
Maison >développement back-end >Tutoriel Python >Le guide complet de la compression d'images avec OpenCV
Le guide complet de la compression d'images avec OpenCV

- PHPzoriginal
- 2024-08-21 06:01:321169parcourir
La compression d'images est une technologie essentielle en vision par ordinateur qui nous permet de stocker et de transmettre des images plus efficacement tout en conservant la qualité visuelle. Idéalement, nous aimerions avoir de petits fichiers de la meilleure qualité. Cependant, nous devons faire un compromis et décider lequel est le plus important.
Ce tutoriel enseignera la compression d'images avec OpenCV, couvrant la théorie et les applications pratiques. À la fin, vous comprendrez comment compresser avec succès des photos pour des projets de vision par ordinateur (ou tout autre projet que vous pourriez avoir).
Qu’est-ce que la compression d’images ?
La compression d'image consiste à réduire la taille du fichier d'une image tout en maintenant un niveau acceptable de qualité visuelle. Il existe deux principaux types de compression :
- Compression sans perte : Préserve toutes les données originales, permettant une reconstruction exacte de l'image.
- Compression avec perte : Supprime certaines données pour obtenir des fichiers plus petits, réduisant potentiellement la qualité de l'image.
Pourquoi compresser les images ?
Si « l'espace disque est bon marché », comme nous l'entendons souvent, alors pourquoi compresser les images ? À petite échelle, la compression d’image n’a pas beaucoup d’importance, mais à grande échelle, elle est cruciale.
Par exemple, si vous avez quelques images sur votre disque dur, vous pouvez les compresser et enregistrer quelques mégaoctets de données. Cela n’a pas beaucoup d’impact lorsque les disques durs sont mesurés en téraoctets. Mais que se passerait-il si vous aviez 100 000 images sur votre disque dur ? Une compression de base permet d'économiser du temps et de l'argent. Du point de vue des performances, c'est pareil. Si vous avez un site Web contenant beaucoup d’images et que 10 000 personnes visitent votre site Web par jour, la compression est importante.
Voici pourquoi nous le faisons :
- Exigences de stockage réduites : stockez plus d'images dans le même espace
- Transmission plus rapide : idéal pour les applications Web et les scénarios de bande passante limitée
- Vitesse de traitement améliorée : les images plus petites sont plus rapides à charger et à traiter
Théorie derrière la compression d'image
Les techniques de compression d'images exploitent deux types de redondances :
- Redondance spatiale : Corrélation entre pixels voisins
- Redondance des couleurs : Similitude des valeurs de couleur dans les régions adjacentes
Redondance spatiale profite du fait que les pixels voisins ont tendance à avoir des valeurs similaires dans la plupart des images naturelles. Cela crée des transitions douces. De nombreuses photos « semblent réelles » car il existe un flux naturel d’une zone à l’autre. Lorsque les pixels voisins ont des valeurs très différentes, vous obtenez des images « bruyantes ». Les pixels ont été modifiés pour rendre ces transitions moins « fluides » en regroupant les pixels en une seule couleur, ce qui rend l'image plus petite.

Redondance des couleurs, quant à elle, se concentre sur la façon dont les zones adjacentes d'une image partagent souvent des couleurs similaires. Pensez à un ciel bleu ou à un champ vert : de grandes parties de l'image peuvent avoir des valeurs de couleur très similaires. Ils peuvent également être regroupés et transformés en une seule couleur pour gagner de la place.

OpenCV propose des outils solides pour travailler avec ces idées. Grâce à la redondance spatiale, la fonction cv2.inpaint() d'OpenCV, par exemple, remplit les zones manquantes ou endommagées d'une image en utilisant les informations des pixels proches. OpenCV permet aux développeurs d'utiliser cv2.cvtColor() pour traduire des images entre plusieurs espaces colorimétriques concernant la redondance des couleurs. Cela peut être quelque peu utile en tant qu'étape de prétraitement dans de nombreuses techniques de compression, car certains espaces colorimétriques sont plus efficaces que d'autres pour encoder des types particuliers d'images.
Nous allons tester une partie de cette théorie maintenant. Jouons avec.
Pratique de la compression d'images
Explorons comment compresser des images à l'aide des liaisons Python d'OpenCV. Écrivez ce code ou copiez-le :
Vous pouvez également obtenir le code source ici
import cv2
import numpy as np
def compress_image(image_path, quality=90):
# Read the image
img = cv2.imread(image_path)
# Encode the image with JPEG compression
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), quality]
_, encoded_img = cv2.imencode('.jpg', img, encode_param)
# Decode the compressed image
decoded_img = cv2.imdecode(encoded_img, cv2.IMREAD_COLOR)
return decoded_img
# Example usage
original_img = cv2.imread('original_image.jpg')
compressed_img = compress_image('original_image.jpg', quality=50)
# Display results
cv2.imshow('Original', original_img)
cv2.imshow('Compressed', compressed_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Calculate compression ratio
original_size = original_img.nbytes
compressed_size = compressed_img.nbytes
compression_ratio = original_size / compressed_size
print(f"Compression ratio: {compression_ratio:.2f}")
Cet exemple contient une fonction compress_image qui prend deux paramètres :
- Chemin de l'image (où se trouve l'image)
- Qualité (la qualité de l'image souhaitée)
Ensuite, nous chargerons l'image originale dans original_img. Nous compressons ensuite cette même image de 50 % et la chargeons dans une nouvelle instance, comprimé_image.
Ensuite, nous afficherons les images originales et compressées afin que vous puissiez les voir côte à côte.
Nous calculons et affichons ensuite le taux de compression.
Cet exemple montre comment compresser une image en utilisant la compression JPEG dans OpenCV. Le paramètre de qualité contrôle le compromis entre la taille du fichier et la qualité de l'image.
Exécutons :

While intially looking at the images, you see little difference. However, zooming in shows you the difference in the quality:
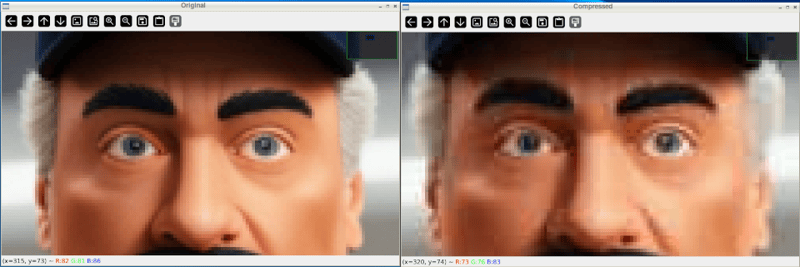
And after closing the windows and looking at the files, we can see the file was reduced in size dramatically:

Also, if we take it down further, we can change our quality to 10%
compressed_img = compress_image('sampleimage.jpg', quality=10)
And the results are much more drastic:
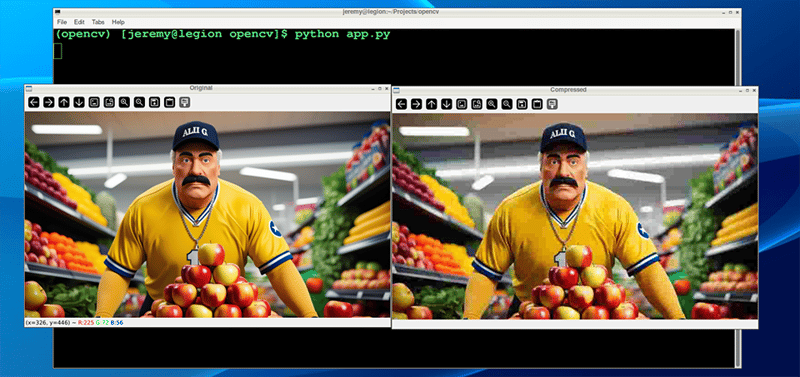
And the file size results are more drastic as well:

You can adjust these parameters quite easily and achieve the desired balance between quality and file size.
Evaluating Compression Quality
To assess the impact of compression, we can use metrics like:
- Mean Squared Error (MSE)
Mean Squared Error (MSE) measures how different two images are from each other. When you compress an image, MSE helps you determine how much the compressed image has changed compared to the original.
It does this by sampling the differences between the colors of corresponding pixels in the two images, squaring those differences, and averaging them. The result is a single number: a lower MSE means the compressed image is closer to the original. In comparison, a higher MSE means there's a more noticeable loss of quality.
Here's some Python code to measure that:
def calculate_mse(img1, img2):
return np.mean((img1 - img2) ** 2)
mse = calculate_mse(original_img, compressed_img)
print(f"Mean Squared Error: {mse:.2f}")
Here's what our demo image compression looks like:

- Peak Signal-to-Noise Ratio (PSNR)
Peak Signal-to-Noise Ratio (PSNR) is a measure that shows how much an image's quality has degraded after compression. This is often visible with your eyes, but it assigns a set value. It compares the original image to the compressed one and expresses the difference as a ratio.
A higher PSNR value means the compressed image is closer in quality to the original, indicating less loss of quality. A lower PSNR means more visible degradation. PSNR is often used alongside MSE, with PSNR providing an easier-to-interpret scale where higher is better.
Here is some Python code that measures that:
def calculate_psnr(img1, img2):
mse = calculate_mse(img1, img2)
if mse == 0:
return float('inf')
max_pixel = 255.0
return 20 * np.log10(max_pixel / np.sqrt(mse))
psnr = calculate_psnr(original_img, compressed_img)
print(f"PSNR: {psnr:.2f} dB")
Here's what our demo image compression looks like:
"Eyeballing" your images after compression to determine quality is fine; however, at a large scale, having scripts do this is a much easier way to set standards and ensure the images follow them.
Let's look at a couple other techniques:
Advanced Compression Techniques
For more advanced compression, OpenCV supports various algorithms:
- PNG Compression:
You can convert your images to PNG format, which has many advantages. Use the following line of code, and you can set your compression from 0 to 9, depending on your needs. 0 means no compression whatsoever, and 9 is maximum. Keep in mind that PNGs are a "lossless" format, so even at maximum compression, the image should remain intact. The big trade-off is file size and compression time.
Here is the code to use PNG compression with OpenCV:
cv2.imwrite('compressed.png', img, [cv2.IMWRITE_PNG_COMPRESSION, 9])
And here is our result:
Note: You may notice sometimes that PNG files are actually larger in size, as in this case. It depends on the content of the image.
- WebP Compression:
You can also convert your images to .webp format. This is a newer method of compression that's gaining in popularity. I have been using this compression on the images on my blog for years.
In the following code, we can write our image to a webp file and set the compression level from 0 to 100. It's the opposite of PNG's scale because 0, because we're setting quality instead of compression. This small distinction matters, because a setting of 0 is the lowest possible quality, with a small file size and significant loss. 100 is the highest quality, which means large files with the best image quality.
Here's the Python code to make that happen:
cv2.imwrite('compressed.webp', img, [cv2.IMWRITE_WEBP_QUALITY, 80])
And here is our result:

These two techniques are great for compressing large amounts of data. You can write scripts to compress thousands or hundreds of thousands of images automatically.
Conclusion
Image compression is fantastic. It's essential for computer vision tasks in many ways, especially when saving space or increasing processing speed. There are also many use cases outside of computer vision anytime you want to reduce hard drive space or save bandwidth. Image compression can help a lot.
By understanding the theory behind it and applying it, you can do some powerful things with your projects.
Remember, the key to effective compression is finding the sweet spot between file size reduction and maintaining acceptable visual quality for your application.
Thanks for reading, and feel free to reach out if you have any comments or questions!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!