
Maison >Périphériques technologiques >IA >La recherche multimodale d'ACM MM2024 | NetEase Fuxi a de nouveau acquis une reconnaissance internationale, favorisant de nouvelles avancées dans la compréhension intermodale dans des domaines spécifiques
La recherche multimodale d'ACM MM2024 | NetEase Fuxi a de nouveau acquis une reconnaissance internationale, favorisant de nouvelles avancées dans la compréhension intermodale dans des domaines spécifiques

- 王林original
- 2024-08-07 20:16:121292parcourir

- L'orientation de recherche de cet article implique la pré-formation du langage visuel (VLP), la récupération intermodale d'images et de textes (CMITR) et d'autres domaines. Cette sélection marque la nouvelle reconnaissance internationale des capacités multimodales de NetEase Fuxi Lab. Actuellement, la technologie pertinente a été appliquée à l'assistant intelligent multimodal auto-développé par NetEase Fuxi, « Dan Qing Yue ».
- ACM MM a été initiée par l'Association for Computing Machinery (ACM). Il s'agit de la conférence internationale la plus influente dans le domaine du traitement, de l'analyse et de l'informatique multimédia. C'est également une conférence universitaire internationale de classe A dans le domaine du multimédia recommandée. par la Fédération informatique chinoise. En tant que conférence de premier plan dans le domaine, l'ACM MM a reçu une large attention de la part de fabricants et d'universitaires de renom au pays et à l'étranger. L'ACM MM de cette année a reçu un total de 4 385 manuscrits valides, dont 1 149 ont été acceptés par la conférence, avec un taux d'acceptation de 26,20 %.
En tant qu'institution de recherche leader sur l'intelligence artificielle en Chine, NetEase Fuxi a accumulé près de six ans d'expérience dans la recherche de modèles à grande échelle, possède une riche expérience en matière d'algorithmes et d'ingénierie et a créé des dizaines de modèles de texte et de pré-formation multimodaux. inclure de grands modèles pour la compréhension et la génération de texte, de grands modèles pour la compréhension d'images et de texte, de grands modèles pour la génération d'images et de texte, etc. Ces réalisations favorisent non seulement efficacement l'application de grands modèles dans le domaine du jeu, mais constituent également une base solide pour le développement de capacités de compréhension intermodale. Les capacités de compréhension intermodale aident à mieux intégrer les connaissances de plusieurs domaines et à aligner les modalités et informations riches en données.

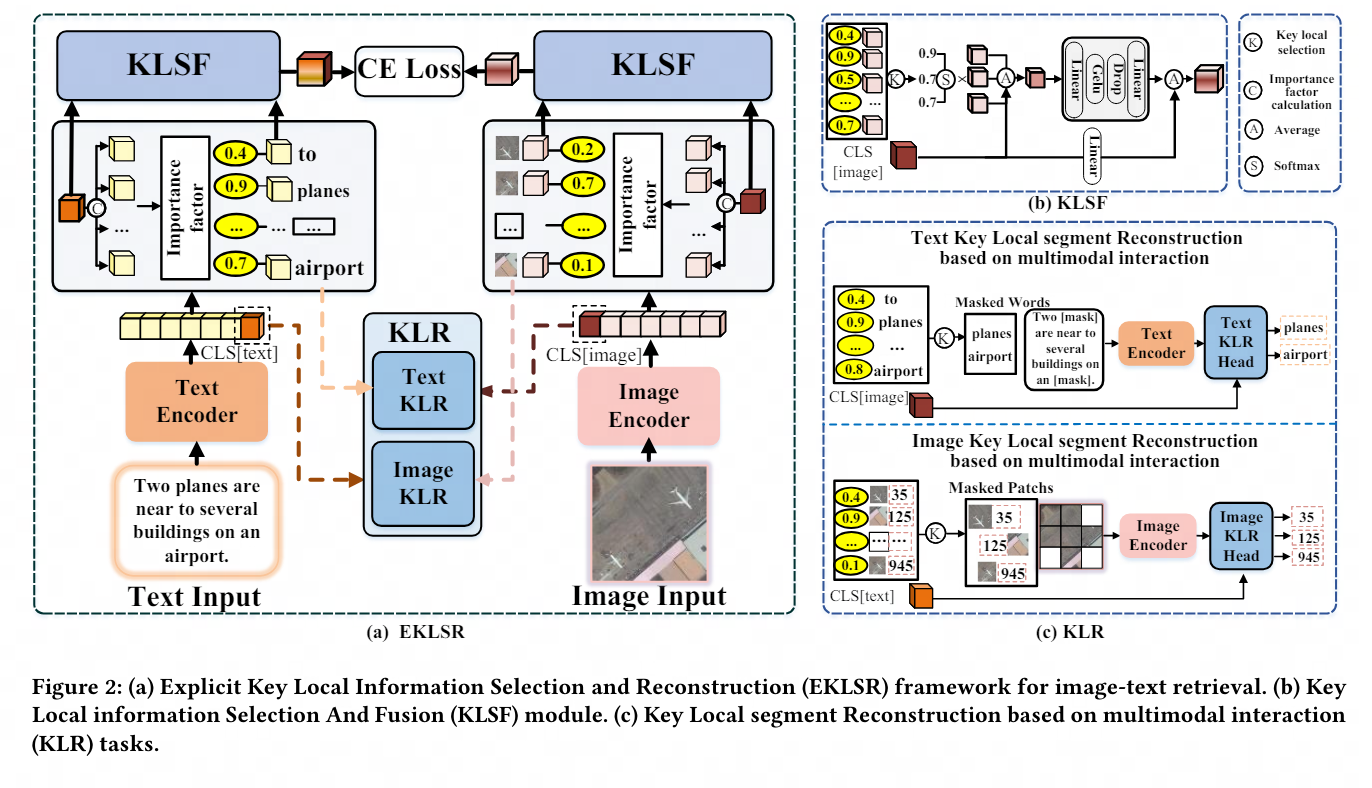
Sur cette base, NetEase Fuxi a innové davantage en s'appuyant sur le grand modèle de compréhension d'image et de texte, et a proposé une méthode de récupération multimodale basée sur la sélection et la reconstruction d'informations locales clés pour résoudre le texte d'image dans des champs spécifiques pour des applications multi-modales. les agents modaux. Les problèmes d’interaction posent les bases techniques.
Ce qui suit est un résumé des articles sélectionnés :
"Sélection et reconstruction des éléments locaux clés : une nouvelle méthode de récupération d'images et de textes spécifiques à un domaine"
Sélection et reconstruction d'informations locales clés : une nouvelle image et un texte spécifiques à un domaine méthode de récupération
Mots clés : informations locales clés, fines, interprétables
Domaines impliqués : pré-entraînement au langage visuel (VLP), récupération intermodale d'images et de textes (CMITR)
Ces dernières années, avec le pré-entraînement au langage visuel -formation (Vision- Avec l'essor des modèles de pré-entraînement linguistique (VLP), des progrès significatifs ont été réalisés dans le domaine de la récupération multimodale d'images et de textes (CMITR). Bien que les modèles VLP comme CLIP fonctionnent bien dans les tâches CMITR générales du domaine, leurs performances sont souvent insuffisantes dans la récupération d'images et de textes de domaine spécifique (SDITR). En effet, un domaine spécifique possède souvent des caractéristiques de données uniques qui le distinguent du domaine général.
Dans un domaine spécifique, les images peuvent présenter un degré élevé de similitude visuelle entre elles, tandis que les différences sémantiques ont tendance à se concentrer sur des détails locaux clés, tels que des zones d'objets spécifiques dans l'image ou des mots significatifs dans le texte. Même de petits changements dans ces segments locaux peuvent avoir un impact significatif sur l'ensemble du contenu, soulignant l'importance de ces informations locales cruciales. Par conséquent, SDITR nécessite que le modèle se concentre sur des fragments d'informations locaux clés pour améliorer l'expression des caractéristiques de l'image et du texte dans un espace de représentation partagé, améliorant ainsi la précision de l'alignement entre les images et le texte.
Ce sujet explore l'application de modèles de pré-entraînement au langage visuel dans les tâches de récupération d'image-texte dans des domaines spécifiques, et étudie la question de l'utilisation des fonctionnalités locales dans les tâches de récupération d'image-texte dans des domaines spécifiques. La principale contribution est de proposer une méthode pour exploiter des informations locales discriminantes à granularité fine afin d'optimiser l'alignement des images et du texte dans un espace de représentation partagé.
À cette fin, nous concevons un cadre explicite de sélection et de reconstruction des informations locales clés et une stratégie de reconstruction de segments locaux clés basée sur une interaction multimodale. Ces méthodes utilisent efficacement des informations locales discriminantes à granularité fine, améliorant ainsi considérablement l'image et l'étendue et la suffisance. des expériences sur la qualité de l'alignement du texte dans un espace partagé démontrent l'avancement et l'efficacité de la stratégie proposée.
Un merci tout spécial au laboratoire IPIU de l'Université des sciences et technologies électroniques de Xi'an pour son solide soutien et sa contribution importante à la recherche à cet article.
Actuellement, les capacités de compréhension multimodale de NetEase Fuxi ont été largement utilisées dans plusieurs départements commerciaux du groupe NetEase, notamment NetEase Leihuo, NetEase Cloud Music, NetEase Yuanqi, etc. Ces applications couvrent une variété de scénarios tels qu'un gameplay innovant de pincement de visage basé sur du texte dans les jeux, la recherche de ressources multimodales, des recommandations de contenu personnalisées, etc., démontrant une énorme valeur commerciale.
À l'avenir, avec l'approfondissement de la recherche et les progrès technologiques, cette réalisation devrait promouvoir l'application généralisée de la technologie de l'intelligence artificielle dans l'éducation, les soins médicaux, le commerce électronique et d'autres secteurs, offrant aux utilisateurs une expérience de service plus personnalisée et plus intelligente. . NetEase Fuxi continuera également à approfondir les échanges et la coopération avec les meilleures institutions universitaires du pays et de l'étranger, à mener une exploration approfondie dans des domaines de recherche plus de pointe, à promouvoir conjointement le développement de la technologie de l'intelligence artificielle et à contribuer à la construction d'un système plus efficace et plus intelligent. société.
Scannez le code QR ci-dessous pour vivre immédiatement le « Rendez-vous Photo » et profiter de l'expérience interactive multimodale avec des images et des textes qui « vous comprennent mieux » !

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI