
Maison >Tutoriel système >Linux >Opérations récursives dans le développement de logiciels
Opérations récursives dans le développement de logiciels

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-08-16 19:54:301277parcourir

이 고전적인 재귀 계승을 살펴보겠습니다.
으아악재귀 계승 -factorial.c
자신을 호출하는 함수라는 개념은 처음에는 이해하기 어렵습니다. 이 프로세스를 더욱 생생하고 구체적으로 만들기 위해 다음 그림은 계승(5)이 호출되고 코드 n == 1 줄에 도달할 때 스택의 끝점을 보여줍니다.

팩토리얼이 호출될 때마다 새로운 스택 프레임이 생성됩니다. 이러한 스택 프레임의 생성 및 파괴로 인해 재귀 버전이 해당 반복 버전보다 팩터리얼하게 느려집니다. 이러한 스택 프레임이 누적되면 호출이 반환되기 전에 스택 공간이 소진되어 프로그램이 중단될 수 있습니다.
그리고 이러한 걱정은 이론상으로 존재하는 경우가 많습니다. 예를 들어 스택 프레임은 각 계승에 대해 16바이트를 사용합니다(이는 스택 배열 및 기타 요인에 따라 달라질 수 있음). 컴퓨터에서 최신 x86 Linux 커널을 실행하는 경우 일반적으로 스택 공간이 8GB이므로 계승 프로그램의 n은 최대 약 512,000까지 될 수 있습니다. 이는 엄청난 결과이며 이를 표현하는 데 8,971,833비트가 필요하므로 스택 공간은 전혀 문제가 되지 않습니다. 작은 정수(심지어 64비트 정수라도)가 이전에 스택 공간에 수천 번 오버플로되었습니다. 그것은 다 떨어졌다.
CPU의 사용에 대해서는 잠시 살펴보겠습니다. 지금은 비트와 바이트에서 한발 물러나 재귀를 일반적인 기술로 다루겠습니다. 우리의 계승 알고리즘은 정수 N, N-1, … 1을 스택에 푸시하고 역순으로 곱하는 것으로 요약됩니다. 이를 달성하기 위해 실제로 프로그램 호출 스택을 사용합니다. 자세한 내용은 다음과 같습니다. 힙에 스택을 할당하고 사용합니다. 호출 스택에는 특별한 특성이 있지만 원하는 대로 사용할 수 있는 또 다른 데이터 구조일 뿐입니다. 이 다이어그램이 이를 이해하는 데 도움이 되기를 바랍니다.
콜 스택을 데이터 구조로 생각하면 더 명확해집니다. 이러한 정수를 쌓은 다음 곱하는 것은 좋은 생각이 아닙니다. 이는 구현에 결함이 있습니다. 마치 드라이버를 사용하여 못을 박는 것과 같습니다. 계승을 계산하기 위해 반복 프로세스를 사용하는 것이 더 합리적입니다.
그런데 나사가 너무 많아서 하나만 고를 수 있어요. 미로 속에 쥐가 있고 쥐가 치즈 조각을 찾도록 도와야 하는 고전적인 인터뷰 질문이 있습니다. 쥐가 미로에서 왼쪽이나 오른쪽으로 회전할 수 있다고 가정해 보세요. 이 문제를 해결하기 위해 어떻게 모델링합니까?
실생활의 많은 문제와 마찬가지로 치즈를 찾는 쥐의 문제를 그래프로 단순화할 수 있습니다. 이진 트리의 각 노드는 미로에서의 위치를 나타냅니다. 그런 다음 가능하면 마우스를 왼쪽으로 돌리고, 막다른 골목에 도달하면 뒤로 돌아가서 다시 오른쪽으로 돌게 할 수 있습니다. 다음은 미로를 통과하는 마우스의 예입니다.
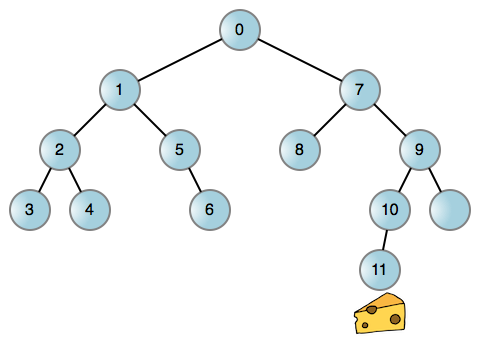
가장자리(선)에 도달할 때마다 마우스를 왼쪽이나 오른쪽으로 돌려 새로운 위치에 도달하세요. 회전하는 방향 중 어느 방향으로든 막히면 해당 모서리가 존재하지 않는다는 의미입니다. 이제 토론해 봅시다! 호출 스택을 사용하든 다른 데이터 구조를 사용하든 이 프로세스는 재귀 프로세스와 분리될 수 없습니다. 그리고 호출 스택을 사용하는 것은 매우 쉽습니다:
으아악재귀 미로 해결 다운로드
maze.c:13에서 치즈를 찾으면 스택은 다음과 같습니다. 또한 명령을 사용하여 수집된 데이터인 GDB 출력에서 더 자세한 데이터를 볼 수도 있습니다.

재귀를 사용하기에 적합한 문제이기 때문에 재귀의 좋은 동작을 보여줍니다. 이는 놀라운 일이 아닙니다. 알고리즘의 경우 재귀는 예외가 아닌 규칙입니다. 이는 검색할 때, 트리 및 기타 데이터 구조를 탐색할 때, 구문 분석할 때, 정렬해야 할 때 등 어디에나 나타납니다. 파이나 e가 우주의 모든 것의 기초이기 때문에 수학에서 "신"으로 알려진 것처럼, 재귀도 동일합니다. 즉, 계산 구조에만 존재합니다.
Steven Skienna의 훌륭한 저서 A Guide to Algorithm Design의 장점은 그가 "전쟁 이야기"를 통해 자신의 작업을 실제 문제 해결 뒤에 숨은 알고리즘을 보여주는 수단으로 해석한다는 것입니다. 이것은 알고리즘에 대한 지식을 확장하는 데 제가 아는 최고의 리소스입니다. 또 다른 자료는 LISP 구현에 관한 McCarthy의 원본 논문입니다. 재귀는 언어의 이름이자 기본 원리입니다. 논문은 읽기 쉽고 흥미롭고, 석사의 작업을 직장에서 보는 것은 매우 흥미롭습니다.
Retour au problème du labyrinthe. Bien qu’il soit difficile de laisser ici la récursion, cela ne signifie pas qu’elle doit être réalisée via la pile d’appels. Vous pouvez utiliser une chaîne comme RRLL pour suivre le tour, puis utiliser cette chaîne pour déterminer le prochain mouvement de la souris. Ou vous pouvez attribuer quelque chose d'autre pour enregistrer l'état complet de la chasse au fromage. Vous implémentez toujours un processus récursif, il vous suffit d'implémenter votre propre structure de données.
Cela semble plus compliqué, car les appels de pile sont plus adaptés. Chaque frame de pile enregistre non seulement le nœud actuel, mais aussi l'état du calcul sur ce nœud (dans ce cas, que nous l'ayons seulement laissé aller vers la gauche, ou que nous ayons essayé d'aller vers la droite). Le code n’a donc plus d’importance. Cependant, nous abandonnons parfois cet excellent algorithme par crainte de débordement et de performances attendues. C'est stupide !
Comme nous pouvons le voir, l'espace de pile est très grand et d'autres limitations sont souvent rencontrées avant que l'espace de pile ne soit épuisé. D’une part, vous pouvez vérifier l’ampleur du problème pour vous assurer qu’il peut être traité en toute sécurité. Les problèmes de processeur sont motivés par deux exemples problématiques largement diffusés : la factorielle stupide et l'horrible récursion de Fibonacci O(2n) sans mémoire. Ce ne sont pas des représentations correctes des algorithmes récursifs de pile.
En fait, les opérations de stack sont très rapides. En règle générale, le décalage de la pile par rapport aux données est très précis, ce sont des données chaudes dans le cache et des instructions spécialisées fonctionnent dessus. Dans le même temps, la surcharge associée à l'utilisation de vos propres structures de données allouées sur le tas est importante. On constate souvent que les gens écrivent des méthodes d'implémentation plus complexes et moins performantes que la récursivité des appels de pile. Enfin, les performances des processeurs modernes sont très bonnes et, en général, le processeur ne constituera pas un goulot d'étranglement en termes de performances. Soyez prudent lorsque vous envisagez de sacrifier la simplicité d’un programme, tout comme vous considérez toujours la performance du programme et la mesure de cette performance.
Le prochain article sera le dernier de la série Exploring Stack. Nous en apprendrons davantage sur les appels de queue, les fermetures et d'autres concepts connexes. Ensuite, il est temps de plonger dans notre vieil ami, le noyau Linux. Merci d'avoir lu!

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Le principe de nettoyage du dossier /tmp/ dans le système Linux et le rôle du fichier tmp
- Explication détaillée du cas de calcul de l'utilisation spécifique du processeur sous Linux
- Comment se déconnecter ou arrêter le système dans Debian 11
- Comment changer le fond d'écran du bureau dans Ubuntu
- Sortie de la version bêta d'Ubuntu 21.04, aperçu de la mise à jour