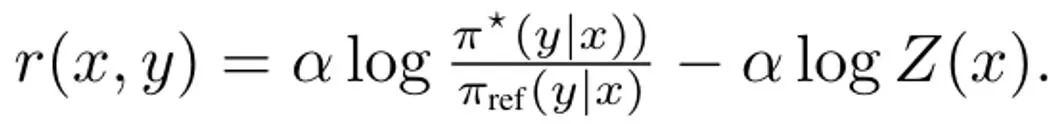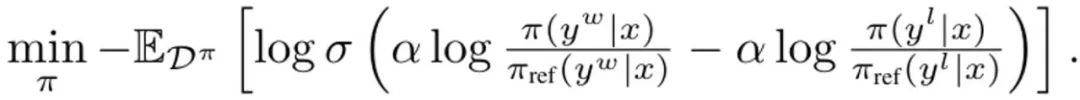Les méthodes d'éducation humaine conviennent également aux grands modèles.
Lorsqu’on élève des enfants, les gens de tous âges ont parlé d’une méthode importante : donner l’exemple. C’est-à-dire, laissez-vous être un exemple que les enfants pourront imiter et dont ils pourront apprendre, plutôt que de simplement leur dire quoi faire. Lors de la formation d'un grand modèle de langage (LLM), nous pouvons également pouvoir utiliser cette méthode - démontrer au modèle.
Récemment, l'équipe de Yang Diyi à l'Université de Stanford a proposé un nouveau framework DITTO qui peut aligner le LLM sur des paramètres spécifiques grâce à un petit nombre de démonstrations (exemples de comportement souhaité fournis par les utilisateurs). Ces exemples peuvent être obtenus à partir des journaux d'interaction existants de l'utilisateur ou en modifiant directement la sortie de LLM. Cela permet au modèle de comprendre et d'aligner efficacement les préférences des utilisateurs pour différents utilisateurs et tâches. 
- Titre de l'article : Montrer, ne pas dire : aligner les modèles de langage avec des commentaires démontrés
- Adresse de l'article : https://arxiv.org/pdf/2406.00888
DITTO peut être basé sur un petit nombre de démos (moins de 10) crée automatiquement un ensemble de données contenant un grand nombre de comparaisons de préférences (un processus appelé échafaudage) en reconnaissant tacitement que les utilisateurs préfèrent le LLM à la sortie du LLM d'origine et des itérations antérieures. . Ensuite, la démonstration et les résultats du modèle sont combinés en paires de données pour obtenir un ensemble de données amélioré. Le modèle de langage peut ensuite être mis à jour à l'aide d'algorithmes d'alignement tels que DPO. De plus, l'équipe a également découvert que DITTO peut être considéré comme un algorithme d'apprentissage par imitation en ligne, dans lequel les données échantillonnées à partir du LLM sont utilisées pour distinguer le comportement des experts. De ce point de vue, l’équipe a démontré que DITTO peut atteindre des performances supérieures à celles d’un expert grâce à l’extrapolation. L'équipe a également vérifié l'effet de DITTO à travers des expériences. Pour aligner LLM, les méthodes précédentes nécessitent souvent l'utilisation de milliers de paires de données de comparaison, tandis que DITTO peut modifier le comportement du modèle avec seulement quelques démonstrations. Cette adaptation rapide et peu coûteuse a été rendue possible principalement grâce à la vision fondamentale de l’équipe : les données de comparaison en ligne sont facilement disponibles via des démonstrations.
Le modèle de langage peut être considéré comme une politique π(y|x), qui aboutit à une distribution de l'invite x et du résultat d'achèvement y. L'objectif de RLHF est de former un LLM pour maximiser une fonction de récompense r (x, y) qui évalue la qualité de la paire de résultats d'achèvement rapide (x, y). Généralement, une divergence KL est également ajoutée pour empêcher le modèle mis à jour de s'écarter trop du modèle de langage de base (π_ref). Globalement, les objectifs d'optimisation de la méthode RLHF sont :
Il s'agit de maximiser la récompense attendue sur la distribution rapide p, qui est affectée par la contrainte KL régulée par α. En règle générale, l'objectif d'optimisation utilise un ensemble de données de comparaison de la forme {(x, y^w, y^l )}, où le résultat d'achèvement "gagnant" y^w est meilleur que le résultat d'achèvement "perdant" y ^l, enregistré sous la forme y^w ⪰ y^l. De plus, nous marquons ici le petit ensemble de données de démonstration d'experts comme D_E et supposons que ces démonstrations sont générées par la politique experte π_E, qui peut maximiser la récompense de prédiction. DITTO peut utiliser directement les résultats du modèle de langage et les démonstrations d'experts pour générer des données de comparaison. Autrement dit, contrairement aux paradigmes génératifs pour les données synthétiques, DITTO ne nécessite pas un modèle déjà performant pour une tâche donnée. L'idée clé de DITTO est que le modèle de langage lui-même, associé à des démonstrations d'experts, peut conduire à un ensemble de données comparatives pour l'alignement, ce qui élimine le besoin de collecter de grandes quantités de données de préférences par paires. . Il en résulte une cible de type contrastée où les démonstrations d'experts sont des exemples positifs. Générer une comparaison. Supposons que nous échantillonnions un résultat d'achèvement y^E ∼ π_E (・|x) de la politique experte. On peut alors considérer que les récompenses correspondant aux échantillons échantillonnés dans d’autres politiques π sont inférieures ou égales aux récompenses des échantillons échantillonnés dans π_E. Sur la base de cette observation, l'équipe a construit des données comparatives (x, y^E, y^π ), où y^E ⪰ y^π. Bien que ces données comparatives proviennent de stratégies plutôt que d’échantillons individuels, des recherches antérieures ont démontré l’efficacité de cette approche. Une approche naturelle pour DITTO consiste à utiliser cet ensemble de données et un algorithme RLHF facilement disponible pour optimiser (1). Cela améliore la probabilité des réponses d'experts tout en réduisant la probabilité de l'échantillon du modèle actuel, contrairement aux méthodes de réglage fin standard qui ne font que la première. L’essentiel est qu’en utilisant des échantillons de π, un ensemble de données de préférences illimitées peut être construit avec un petit nombre de démonstrations. Cependant, l’équipe a constaté que cela pourrait être encore mieux fait en prenant en compte les aspects temporels du processus d’apprentissage. De la comparaison au classement. Utiliser uniquement des données comparatives provenant d’experts et une seule politique π peut ne pas suffire pour obtenir de bonnes performances. Cela ne fera que réduire la probabilité d'un π particulier, conduisant à des problèmes de surajustement - qui nuisent également à SFT avec peu de données. L'équipe propose qu'il soit également possible de considérer les données générées par toutes les politiques apprises au fil du temps au cours du RLHF, de manière similaire à la relecture dans l'apprentissage par renforcement. Soit la stratégie initiale du premier tour d'itération soit π_0. Un ensemble de données D_0 est obtenu en échantillonnant cette stratégie. Un ensemble de données comparatives pour le RLHF peut ensuite être généré sur cette base, qui peut être noté D_E ⪰ D_0. En utilisant ces données de comparaison dérivées, π_0 peut être mis à jour pour donner π_1. Par définition, est également valable. Après cela, continuez à utiliser π_1 pour générer des données de comparaison, et D_E ⪰ D_1. Poursuivez ce processus, en générant continuellement des données de comparaison de plus en plus diversifiées en utilisant toutes les stratégies précédentes. L’équipe appelle ces comparaisons « comparaisons de rediffusion ». Bien que cette méthode ait du sens en théorie, si D_E est petit, un surapprentissage peut se produire. Cependant, des comparaisons entre politiques peuvent également être envisagées lors de la formation si l’on suppose que la politique s’améliorera après chaque itération. Contrairement à la comparaison avec les experts, nous ne pouvons pas garantir que la stratégie sera meilleure après chaque itération, mais l'équipe a constaté que le modèle global s'améliore encore après chaque itération. Cela peut être dû à la fois à la modélisation des récompenses et à (1) sa convexité. De cette manière, les données de comparaison peuvent être échantillonnées selon le classement suivant :
En ajoutant ces données de comparaison "inter-modèle" et "replay", l'effet obtenu est que la probabilité d'échantillons précoces (tels que le les échantillons dans D_1) seront plus élevés que les plus récents (comme dans D_t), appuyez plus bas, lissant ainsi l'image de récompense implicite. Dans la mise en œuvre pratique, l'approche de l'équipe consiste non seulement à utiliser des données de comparaison avec des experts, mais également à regrouper certaines données de comparaison entre ces modèles. Un algorithme pratique. En pratique, l'algorithme DITTO est un processus itératif composé de trois composants simples, comme le montre l'algorithme 1.
Tout d’abord, effectuez un réglage fin supervisé sur l’ensemble de démonstration expert, en effectuant un nombre limité d’étapes de dégradé. Soit la politique initiale π_0. Deuxième étape, comparaison d'échantillons de données : lors de l'entraînement, pour chacune des N démonstrations dans D_E, un nouvel ensemble de données D_t est construit en échantillonnant M résultats de complétion à partir de π_t, ils sont ensuite ajoutés au classement selon stratégie (2). Lors de l'échantillonnage des données de comparaison de l'équation (2), chaque lot B se compose de 70 % de données de comparaison « en ligne » D_E ⪰ D_t et de 20 % de données de comparaison « replay » D_E ⪰ D_{i
où σ est la fonction logistique de le modèle de préférence Bradley-Terry. Lors de chaque mise à jour, le modèle de référence issu de la stratégie SFT n'est pas mis à jour pour éviter de trop s'écarter de l'initialisation. Dériver DITTO vers un apprentissage par imitation en ligne DITTO peut être dérivé d'une perspective d'apprentissage par imitation en ligne, où une combinaison de démonstrations d'experts et de données en ligne sont utilisées pour apprendre simultanément la fonction et la politique de récompense. Plus précisément, le joueur stratégique maximise la récompense attendue ? (π, r), tandis que le joueur récompensant minimise la perte min_r L (D^π, r) sur l'ensemble de données en ligne D^π. utilisez l'objectif politique de (1) et la perte de modélisation de récompense standard pour instancier le problème d'optimisation :
En dérivant DITTO, la première étape de la simplification (3) consiste à résoudre ses problèmes de politique interne maximale. Heureusement, l'équipe a découvert, sur la base de recherches antérieures, que l'objectif politique ?_KL a une solution fermée de la forme où Z (x) est la fonction de partition de la distribution normalisée. Cela crée notamment une relation bijective entre la politique et la fonction de récompense, qui peut être utilisée pour éliminer les optimisations internes. En réorganisant cette solution, la fonction de récompense peut s'écrire comme suit : De plus, des recherches antérieures ont montré que cette reparamétrage peut représenter des fonctions de récompense arbitraires. Par conséquent, en la substituant dans l'équation (3), la variable r peut être transformée en π, obtenant ainsi l'objectif Idem : Veuillez noter que, comme pour DPO, la fonction de récompense est estimée ici implicitement. La différence avec DPO est que DITTO s'appuie sur un ensemble de données de préférences en ligne D^π. Pourquoi DITTO est-il meilleur que simplement utiliser SFT ? L'une des raisons pour lesquelles DITTO fonctionne mieux est qu'il utilise beaucoup plus de données que SFT en générant des données de comparaison. Une autre raison est que dans certains cas, les méthodes d’apprentissage par imitation en ligne sont plus performantes que les présentateurs, alors que SFT ne peut qu’imiter des démonstrations. L'équipe a également mené des recherches empiriques pour prouver l'efficacité de DITTO. Veuillez vous référer à l'article original pour les paramètres spécifiques de l'expérience. Nous nous concentrons ici uniquement sur les résultats expérimentaux. Résultats de recherche basés sur des benchmarks statiques L'évaluation des benchmarks statiques a utilisé GPT-4, et les résultats sont présentés dans le tableau 1.
Im Durchschnitt übertrifft DITTO alle anderen Methoden: 71,67 % durchschnittliche Gewinnrate bei CMCC, 82,50 % durchschnittliche Gewinnrate bei CCAT50; Bei CCAT50 konnte DITTO von allen Autoren nur in einem von ihnen nicht den Gesamtsieg erringen. Bei CMCC übertrifft DITTO für alle Autoren die Hälfte der Benchmarks auf ganzer Linie, gefolgt von wenigen Treffern mit einem Vorsprung von 30 %. Obwohl SFT eine gute Leistung erbrachte, verbesserte DITTO im Vergleich dazu seine durchschnittliche Gewinnrate um 11,7 %. Benutzerstudie: Testen der Fähigkeit zur Generalisierung auf natürliche AufgabenInsgesamt stimmen die Ergebnisse der Benutzerstudie mit den Ergebnissen statischer Benchmarks überein. DITTO übertrifft die kontrastierenden Methoden in Bezug auf die Präferenz für ausgerichtete Demos, wie in Tabelle 2 gezeigt: wobei DITTO (72,1 % Gewinnrate) > SFT (60,1 %) > wenige Schüsse (48,1 %) > selbstgesteuert (44,2 %) > Nullschuss (25,0 %).
Vor der Verwendung von DITTO müssen Benutzer einige Voraussetzungen berücksichtigen, von der Anzahl der Demos bis hin zur Anzahl der Negativbeispiele, die aus dem Sprachmodell entnommen werden müssen. Das Team untersuchte die Auswirkungen dieser Entscheidungen und konzentrierte sich auf CMCC, da es mehr Missionen abdeckt als CCAT. Darüber hinaus analysierten sie die Stichprobeneffizienz der Demonstration im Vergleich zum gepaarten Feedback. Das Team führte Ablationsstudien an Komponenten von DITTO durch. Wie in Abbildung 2 (links) gezeigt, kann eine Erhöhung der Anzahl der Iterationen von DITTO normalerweise die Leistung verbessern.
Es ist ersichtlich, dass die von GPT-4 bewertete Gewinnquote um 31,5 % steigt, wenn die Anzahl der Iterationen von 1 auf 4 erhöht wird. Diese Verbesserung ist nicht monoton – bei Iteration 2 nimmt die Leistung leicht ab (-3,4 %). Dies liegt daran, dass frühe Iterationen möglicherweise zu verrauschteren Samples führen und somit die Leistung verringern. Andererseits verbessert sich, wie in Abbildung 2 (Mitte) dargestellt, die DITTO-Leistung monoton, wenn die Anzahl der negativen Beispiele erhöht wird. Darüber hinaus nimmt die Varianz der DITTO-Leistung ab, je mehr negative Beispiele erfasst werden.
Außerdem ergaben Ablationsstudien zu DITTO, wie in Tabelle 3 gezeigt, dass die Entfernung einer seiner Komponenten zu einer Leistungsverschlechterung führte. Wenn Sie beispielsweise auf die iterative Online-Stichprobe verzichten, sinkt die Gewinnquote im Vergleich zur Verwendung von DITTO von 70,1 % auf 57,3 %. Und wenn π_ref während des Online-Prozesses kontinuierlich aktualisiert wird, führt dies zu einem erheblichen Leistungsabfall: von 70,1 % auf 45,8 %. Das Team vermutet, dass der Grund darin liegt, dass die Aktualisierung von π_ref zu einer Überanpassung führen könnte. Schließlich können wir in Tabelle 3 auch die Bedeutung von Wiederholungs- und Inter-Strategie-Vergleichsdaten erkennen. Einer der Hauptvorteile von DITTO ist seine Probeneffizienz. Das Team hat dies ausgewertet und die Ergebnisse sind in Abbildung 2 (rechts) dargestellt. Hier werden wiederum normalisierte Gewinnraten angegeben. Zunächst können Sie sehen, dass die Gewinnquote von DITTO zu Beginn schnell ansteigt. Wenn die Anzahl der Demos von 1 auf 3 steigt, verbessert sich die normalisierte Leistung mit jeder Erhöhung erheblich (0 % → 5 % → 11,9 %). Wenn jedoch die Anzahl der Demos weiter zunimmt, nimmt die Umsatzsteigerung ab (11,9 % → 15,39 % bei einer Erhöhung von 4 auf 7), was zeigt, dass mit zunehmender Anzahl der Demos die Leistung von DITTO gesättigt sein wird. Darüber hinaus spekuliert das Team, dass sich nicht nur die Anzahl der Demonstrationen auf die Leistung von DITTO, sondern auch auf die Qualität der Demonstrationen auswirken wird, dies bleibt jedoch zukünftiger Forschung überlassen. Wie ist die paarweise Präferenz im Vergleich zur Demo? Eine Kernannahme von DITTO ist, dass die Probeneffizienz durch Demonstration entsteht. Theoretisch kann ein ähnlicher Effekt erzielt werden, indem viele Paare von Präferenzdaten mit Anmerkungen versehen werden, wenn der Benutzer eine perfekte Reihe von Demonstrationen im Sinn hat. Das Team führte ein detailliertes Experiment durch, bei dem es sich um Stichproben von Compliance Mistral 7B handelte, und ließ 500 Präferenzdatenpaare auch von einem der Autoren kommentieren, der eine Demo der Benutzerstudie bereitstellte. Zusammenfassend haben sie einen paarweisen Präferenzdatensatz D_pref = {(x, y^i , y^j )} erstellt, wobei y^i ≻ y^j ist. Anschließend berechneten sie die Gewinnquote für 20 Ergebnispaare, die aus zwei Modellen entnommen wurden – eines wurde auf 4 Demos mit DITTO trainiert, das andere auf {0...500} Präferenzdatenpaaren, die nur DPO nutzten.
Wenn paarweise Präferenzdaten nur aus π_ref abgetastet werden, kann beobachtet werden, dass die generierten Datenpaare außerhalb der gezeigten Verteilung liegen – die paarweisen Präferenzen beinhalten nicht das vom Benutzer gezeigte Verhalten (Ergebnisse für die Basisrichtlinie in Abbildung 3, blaue Farbe). Selbst als sie π_ref mithilfe von Benutzerdemonstrationen verfeinerten, waren immer noch mehr als 500 Präferenzdatenpaare erforderlich, um die Leistung von DITTO zu erreichen (Ergebnisse für die durch Demo verfeinerte Richtlinie in Abbildung 3, orange). Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn





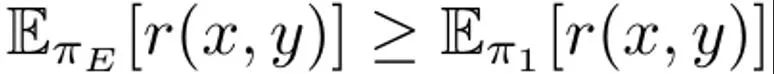 est également valable. Après cela, continuez à utiliser π_1 pour générer des données de comparaison, et D_E ⪰ D_1. Poursuivez ce processus, en générant continuellement des données de comparaison de plus en plus diversifiées en utilisant toutes les stratégies précédentes. L’équipe appelle ces comparaisons « comparaisons de rediffusion ».
est également valable. Après cela, continuez à utiliser π_1 pour générer des données de comparaison, et D_E ⪰ D_1. Poursuivez ce processus, en générant continuellement des données de comparaison de plus en plus diversifiées en utilisant toutes les stratégies précédentes. L’équipe appelle ces comparaisons « comparaisons de rediffusion ».