
Maison >Périphériques technologiques >IA >L'architecture non-Transformer résiste ! Le premier grand modèle pur et sans attention, surpassant le géant open source Llama 3.1
L'architecture non-Transformer résiste ! Le premier grand modèle pur et sans attention, surpassant le géant open source Llama 3.1

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-08-13 16:37:46520parcourir
Le grand modèle de l'architecture Mamba a une nouvelle fois défié Transformer.

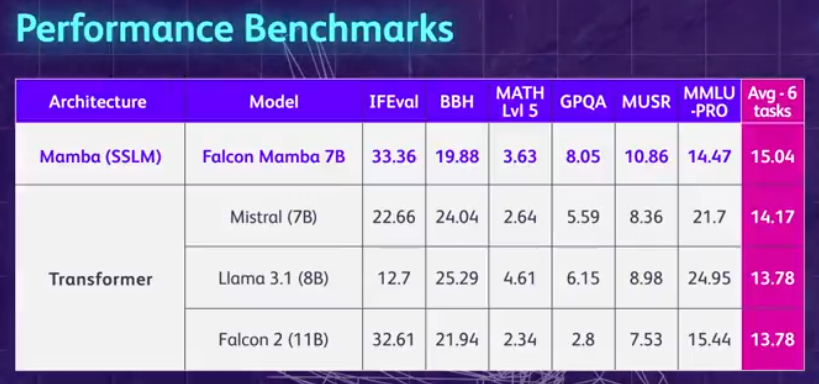



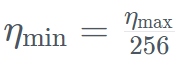 . Dans le même temps, TII utilise BatchScaling dans la phase d'accélération pour réajuster le taux d'apprentissage η afin que la température de bruit d'Adam
. Dans le même temps, TII utilise BatchScaling dans la phase d'accélération pour réajuster le taux d'apprentissage η afin que la température de bruit d'Adam 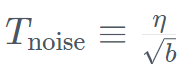 reste constante.
reste constante. 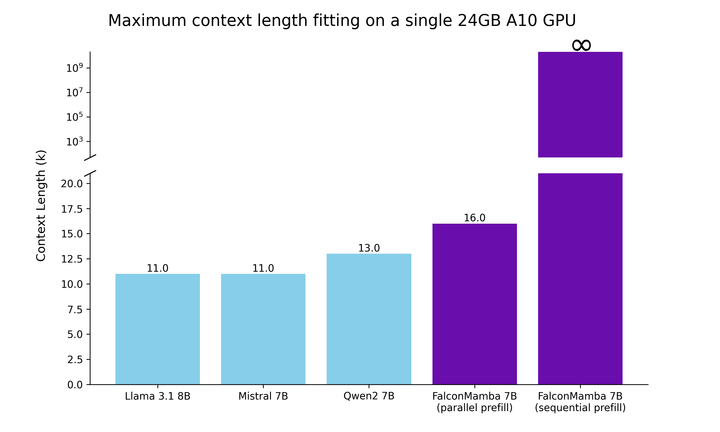
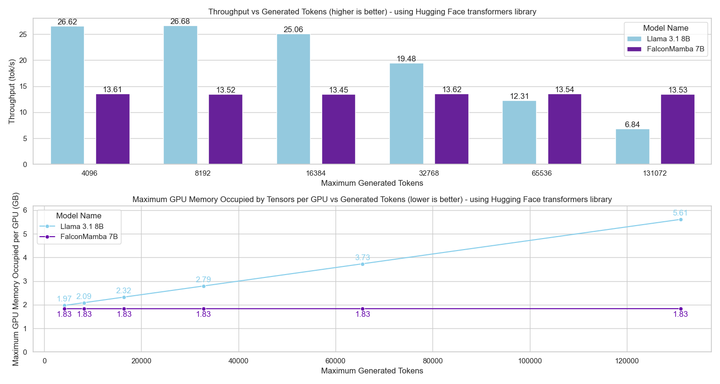
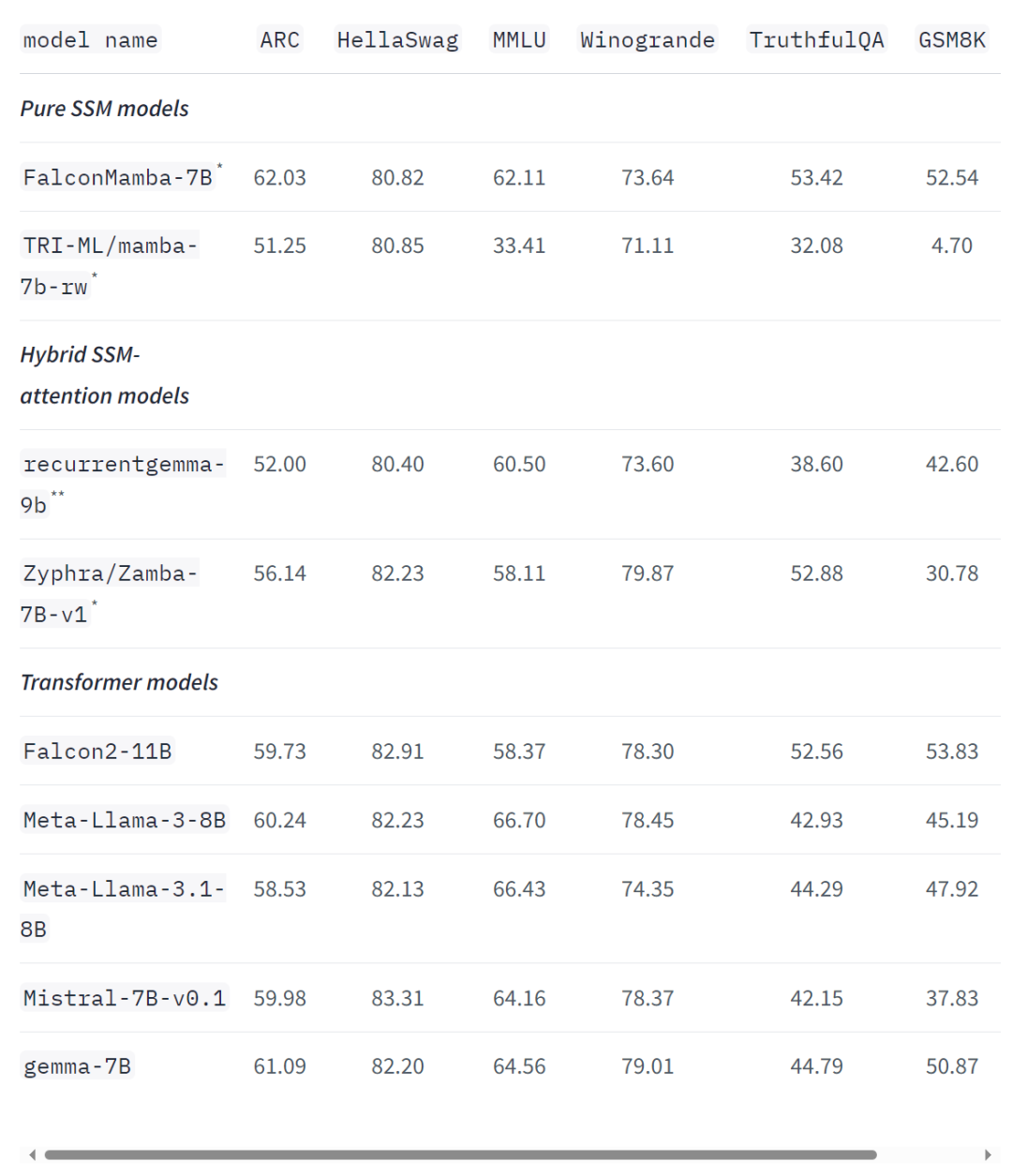

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Le premier modèle TTS à grande échelle prenant en charge la langue mixte du mandarin et des dialectes : le henanais, le shanghaïen et le cantonais peuvent être parlés en douceur.Article suivant:Le premier modèle TTS à grande échelle prenant en charge la langue mixte du mandarin et des dialectes : le henanais, le shanghaïen et le cantonais peuvent être parlés en douceur.
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI