La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Le premier auteur de cet article est Cai Wenxiao, un étudiant diplômé de l'Université de Stanford. Auparavant, il a obtenu un baccalauréat de l'Université du Sud-Est. le score de première année. Ses intérêts de recherche portent sur les grands modèles multimodaux et l’intelligence incorporée. Ce travail a été réalisé lors de sa visite à l'Université Jiao Tong de Shanghai et de son stage à l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin. Son superviseur était le professeur Zhao Bo, l'auteur correspondant de cet article. Auparavant, le professeur Li Feifei a proposé le concept d'intelligence spatiale. En réponse, des chercheurs de l'Université Jiao Tong de Shanghai, de l'Université de Stanford, de l'Université de Zhiyuan, de l'Université de Pékin, de l'Université d'Oxford et de l'Université de Dongda ont proposé le grand modèle spatial SpatialBot. Il a également proposé les données de formation SpatialQA et la liste de tests SpatialBench, essayant de permettre aux grands modèles multimodaux de comprendre la profondeur et l'espace dans des scénarios généraux et des scénarios incorporés. 
- Titre de l'article : SpatialBot : Compréhension précise de la profondeur avec des modèles de langage de vision
- Lien de l'article : https://arxiv.org/abs/2406.13642
- Page d'accueil du projet : https://github. com/BAAI-DCAI/SpatialBot
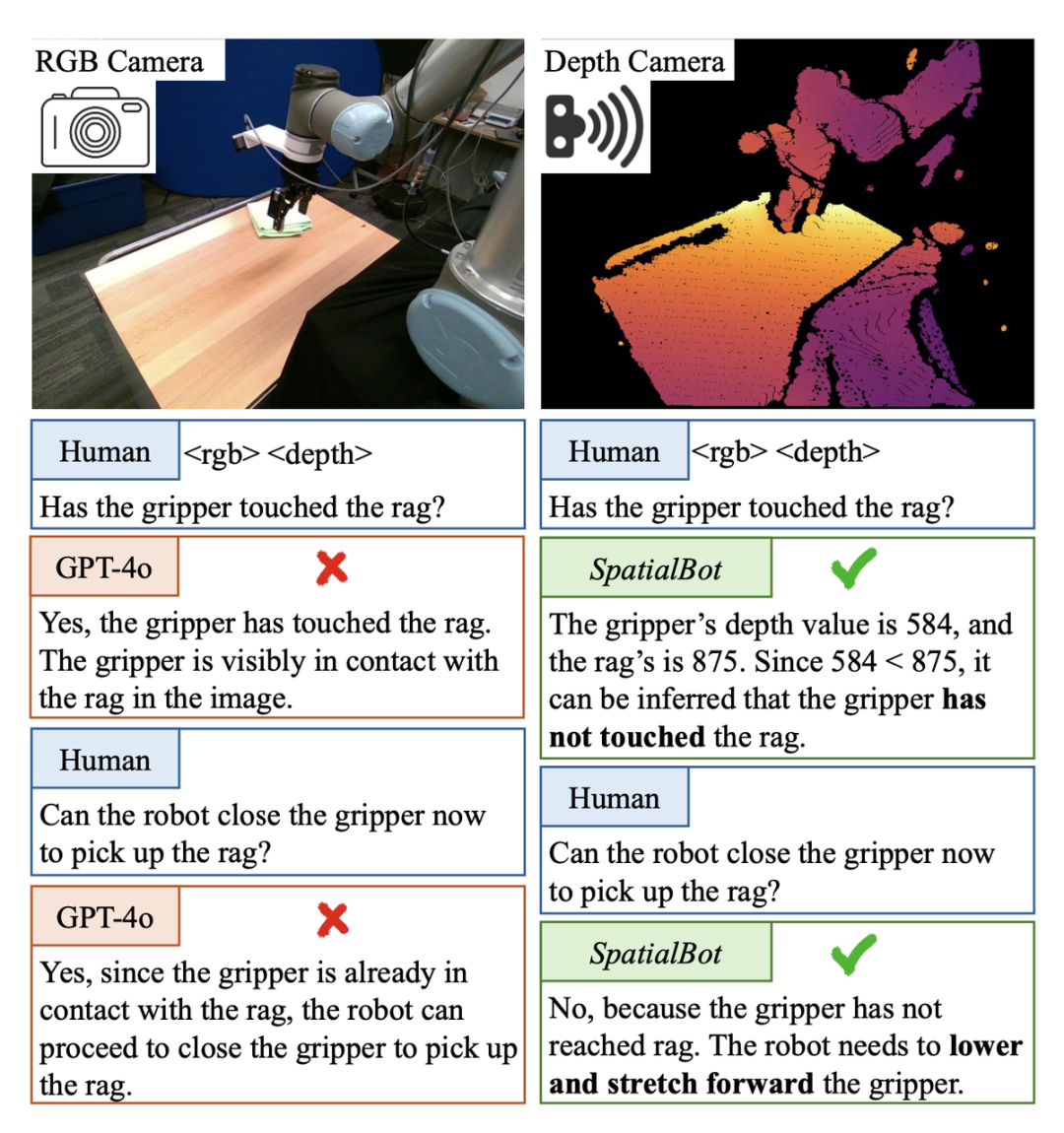
Dans la tâche de sélection et de placement de l'intelligence incarnée, il est nécessaire de déterminer si la griffe mécanique a touché l'objet cible. Si vous le rencontrez, vous pouvez fermer vos griffes et l'attraper. Cependant, dans cette scène de l'ensemble de données de démonstration Berkerly UR5, même GPT-4o ou les humains ne peuvent pas déterminer si la griffe mécanique a touché l'objet cible à partir d'une seule image RVB. Par exemple, à l'aide des informations de profondeur, la carte de profondeur peut être directement obtenue. montré à GPT-4o. Si tel est le cas, il ne peut pas être jugé car il ne peut pas comprendre la carte de profondeur. SpatialBot peut obtenir avec précision les valeurs de profondeur de la griffe mécanique et de l'objet cible grâce à sa compréhension de la profondeur RVB, générant ainsi une compréhension des concepts spatiaux.
SpatialBot Démo de la scène incarnée : Le nuage de points est relativement cher et les caméras binoculaires doivent être étalonnées fréquemment pendant leur utilisation. En revanche, les caméras de profondeur sont abordables et largement utilisées. Dans des scénarios généraux, même sans un tel équipement matériel, les modèles d'estimation de la profondeur de formation non supervisée à grande échelle peuvent déjà fournir des informations de profondeur relativement précises. Par conséquent, les auteurs proposent d’utiliser RGBD comme entrée dans des modèles spatialement vastes.
Quels sont les problèmes du parcours technique actuel ?
Les modèles existants ne peuvent pas comprendre directement l'entrée de la carte de profondeur. Par exemple, l'encodeur d'image CLIP/SigLIP est entraîné sur des images RVB sans jamais voir de cartes de profondeur.
- La plupart des grands ensembles de données de modèles existants peuvent être analysés et traités en utilisant uniquement le RVB. Par conséquent, si les données existantes sont simplement modifiées en entrée RGBD, le modèle n’indexera pas activement les connaissances dans la carte de profondeur. Des tâches et une assurance qualité spécialement conçues sont nécessaires pour guider le modèle afin de comprendre la carte de profondeur et d'utiliser les informations de profondeur.
S Trois niveaux de SpatialQA, guident progressivement le modèle pour comprendre la carte de profondeur, l'utilisation des informations de profondeur Comment guider le modèle pour comprendre et utiliser les informations de profondeur, et comprendre l'espace ? L'auteur propose un jeu de données SpatialQA à trois niveaux.
Au niveau bas, guidez le modèle pour comprendre la carte de profondeur et guidez les informations directement à partir de la carte de profondeur
-
Au niveau intermédiaire, laissez le modèle aligner la profondeur avec RVB ;
Concevoir plusieurs profondeurs de haut niveau Pour les tâches connexes, 50 000 données sont annotées, permettant au modèle d'utiliser les informations de profondeur pour terminer la tâche en fonction de la compréhension de la carte de profondeur. Les tâches incluent : la relation de position spatiale, la taille de l'objet, si les objets sont en contact, la compréhension de la scène du robot, etc.
Exemple de dialogue sur Que contient Spatialbot ?
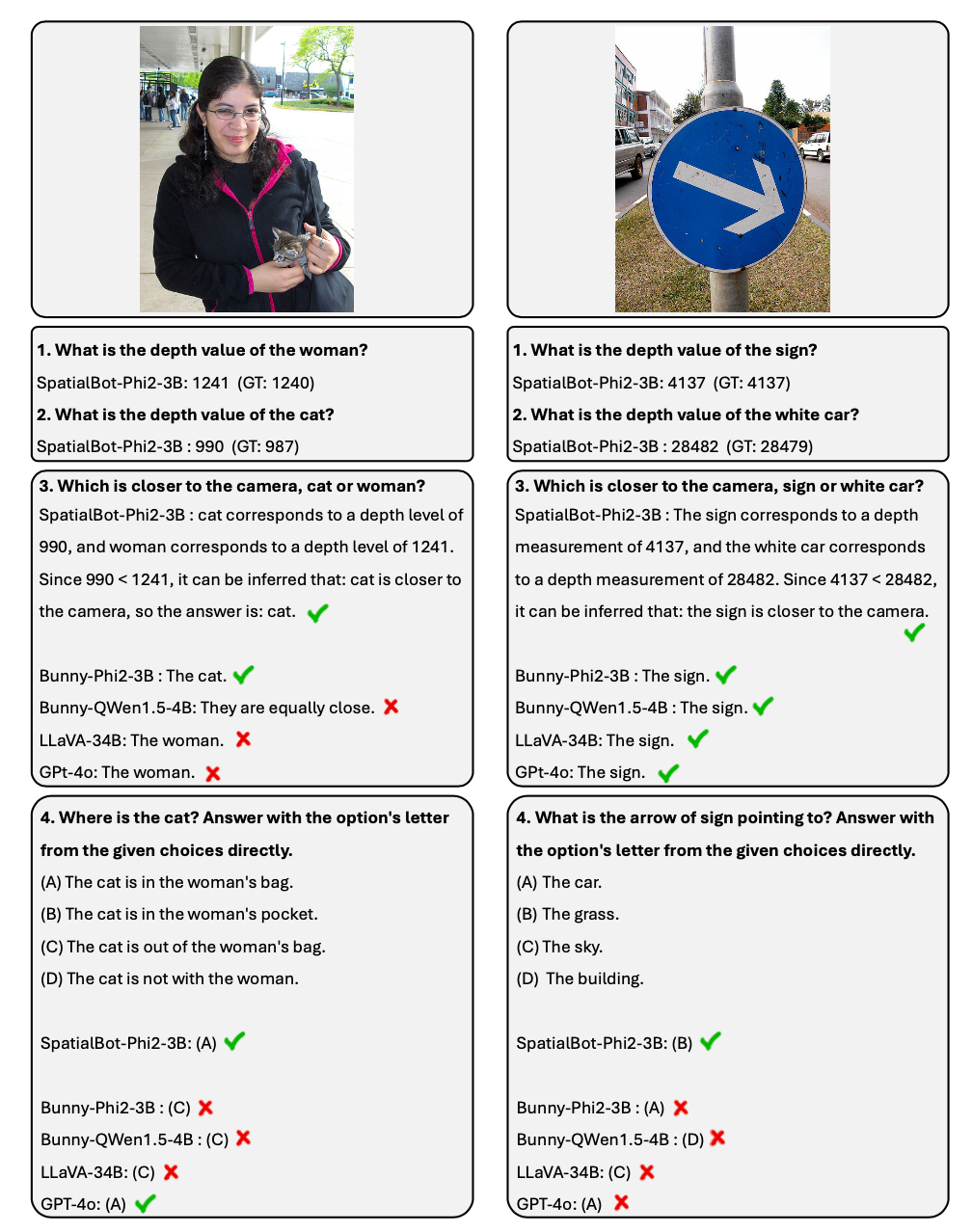
1. En s'appuyant sur les idées de l'agent, SpatialBot peut obtenir des informations de profondeur précises via l'API en cas de besoin. Il peut atteindre une précision de plus de 99 % sur des tâches telles que l'acquisition d'informations de profondeur et la comparaison de distance. 2. Pour les tâches de compréhension spatiale, l'auteur a annoncé la liste SpatialBench. Testez les capacités de compréhension approfondie du modèle grâce à un contrôle qualité soigneusement conçu et annoté. SpatialBot affiche des capacités proches de GPT-4o sur la liste. Comment le modèle comprend-il la carte de profondeur ? 1. Saisissez la carte de profondeur du modèle : Afin de prendre en compte les tâches intérieures et extérieures, une méthode d'encodage de carte de profondeur unifiée est nécessaire. Les tâches de saisie et de navigation en intérieur peuvent nécessiter une précision millimétrique. Les scènes extérieures n'ont pas besoin d'être aussi précises, mais peuvent nécessiter une plage de valeurs de profondeur supérieure à 100 mètres. L'encodage ordinal est utilisé pour l'encodage dans les tâches de vision traditionnelles, mais la valeur de l'ordinal ne peut pas être ajoutée ou soustraite. Afin de conserver autant que possible toutes les informations de profondeur, SpatialBot utilise directement la profondeur métrique en millimètres, allant de 1 mm à 131 m, en utilisant uint24 ou uint8 à trois canaux pour préserver ces valeurs. 2. Afin d'obtenir avec précision des informations de profondeur, SpatialBot appellera DepthAPI sous forme de points pour obtenir des valeurs de profondeur précises lorsqu'il le jugera nécessaire. Si vous souhaitez obtenir la profondeur d'un objet, SpatialBot réfléchira d'abord au cadre de délimitation de l'objet, puis appellera l'API en utilisant le point central du cadre de délimitation. 3. SpatialBot utilise le point central de l'objet, la profondeur moyenne, quatre valeurs maximale et minimale pour décrire la profondeur. # dans po, po, 1. SpatialBot est basé sur plusieurs LLM de base du 3B au 8B. En apprenant des connaissances spatiales dans SpatialQA, SpatialBot démontre également des améliorations significatives des performances sur les ensembles de données MLLM couramment utilisés (MME, MMBench, etc.).
2. SpatialBot a également démontré des résultats étonnants sur des tâches spécifiques telles que Open X-Embodiment et les données d'exploration du robot collectées par l'auteur. B Comment marquer les données des scénarios généraux Spatialbot
Comment marquer les données ? Questions soigneusement conçues sur la compréhension spatiale, telles que la profondeur, la relation de distance, le haut et le bas, les relations de position avant et arrière gauche et droite, les relations de taille, et incluent des questions importantes dans l'incarnation, telles que si deux objets sont dans contact.
Dans l'ensemble de test SpatialBench, les questions, les options et les réponses sont d'abord réfléchies manuellement. Afin d'augmenter la taille de l'ensemble de test, GPT est également utilisé pour l'annotation avec le même processus.
L'ensemble de formation SpatialQA comprend trois aspects :
Comprendre directement la carte de profondeur, laisser le modèle regarder la carte de profondeur, analyser la distribution de la profondeur et deviner les objets qui peuvent être inclus ;
-
Compréhension des relations spatiales et raisonnement ;
-
Compréhension des scènes de robot : décrire les scènes, les objets inclus et les tâches possibles dans Open X-Embodiment et les données du robot collectées dans cet article, et étiqueter manuellement les objets et les cadres de délimitation du robot.
Ouvrir Lorsque vous utilisez GPT pour annoter cette partie des données, GPT verra d'abord la carte de profondeur, décrira la carte de profondeur et raisonnera sur les scènes et les objets qu'elle peut contenir. Ensuite, il verra la carte RVB et filtrera la description et le raisonnement corrects. .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn




 2.
2.  Voie nécessaire vers l’intelligence incarnée, comment faire comprendre l’espace aux grands modèles ?
Voie nécessaire vers l’intelligence incarnée, comment faire comprendre l’espace aux grands modèles ?