
Maison >Périphériques technologiques >IA >L'IA produit des images plus rapidement, plus belles et comprend mieux vos pensées. Quels secrets techniques le modèle d'image de grande beauté Vincent a-t-il cultivé ?
L'IA produit des images plus rapidement, plus belles et comprend mieux vos pensées. Quels secrets techniques le modèle d'image de grande beauté Vincent a-t-il cultivé ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-08-12 19:02:22690parcourir

Avec le lancement des grands modèles et l'appui sur le bouton de l'accélérateur, les diagrammes vincentiens sont sans aucun doute l'un des domaines d'application les plus en vogue.
Depuis la naissance de Stable Diffusion, il y a eu un flot incessant de grands modèles de Wen Shengtu au pays et à l'étranger, et cela a eu l'impression de « se battre entre dieux » pendant un moment. En quelques mois seulement, le titre de « The Strongest AI Artist » a changé plusieurs fois de mains. Chaque itération technologique continue de repousser la limite supérieure de la qualité et de la vitesse de génération d’images IA.
Alors maintenant, nous pouvons obtenir n'importe quelle image que nous voulons en entrant quelques mots. Qu’il s’agisse d’une affiche commerciale de niveau professionnel ou d’une photo hyper réaliste, la fidélité de la cartographie IA nous a bluffé. Même l’IA a remporté le Sony World Photography Award 2023. Avant l'annonce du grand prix, cette "photo" avait été exposée à Somerset House à Londres - si l'auteur ne la divulguait pas publiquement, personne ne pourrait découvrir que la photo a réellement été créée par l'IA. E Eldagse et sa génération d'IA travaillent "Électricien"
 Comment rendre les images dessinées par l'IA plus belles, ce qui est indissociable de la persévérance des techniciens d'IA.
Comment rendre les images dessinées par l'IA plus belles, ce qui est indissociable de la persévérance des techniciens d'IA. La diffusion en direct a commencé. Li Liang a d'abord disséqué en détail la mise à niveau technique du modèle de diagramme Vincent du récent grand modèle domestique "top-tier" - le grand modèle ByteDance Doubao.
Li Liang a déclaré que les problèmes que l'équipe Doubao souhaite résoudre comprennent principalement trois aspects : premièrement, comment obtenir une correspondance d'image et de texte plus forte pour répondre à l'idée de conception de l'utilisateur ; l'expérience utilisateur ; le troisième est de savoir comment produire des images plus rapidement pour répondre aux appels de service à très grande échelle. En termes de correspondance d'images et de textes, l'équipe Doubao a commencé avec des données, a affiné et filtré les données massives d'images et de textes, et a finalement stocké des centaines de milliards d'images de haute qualité dans la base de données. En outre, l’équipe a également spécialement formé un grand modèle de langage multimodal pour la tâche de récapitulation. Ce modèle décrira de manière plus complète et objective les relations physiques des images dans les images.
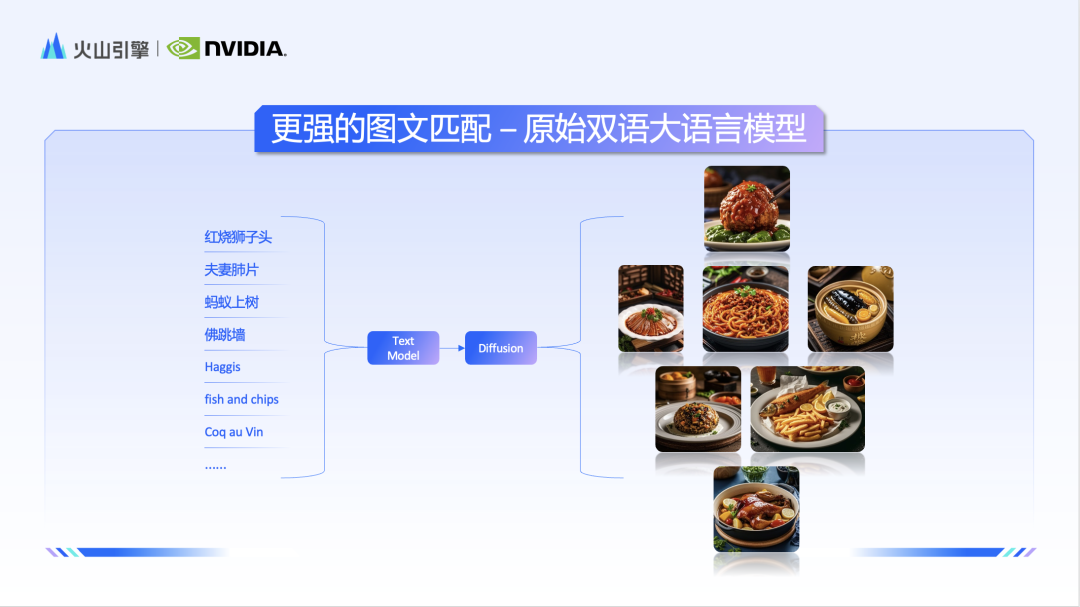
Après avoir obtenu des données d'image et de texte de haute qualité et très détaillées, si vous souhaitez mieux exploiter la force du modèle, vous devez améliorer la capacité du module de compréhension de texte. L'équipe utilise un grand modèle de langue bilingue natif comme encodeur de texte, ce qui améliore considérablement la capacité du modèle à comprendre le chinois. Par conséquent, face à des éléments nationaux tels que la « Dynastie Tang » et la « Fête des Lanternes », les modèles de diagramme Doubao et Vincent. montrer également une compréhension plus profonde.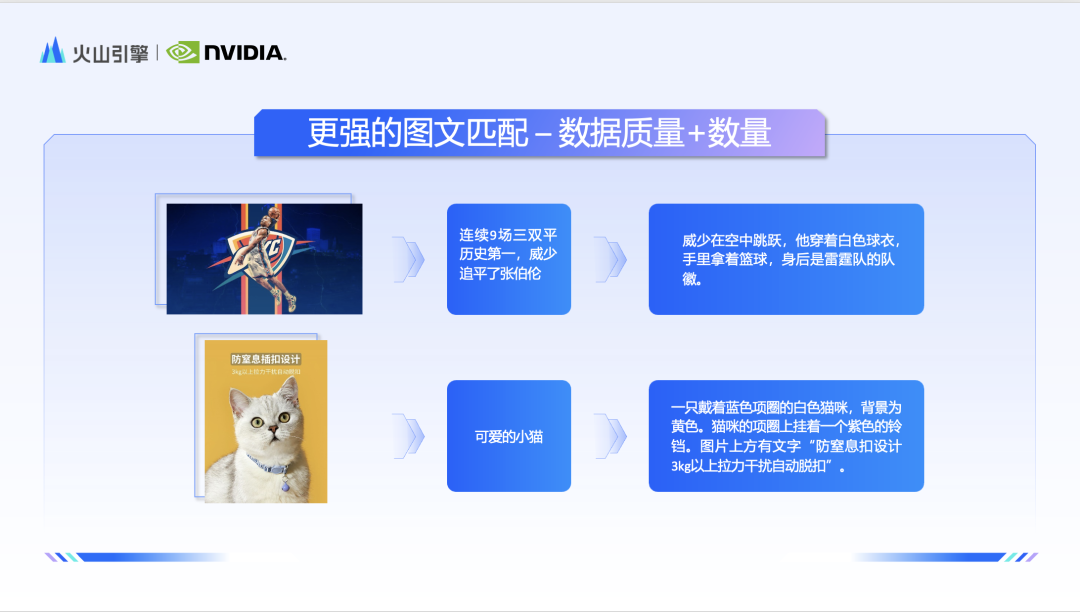
Ensuite, l'architecte de solutions NVIDIA Zhao Yijia est parti de la technologie sous-jacente et a expliqué les deux architectures de modèles SD et DIT basées sur Unet les plus courantes de Vincent Graph et leurs caractéristiques correspondantes, et a présenté les outils Tensorrt, Tensorrt-How de NVIDIA tels que LLM. , Triton et Nemo Megatron prennent en charge le déploiement de modèles et aident les grands modèles à raisonner plus efficacement.
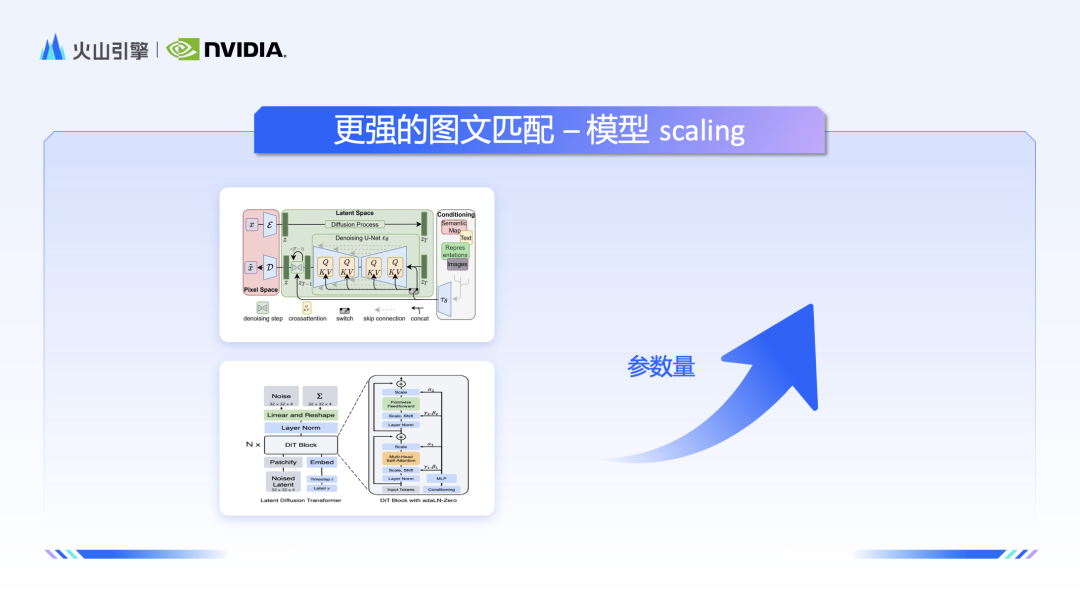
Zhao Yijia a d'abord partagé une explication détaillée des principes du modèle derrière Stable Diffusion et a développé les principes de fonctionnement des composants clés tels que Clip, VAE et Unet. Au fur et à mesure que Sora est devenu populaire, il est également devenu populaire avec l'architecture DiT (Diffusion Transformer) derrière lui. Zhao Yijia a en outre effectué une comparaison complète des avantages du SD et du DiT sous trois aspects : la structure du modèle, les caractéristiques et la consommation d'énergie de calcul.
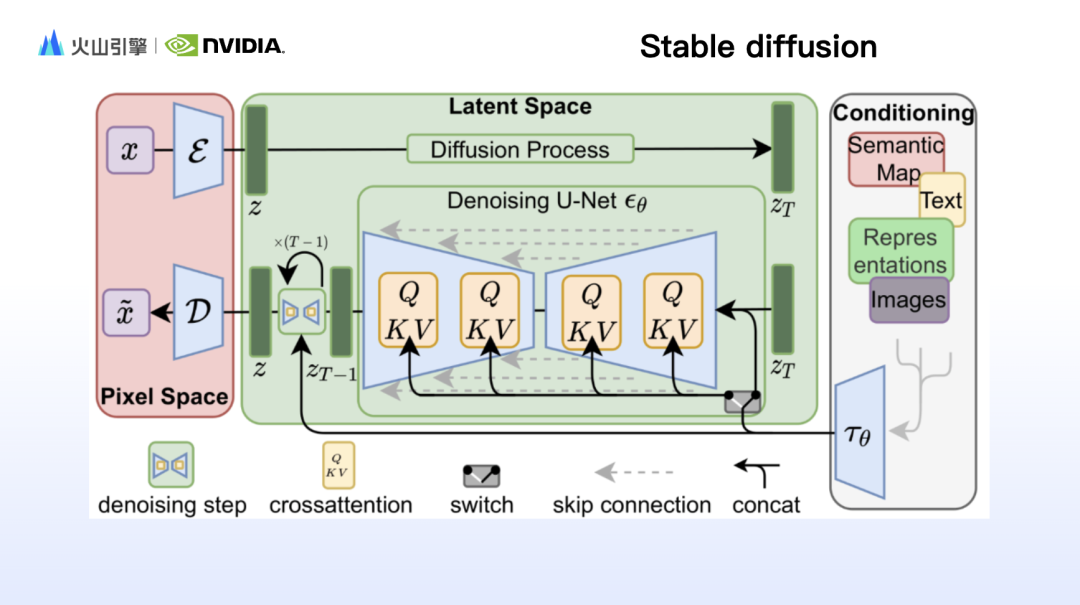
Lorsque vous utilisez la diffusion stable pour générer des images, vous avez souvent l'impression que le contenu du mot invite est présenté dans les résultats générés, mais l'image n'est pas ce que vous voulez. En effet, la diffusion stable basée sur le rendu du texte n'est pas bonne. contrôler les détails des images, tels que la composition, le mouvement, les traits du visage, les relations spatiales, etc. Par conséquent, sur la base du principe de fonctionnement de la diffusion stable, les chercheurs ont conçu de nombreux modules de contrôle pour combler les lacunes de la diffusion stable. Zhao Yijia a ajouté l'adaptateur IP représentatif et ControlNet. 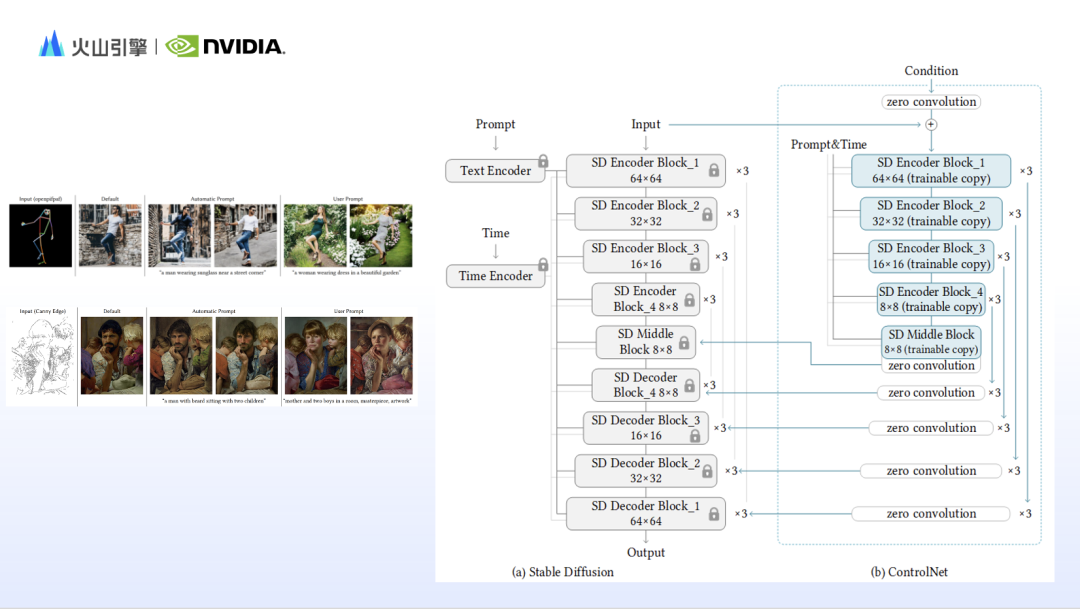
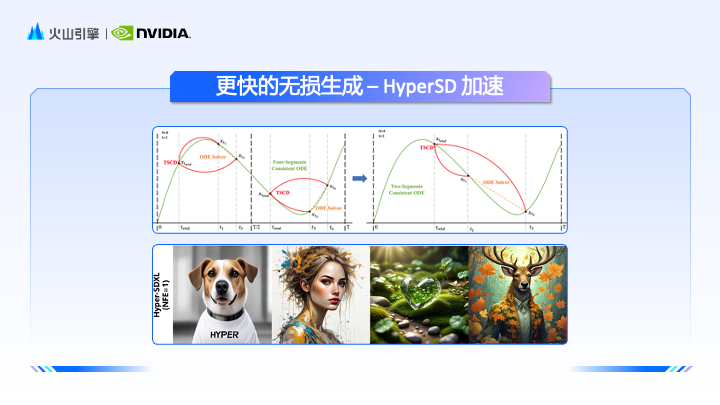
Si nous voulons accélérer la vitesse d'inférence du modèle de graphe Vincent exigeant en termes de calcul, le support technique de NVIDIA joue un rôle clé. Zhao Yijia a présenté les outils Nvidia TensorRT et TensorRT-LLM, qui optimisent le processus d'inférence des modèles de génération d'images et de texte grâce à une convolution haute performance, une planification efficace et des technologies de déploiement distribué. Dans le même temps, Ada, Hopper de NVIDIA et la prochaine architecture matérielle BlackWell prennent déjà en charge la formation et l'inférence FP8, ce qui apportera une expérience plus fluide à la formation des modèles.

Après six merveilleuses diffusions en direct, la "AIGC Experience Party" lancée conjointement par Volcano Engine, NVIDIA, ce site et CMO CLUB s'est conclue avec succès. Grâce à ces six épisodes, je pense que tout le monde comprend mieux comment l'AIGC passe d'« intéressant » à « utile ». Nous attendons également avec impatience que « l'AIGC Experience School » non seulement reste dans la discussion sur le programme, mais accélère également le processus de mise à niveau intelligente dans le domaine du marketing dans la pratique.
Adresse de révision des six numéros de "AIGC Experience School" : https://vtizr.xetlk.com/s/7CjTy
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI