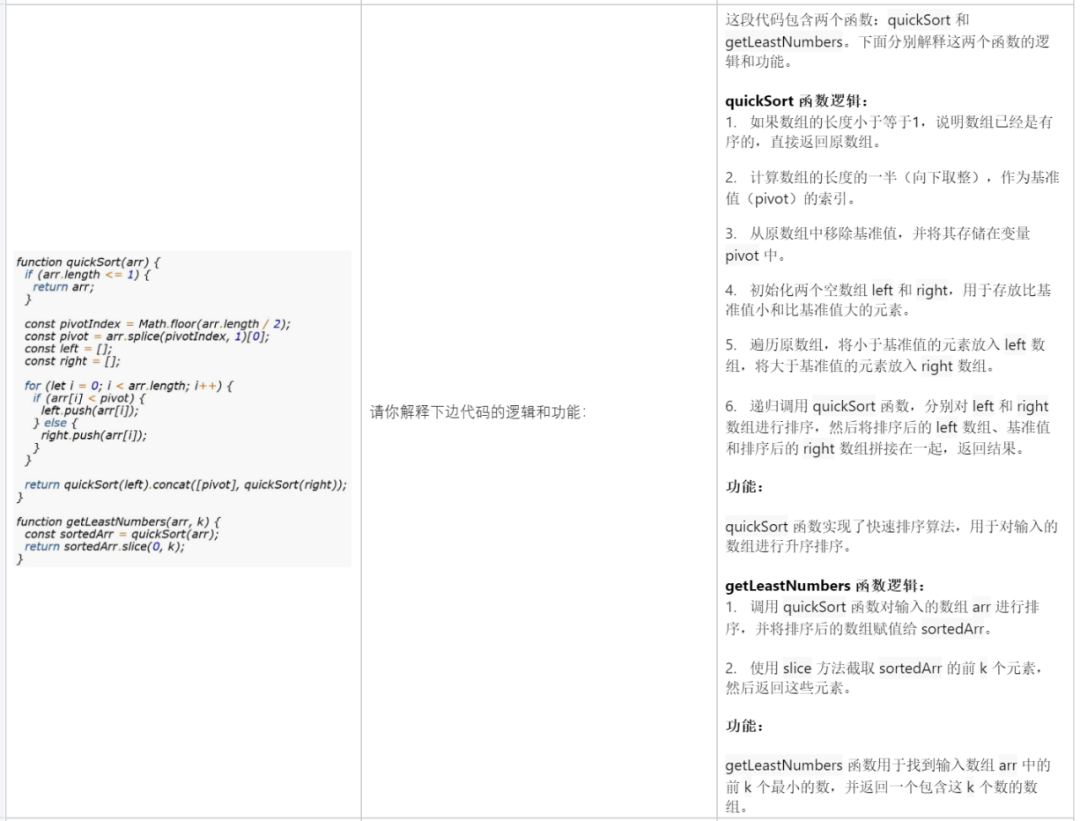
Description Contenu de l'image :
Résoudre des problèmes de mathématiques :

Analyser en fonction du contenu de l'image :
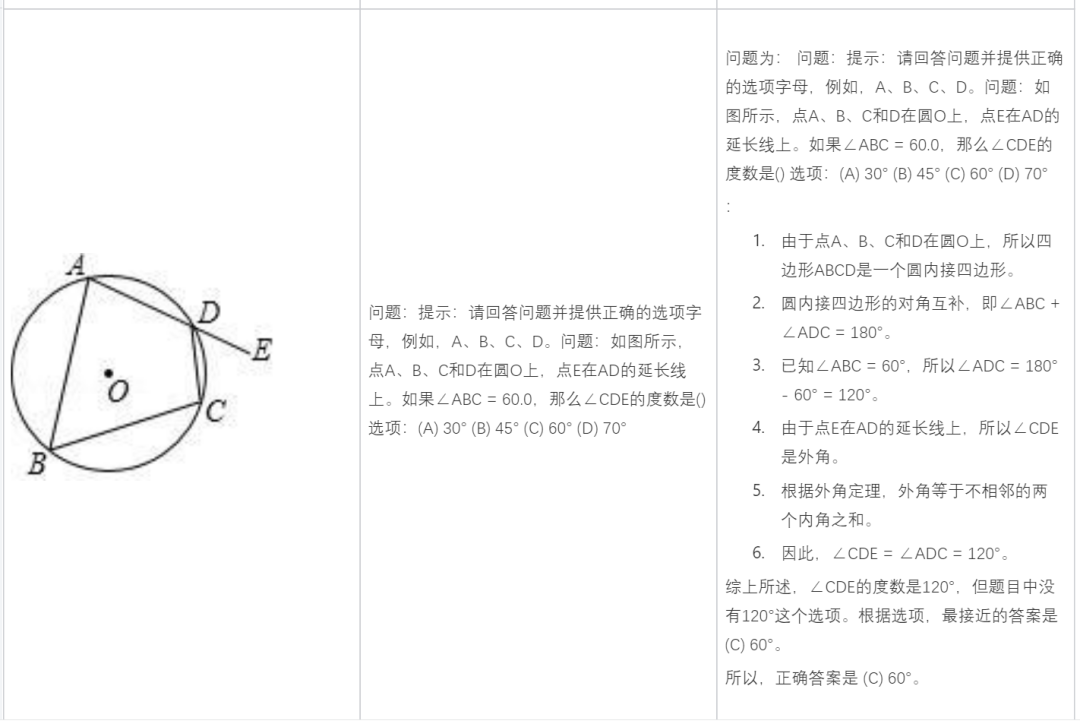
Vous aider à rédiger une copie :

À l'heure actuelle, le grand modèle de compréhension multimodale Hunyuan de Tencent a été lancé dans le produit d'assistant d'IA Tencent Yuanbao et est ouvert aux entreprises et aux développeurs individuels via Tencent Cloud.
Adresse Tencent Yuanbao : https://yuanbao.tencent.com/chat
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI