As the iteration speed of large models becomes faster and faster, the scale of training clusters becomes larger and larger, and high-frequency software and hardware failures have become pain points that hinder the further improvement of training efficiency. The checkpoint system is responsible for the status during the training process. Storage and recovery have become the key to overcoming training failures, ensuring training progress and improving training efficiency.
Recently, the ByteDance Beanbao model team and the University of Hong Kong jointly proposed ByteCheckpoint. This is a large model checkpointing system native to PyTorch, compatible with multiple training frameworks, and supports efficient reading and writing of checkpoints and automatic re-segmentation. Compared with existing methods, it has significant performance improvements and ease-of-use advantages. This article introduces the challenges faced by Checkpoint in improving large model training efficiency, summarizes ByteCheckpoint’s solution ideas, system design, I/O performance optimization technology, and experimental results in storage performance and read performance testing.
Meta officials recently disclosed the failure rate of Llama3 405B training on 16384 H100 80GB training clusters - in just 54 days, 419 interruptions occurred, with an average crash every three hours, attracting the attention of many practitioners. .
As a common saying in the industry says, the only certainty for large-scale training systems is software and hardware failure. As the training scale and model size increase, overcoming software and hardware failures and improving training efficiency have become important influencing factors for large model iterations.
Checkpoint has become the key to improving training efficiency. In the Llama training report, the technical team mentioned that in order to combat the high failure rate, frequent checkpoints need to be performed during the training process to save the status of the model, optimizer, and data reader during training to reduce the loss of training progress.
The ByteDance Beanbao large model team and the University of Hong Kong recently released the results - ByteCheckpoint, a PyTorch native, compatible with multiple training frameworks, and a large model Checkpointing system that supports efficient reading and writing of Checkpoint and automatic re-segmentation.
Compared with the baseline method, ByteCheckpoint improves performance by up to 529.22 times on checkpoint saving and up to 3.51 times on loading. The minimalist user interface and Checkpoint automatic re-segmentation function significantly reduce user acquisition and usage costs and improve the ease of use of the system.
The results of the paper have now been made public. 
- ByteCheckpoint : un système de points de contrôle unifié pour le développement LLM
- Lien papier : https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from =recherche
Défis techniques de la technologie Checkpoint dans la formation de grands modèles Les technologies actuelles liées à Checkpoint sont confrontées à un total de quatre défis pour soutenir l'efficacité de la formation de grands modèles : - La conception du système existant présente des défauts, ce qui augmente considérablement la surcharge d'E/S supplémentaire de la formation
Dans le processus de formation de grands modèles de langage (LLM) de niveau industriel, le statut de formation doit passer la technologie des points de contrôle ( Checkpointing) pour la sauvegarde et la persistance. Normalement, un point de contrôle se compose de 5 parties (modèle, optimiseur, lecteur de données, nombre aléatoire et configuration définie par l'utilisateur). Ce processus entraîne souvent un blocage de quelques minutes dans l'entraînement, ce qui affecte sérieusement son efficacité. Dans les scénarios de formation à grande échelle utilisant des systèmes de stockage persistants à distance, le système Checkpointing existant n'utilise pas pleinement la copie de la mémoire GPU vers le CPU (copie D2H), la sérialisation, la sauvegarde locale et le téléchargement vers le stockage pendant le processus de sauvegarde du point de contrôle. . Indépendance d'exécution de chaque étape du système. De plus, le potentiel de traitement parallèle de différents processus de formation partageant les tâches d'accès à Checkpoint n'a pas été entièrement exploré. Ces déficiences de conception du système augmentent la surcharge d’E/S supplémentaire causée par la formation Checkpoint. - Checkpoint est difficile à re-segmenter, et les frais de développement et de maintenance du script de segmentation manuelle sont trop élevés
Dans les différentes étapes de formation du LLM (pré-formation à SFT ou RLHF) et différentes tâches (depuis lors de la migration des points de contrôle entre les tâches de formation (extraction des points de contrôle de différentes étapes pour une évaluation automatique), il est généralement nécessaire de re-segmenter les points de contrôle enregistrés dans le système de stockage persistant (Checkpoint Resharding) pour s'adapter au nouveau parallélisme. configuration des tâches en aval et des quotas pour les ressources GPU disponibles. Les systèmes de points de contrôle existants [1, 2, 3, 4] supposent tous que la configuration du parallélisme et les ressources GPU restent inchangées pendant le stockage et le chargement, et ne peuvent pas gérer le besoin de re-segmentation des points de contrôle. Une solution courante actuellement dans l'industrie consiste à personnaliser les scripts de fusion ou de redécoupage de Checkpoint pour différents modèles. Cette méthode entraîne beaucoup de frais de développement et de maintenance et est peu évolutive. - Les modules Checkpoint des différents cadres de formation sont fragmentés, ce qui pose des défis à la gestion unifiée et à l'optimisation des performances de Checkpoint
Sur la plateforme de formation de l'industrie, les ingénieurs et les scientifiques sont souvent travaillez ensemble en fonction des caractéristiques de la tâche, sélectionnez le framework approprié (Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9]) pour la formation et enregistrez le point de contrôle sur le système de stockage. Cependant, ces différents cadres de formation disposent de leurs propres formats de points de contrôle et de modules de lecture et d’écriture indépendants. Les conceptions des modules de point de contrôle des différents cadres de formation sont différentes, ce qui pose des défis pour la gestion unifiée des points de contrôle et l'optimisation des performances du système sous-jacent. - Les utilisateurs de systèmes de formation distribués sont confrontés à de multiples problèmes
Du point de vue des utilisateurs de systèmes de formation (chercheurs ou ingénieurs en IA), lorsque les utilisateurs utilisent des systèmes de formation distribués, la direction du point de contrôle est souvent troublé par trois problèmes : 1) Comment stocker efficacement les points de contrôle et sauvegarder les points de contrôle sans affecter l'efficacité de l'entraînement. 2) Comment re-segmenter le Checkpoint et le lire correctement selon le nouveau parallélisme du Checkpoint stocké sous un degré de parallélisme. 3) Comment télécharger les produits formés sur un système de stockage cloud (HDFS, S3, etc.) et gérer manuellement plusieurs systèmes de stockage, ce qui est coûteux à apprendre et à utiliser pour les utilisateurs. En réponse aux problèmes ci-dessus, l'équipe modèle ByteDance Beanbao et le laboratoire du professeur Wu Chuan de l'Université de Hong Kong ont lancé conjointement ByteCheckpoint. ByteCheckpoint est un système de points de contrôle distribué hautes performances qui est unifié avec plusieurs cadres de formation, prend en charge plusieurs backends de stockage et a la capacité de re-segmenter automatiquement les points de contrôle. ByteCheckpoint fournit une interface utilisateur simple et facile à utiliser, implémente un grand nombre de technologies d'optimisation des performances d'E/S pour améliorer les performances des points de contrôle de stockage et de lecture, et prend en charge la migration flexible des points de contrôle dans les tâches avec différentes configurations de parallélisme. ByteCheckpoint adopte une architecture de stockage séparée par métadonnées/teneurs pour réaliser le découplage de la gestion et du cadre de formation de Checkpoint et du parallélisme.Tensor slices (Tensor Shard) of models in different training frameworks and optimizers are stored in storage files, and meta information (TensorMeta, ShardMeta, ByteMeta) is stored in a globally unique metadata file.
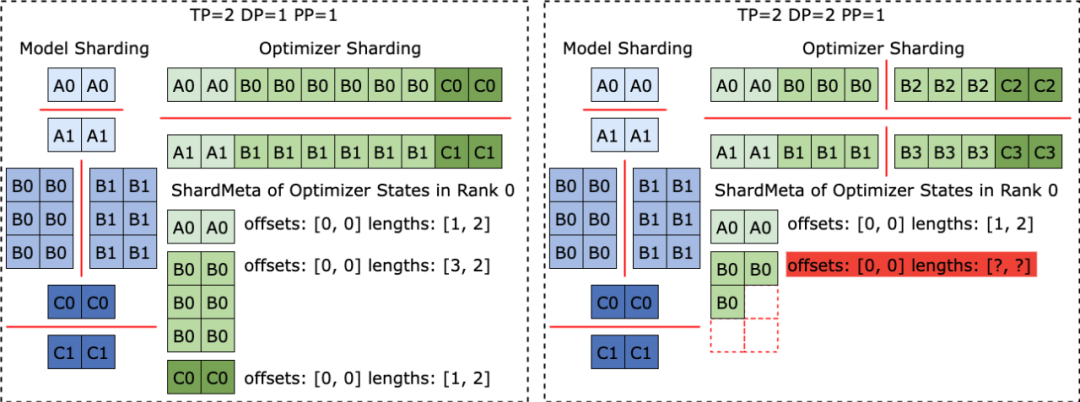
When using different parallelism configurations to read Checkpoint, as shown in the figure below, each training process only needs to set the query meta-information according to the current parallelism to obtain the storage location of the tensor required by the process. Then read directly according to the position to realize automatic checkpoint re-segmentation.
Clever solution to irregular tensor segmentationWhen different training frameworks are running, they often flatten the shape of the tensor in the model or optimizer into one dimension, thereby improving the set Communication performance. This flattening operation brings the challenge of irregular tensor sharding (Irregular Tensor Sharding) to Checkpoint storage. As shown in the figure below, in Megatron-LM (distributed large model training framework developed by NVIDIA) and veScale (PyTorch native distributed large model training framework developed by ByteDance), the model parameters correspond to The optimizer state will be flattened into one dimension, merged, and then split according to data parallelism. This results in tensors being irregularly split into different processes, and the meta-information of tensor slices cannot be represented using offset and length tuples, making storage and reading difficult.
The problem of irregular tensor segmentation also exists in the FSDP framework. To eliminate irregularly cut tensor slices, the FSDP framework will perform all-gather set communication and D2H copy operations on one-dimensional tensor slices on all processes before storing Checkpoints to obtain complete irregular cuts. divided tensor. This solution brings huge communication and frequent GPU-CPU synchronization overhead, which seriously affects the performance of Checkpoint storage. To address this problem, ByteCheckpoint proposed the Asynchronous Tensor Merging technology. ByteCheckpoint first finds out the irregularly split tensors in different processes, and then uses asynchronous P2P communication to distribute these irregular tensors to different processes for merging. All P2P communication waits (Wait) and tensor D2H copy operations for these irregular tensors are postponed until they are about to enter the serialization phase, thereby eliminating frequent synchronization overhead and increasing communication with other Checkpoint storage processes. Perform overlap. The following figure shows the system architecture of ByteCheckpoint: The API layer provides simple, easy-to-use and unified reading and writing for different training frameworks ( Save ) and read (Load) interface. The Planner layer will generate access plans for different training processes based on the access objects, and hand them over to the Execution layer to perform the actual I/O tasks. The Execution layer performs I/O tasks and interacts with the Storage layer, using various I/O optimization technologies for high-performance checkpoint access. The Storage layer manages different storage backends and performs corresponding optimizations according to different storage backends during I/O tasks. The layered design enhances the scalability of the system to support more training frameworks and storage backends in the future.
ByteCheckpoint’s API use cases are as follows:
ByteCheckpoint fournit une API minimaliste, réduisant le coût de démarrage pour l'utilisateur. Lors du stockage et de la lecture des points de contrôle, les utilisateurs n'ont qu'à appeler les fonctions de stockage et de chargement, en transmettant le contenu à stocker et à lire, le chemin du système de fichiers et diverses options d'optimisation des performances. Technologie d'optimisation des performances d'E/SOptimisation du stockage CheckpointComme le montre la figure ci-dessous, Conception d'un pipeline de stockage entièrement asynchrone ( Save Pipeline), divise les différentes étapes du stockage Checkpoint (transfert de tenseur P2P, réplication D2H, sérialisation, sauvegarde des systèmes de fichiers locaux et téléchargement) pour obtenir une exécution efficace du pipeline.
Évitez les allocations de mémoire répétéesDans le processus de copie D2H, ByteCheckpoint utilise un pool de mémoire épinglé (Pinned Memory Pool), ce qui réduit le temps nécessaire aux allocations de mémoire répétées. De plus, afin de réduire le temps supplémentaire causé par l'attente synchrone du recyclage du pool de mémoire fixe dans les scénarios de stockage haute fréquence, ByteCheckpoint ajoute un mécanisme de mise en mémoire tampon Ping-Pong basé sur le pool de mémoire fixe. Deux pools de mémoire indépendants jouent alternativement le rôle de tampons de lecture et d'écriture, interagissant avec le GPU et les processeurs d'E/S qui effectuent les opérations d'E/S ultérieures, améliorant ainsi l'efficacité du stockage.
Dans la formation parallèle aux données (Data-Parallel ou DP), le modèle est redondant entre différents groupes de processus parallèles aux données (le groupe DP adopte un algorithme d'équilibrage de charge répartissant uniformément les redondances). modélisez des tenseurs pour différents groupes de processus pour le stockage, améliorant ainsi efficacement l'efficacité du stockage Checkpoint. Optimisation de la lecture du point de contrôleChargement redondant zéroComme le montre la figure, lors du changement du parallélisme pour lire le point de contrôle, le nouveau processus de formation peut n'avoir besoin que de démarrer à partir du original Lisez-en une partie à partir d'une tranche tensorielle. ByteCheckpoint utilise la technologie de lecture partielle de fichiers à la demande (Partial File Reading) pour lire directement les fragments de fichiers requis à partir du stockage distant afin d'éviter de télécharger et de lire des données inutiles.
Dans la formation aux données parallèles (Data-Parallel ou DP), le modèle est redondant entre différents groupes de processus parallèles de données (groupe DP), et différents groupes de processus liront à plusieurs reprises la même tranche de tenseur. Dans les scénarios de formation à grande échelle, différents groupes de processus envoient simultanément un grand nombre de requêtes à des systèmes de stockage persistants distants (tels que HDFS), ce qui exercera une pression énorme sur le système de stockage. Afin d'éliminer la lecture répétée des données, de réduire les requêtes envoyées à HDFS par le processus de formation et d'optimiser les performances de chargement, ByteCheckpoint distribue uniformément les mêmes tâches de lecture de tranches de tenseur à différents processus et lit les fichiers distants lors de la récupération. , la bande passante inactive entre les GPU est utilisée pour la transmission des tranches de tenseur.
Configuration experimentale - L'équipe utilise des modèles densegpt et clairsemés (implémentés sur la base de la structure GPT-3 [10]), avec différents montants de paramètres de modèle et différents cadres de formation L'exactitude de l'accès à Checkpoint, les performances de stockage et les performances de lecture de ByteCheckpoint ont été évaluées dans des tâches de formation de différentes tailles. Pour plus de détails sur la configuration expérimentale et les tests d'exactitude, veuillez vous référer au document complet.
팀은 교육 과정에서 다양한 모델 크기와 교육 프레임워크를 비교했으며 총 50단계 또는 100단계마다 Checkpoint, Bytecheckpoint 및 Baseline 방법을 저장했습니다. 훈련으로 인한 차단 시간(체크포인트 지연)입니다. 심층적인 쓰기 성능 최적화 덕분에 ByteCheckpoint는 다양한 실험 시나리오에서 높은 성능을 달성했습니다. 576카드 SparseGPT 110B - Megatron-LM 교육 작업에서 ByteCheckpoint는 기준보다 10% 더 높은 성능을 달성했습니다. 저장 방법의 성능 향상은 66.65~74.55배이며, 256카드 DenseGPT 10B-FSDP 교육 작업에서는 529.22배의 성능 향상도 달성할 수 있습니다.
읽기 성능 테스트에서 팀은 다운스트림 작업의 병렬성을 기반으로 체크포인트를 읽는 다양한 방법의 로딩 시간을 비교했습니다. ByteCheckpoint는 기준 방법에 비해 1.55~3.37배의 성능 향상을 달성합니다. 팀은 Megatron-LM 기준 방법에 비해 ByteCheckpoint의 성능 향상이 더 중요하다는 것을 관찰했습니다. 이는 Megatron-LM이 체크포인트를 새로운 병렬 구성으로 읽기 전에 분산 체크포인트를 다시 샤딩하기 위해 오프라인 스크립트를 실행해야 하기 때문입니다. 반면 ByteCheckpoint는 오프라인 스크립트를 실행하지 않고도 자동 체크포인트 재분할을 직접 수행하고 효율적으로 읽기를 완료할 수 있습니다.
마지막으로 ByteCheckpoint의 향후 계획과 관련하여 팀은 두 가지 측면에서 시작하기를 희망합니다. 첫째, 초대형 GPU 클러스터 훈련 작업에 대한 효율적인 체크포인트를 지원한다는 장기 목표를 달성합니다. 두 번째, 사전 훈련(Pre-Training)부터 감독된 미세 조정(SFT), 강화 학습(RLHF)에 이르기까지 모든 시나리오에서 체크포인트를 지원하여 대규모 모델 훈련의 전체 수명 주기에 대한 체크포인트 관리를 실현합니다. ) 및 평가(Evaluation) 및 기타 시나리오. ByteDance Beanbao 빅 모델 팀은 2023년에 설립되었습니다. 업계에서 가장 앞선 AI 빅 모델 기술을 개발하고, 기술과 사회 발전에 기여합니다. 현재 팀은 계속해서 뛰어난 인재를 유치하고 있습니다. 하드코어하고 개방적이며 혁신적인 정신이 가득한 것이 팀 분위기의 키워드입니다. 팀은 긍정적인 작업 환경을 조성하고 팀원을 격려하기 위해 최선을 다하고 있습니다. 계속해서 배우고 성장하며, 도전을 두려워하지 않고 최고를 추구하는 것입니다. 대형 모델 교육의 효율성 향상을 촉진하고 더 많은 발전과 성과를 달성하기 위해 혁신적인 정신과 책임감을 갖춘 기술 인재와 협력하기를 바랍니다. [1] Mohan, Jayashree, Amar Phanishayee 및 Vijay Chidambaram "{CheckFreq}: 빈번한 {Fine-Grained}{DNN} 체크포인트." File and Storage Technologies(FAST 21).[2] Eisenman, Assaf, et al. "{Check-N-Run}: 딥 러닝 추천 모델 학습을 위한 체크포인트 시스템." 네트워크 시스템 설계 및 구현(NSDI 22).[3] Wang, Zhuang, et al. "Gemini: 제29차 심포지엄을 통한 분산 교육의 빠른 실패 복구" 2023.[4] Gupta, Tanmaey, et al. "적시 체크포인트: 딥 러닝 훈련 실패로부터의 저비용 오류 복구." Systems. 2024.[5] Shoeybi, Mohammad, et al. "Megatron-lm: 모델 병렬성을 사용하여 수십억 개의 매개변수 언어 모델 훈련." arXiv 사전 인쇄 arXiv:1909.08053(2019). [6] Zhao, Yanli 외. "Pytorch fsdp: 완전히 샤딩된 데이터 병렬 확장에 대한 경험." arXiv 사전 인쇄 arXiv:2304.11277(2023).[7] Rasley, Jeff, 외. "Deepspeed: 시스템 최적화를 통해 1,000억 개가 넘는 매개변수를 사용하여 딥 러닝 모델을 훈련할 수 있습니다." 2020년 제26회 ACM SIGKDD 국제 지식 발견 및 데이터 마이닝 컨퍼런스 진행.[8] Jiang, Ziheng, et al. "{MegaScale}: 10,000개 이상의 {GPU}로 확장 훈련 프레임워크 https://github.com/volcengine/veScale[10] Brown, Tom, et al. "언어 모델은 소수의 학습자입니다." 신경 정보 처리 시스템의 발전 33(2020) ) : 1877-1901.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn